Ai Overview
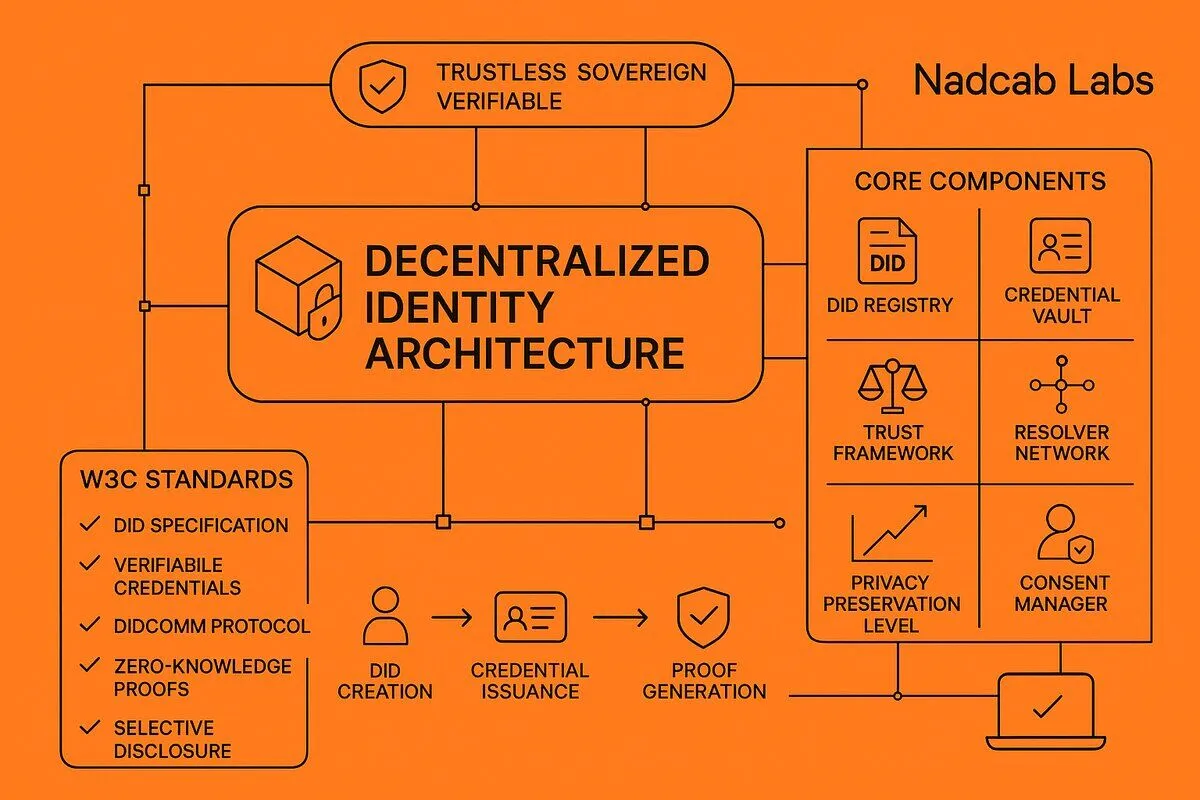
A DID resolver implementation is the technical infrastructure that translates decentralized identifiers into actionable identity documents containing cryptographic verification methods and service endpoints. This resolution process forms the backbone of every self-sovereign identity interaction, enabling verifiers to discover public keys, authentication protocols, and communication channels without relying on centralized registries.
A DID resolver implementation is the technical infrastructure that translates decentralized identifiers into actionable identity documents containing cryptographic verification methods and service endpoints. This resolution process forms the backbone of every self-sovereign identity interaction, enabling verifiers to discover public keys, authentication protocols, and communication channels without relying on centralized registries. Implementing a production-grade resolver requires understanding universal resolver architecture, method-specific driver development patterns, and blockchain interaction strategies that balance performance with decentralization guarantees.
Key Takeaways
- DID resolvers bridge decentralized identifiers to usable identity documents through standardized resolution algorithms that query blockchain networks and distributed ledgers
- Universal resolver architecture enables multi-method support through pluggable driver interfaces, allowing single deployments to handle did:ethr, did:ion, did:key, and other method types simultaneously
- Method-specific driver implementation involves DID syntax parsing, blockchain query optimization, and DID document construction from raw ledger data with proper cryptographic key encoding
- Production resolvers require horizontal scaling patterns, distributed caching layers, and robust blockchain node infrastructure to maintain sub-second resolution times under high throughput
- Resolution metadata handling, versioning support, and deactivation detection mechanisms ensure resolvers provide accurate identity state across the full DID lifecycle
- Operational monitoring tracking resolution latency, cache hit ratios, and method-specific error rates enables teams to optimize resolver performance and reliability
What Is a DID Resolver and How Does It Enable Decentralized Identity Systems?
A DID resolver performs the fundamental operation of converting a decentralized identifier string into a structured DID document that contains all the cryptographic material and metadata needed for identity interactions. When an application encounters a DID like did:ethr:0x1234...abcd, the resolver interprets the method identifier (ethr), queries the appropriate blockchain network (Ethereum mainnet in this case), retrieves the on-chain identity registry data, and constructs a standards-compliant JSON-LD document containing public keys, authentication methods, and service endpoints. This resolution process happens transparently behind identity wallets, credential verifiers, and authentication systems that need to validate signatures or establish secure communication channels.
The distinction between universal resolvers and method-specific resolvers shapes architectural decisions throughout Blockchain Identity Management system design. A universal resolver implements a driver-based architecture that supports multiple DID methods through pluggable modules, allowing a single deployment to resolve did:ethr identifiers from Ethereum, did:ion identifiers from the ION network on Bitcoin, and did:key identifiers from embedded cryptographic material without method-specific configuration. Method-specific resolvers optimize for single-method performance, embedding blockchain client logic directly and eliminating driver abstraction overhead. Organizations building public identity infrastructure typically deploy universal resolvers to maximize interoperability, while enterprises with standardized internal DID methods often choose method-specific implementations for reduced operational complexity and tighter integration with private blockchain networks.
Resolvers function as the critical infrastructure layer connecting identity controllers who create and manage DIDs, verifiers who need to validate credentials and authenticate users, and the underlying blockchain networks that store identity state. When a verifier receives a verifiable credential signed by did:example:alice, the resolver retrieves Alice’s DID document to obtain her current public key, checks that the key hasn’t been revoked through on-chain registry queries, and returns verification methods that the verifier uses to validate the credential signature. This architecture eliminates centralized certificate authorities and directory services, replacing them with cryptographically-secured blockchain queries that provide tamper-proof identity lookups. The resolver’s ability to translate arbitrary DID strings into actionable identity documents enables the full self-sovereign identity ecosystem to function without introducing trust dependencies on identity providers or directory operators.
Resolution metadata accompanies every DID document retrieval, providing verifiers with context about the resolution process itself. Metadata includes timestamps indicating when the document was retrieved, content integrity hashes proving the document hasn’t been tampered with during transmission, and error codes signaling issues like network failures or deactivated identifiers. This metadata layer allows verifiers to make informed trust decisions, understanding whether they’re working with fresh identity data or cached documents that might be stale. The W3C DID Core specification defines standardized metadata properties that all resolvers must support, ensuring consistent behavior across different implementations and DID methods.
How Does Universal Resolver Architecture Support Multiple DID Methods?
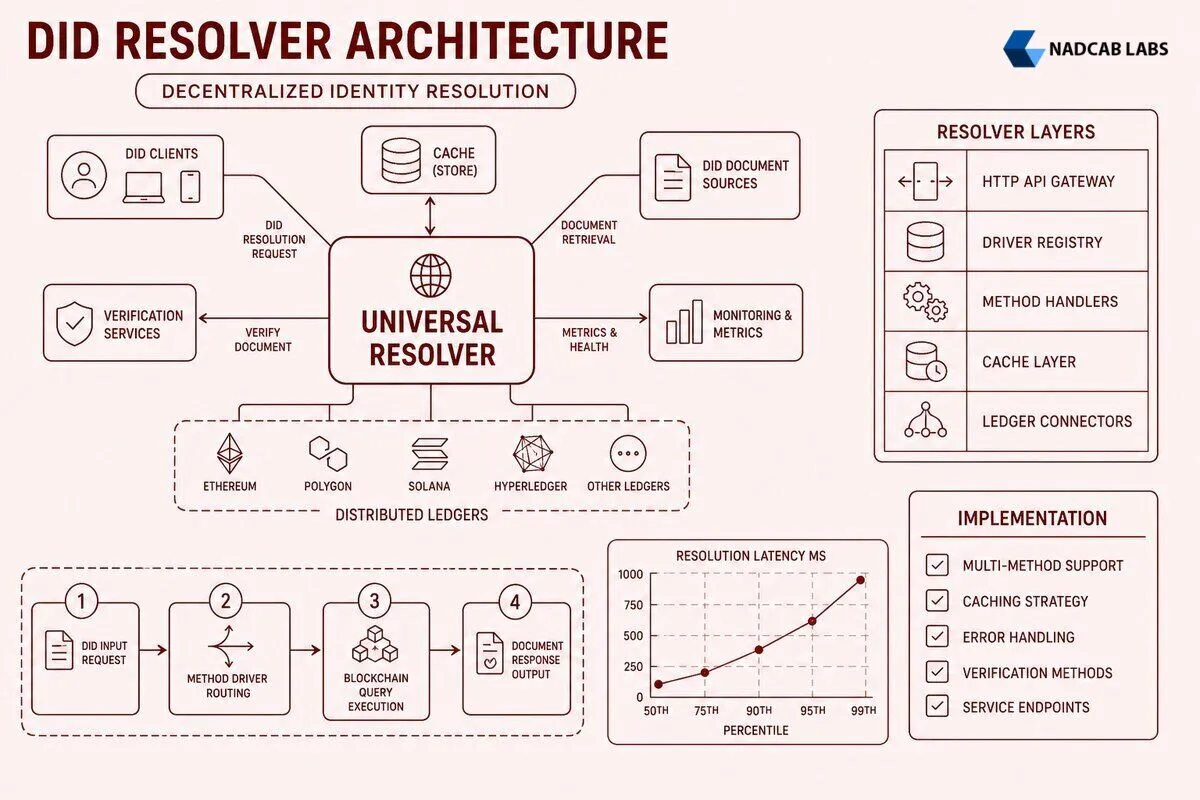
Universal resolver architecture centers on a modular driver framework where each DID method implements a standardized interface that the core resolver orchestrates. The core resolver receives resolution requests containing DIDs and resolution options, parses the method identifier from the DID string, routes the request to the appropriate method driver, and aggregates the driver’s response into a standardized resolution result. Drivers encapsulate all method-specific logic including blockchain client initialization, network parameter configuration, and DID document construction rules specific to each method’s registry design. This separation allows teams to add support for new DID methods by implementing a single driver interface without modifying the universal resolver core, enabling resolver deployments to evolve as the DID ecosystem introduces new methods and blockchain platforms.
The driver interface defines three primary operations that every method implementation must support: resolve (retrieve current DID document), resolveRepresentation (retrieve document in specific serialization format), and dereference (resolve specific resources within a DID document like individual keys or service endpoints). Each operation accepts a DID string and resolution options object containing parameters like accept headers for content negotiation, versionId for historical document retrieval, and network identifiers for method-specific blockchain selection. Drivers return standardized resolution result objects containing the DID document, resolution metadata, and optional document metadata, ensuring consistent response structures regardless of the underlying blockchain architecture. This interface standardization enables client applications to interact with any DID method through identical API calls, abstracting away the complexity of heterogeneous blockchain protocols and registry designs.
Universal Resolver Request Flow
did:ethr:0x123Extract “ethr”
Load ethr driver
Ethereum RPC
Construct JSON-LD
Return DID doc
Resolution metadata handling across heterogeneous DID methods requires careful normalization to ensure clients receive consistent information regardless of which blockchain network provided the underlying data. Different methods expose varying levels of detail in their resolution metadata—some provide block numbers and transaction hashes for on-chain operations, while others offer only basic timestamps and content hashes. The universal resolver normalizes this metadata into a common structure while preserving method-specific extensions in a dedicated namespace, allowing clients to access standardized fields like created and updated timestamps while still retrieving Ethereum-specific transaction hashes when working with did:ethr identifiers. This approach balances interoperability with the need to expose method-specific details that advanced clients may require for audit trails or compliance verification.
Caching strategies in universal resolvers must account for the different consistency guarantees and update patterns across DID methods. Methods built on proof-of-work blockchains like Bitcoin require longer cache TTLs to account for block confirmation times and potential chain reorganizations, while methods using instant-finality consensus can support shorter TTLs with stronger freshness guarantees. The resolver implements a tiered caching architecture where frequently-accessed DIDs populate an in-memory cache with sub-millisecond lookup times, moderately-accessed DIDs live in a distributed Redis layer with single-digit millisecond latency, and cold DIDs trigger full blockchain queries. Cache invalidation events propagate through a pub-sub mechanism that monitors blockchain networks for DID document update transactions, proactively clearing stale cache entries when identity controllers modify their on-chain identity records.
HTTP binding specifications define how universal resolvers expose resolution services to client applications through RESTful APIs. The standard binding maps DID resolution operations to HTTP GET requests where the DID appears as a path parameter and resolution options encode as query parameters or HTTP headers. A request to GET /identifiers/did:ethr:0x1234...abcd triggers resolution of the specified DID, returning a JSON response containing the DID document, resolution metadata, and appropriate HTTP status codes. Content negotiation through Accept headers allows clients to request specific DID document representations like JSON-LD, CBOR, or JSON, with the resolver invoking the appropriate driver serialization method. This HTTP binding enables identity wallets and verification systems to integrate DID resolution through standard HTTP client libraries without implementing blockchain-specific protocols, significantly lowering the barrier to adopting decentralized identity infrastructure similar to patterns seen in RPA architecture design patterns that prioritize integration simplicity.
| Resolver Component | Function | Performance Impact |
|---|---|---|
| Method Parser | Extracts method identifier from DID string using regex patterns | Negligible (<1ms) – pure string processing |
| Driver Router | Maps method to appropriate driver instance and handles driver lifecycle | Minimal (<5ms) – hash table lookup and object instantiation |
| Cache Layer | Stores resolved documents with TTL-based expiration and invalidation events | High impact – 95%+ cache hit rate reduces resolution time from 200ms to 2ms |
| Blockchain Client | Executes RPC calls to blockchain nodes for registry data retrieval | Dominant factor – 150-300ms for Ethereum, 50-100ms for faster chains |
| Document Builder | Constructs JSON-LD from raw blockchain data with cryptographic key encoding | Moderate (10-20ms) – JSON serialization and cryptographic transformations |
| Metadata Aggregator | Normalizes method-specific metadata into standardized resolution metadata | Minimal (<5ms) – field mapping and timestamp formatting |
What Are the Key Steps in Implementing a Method-Specific DID Driver?
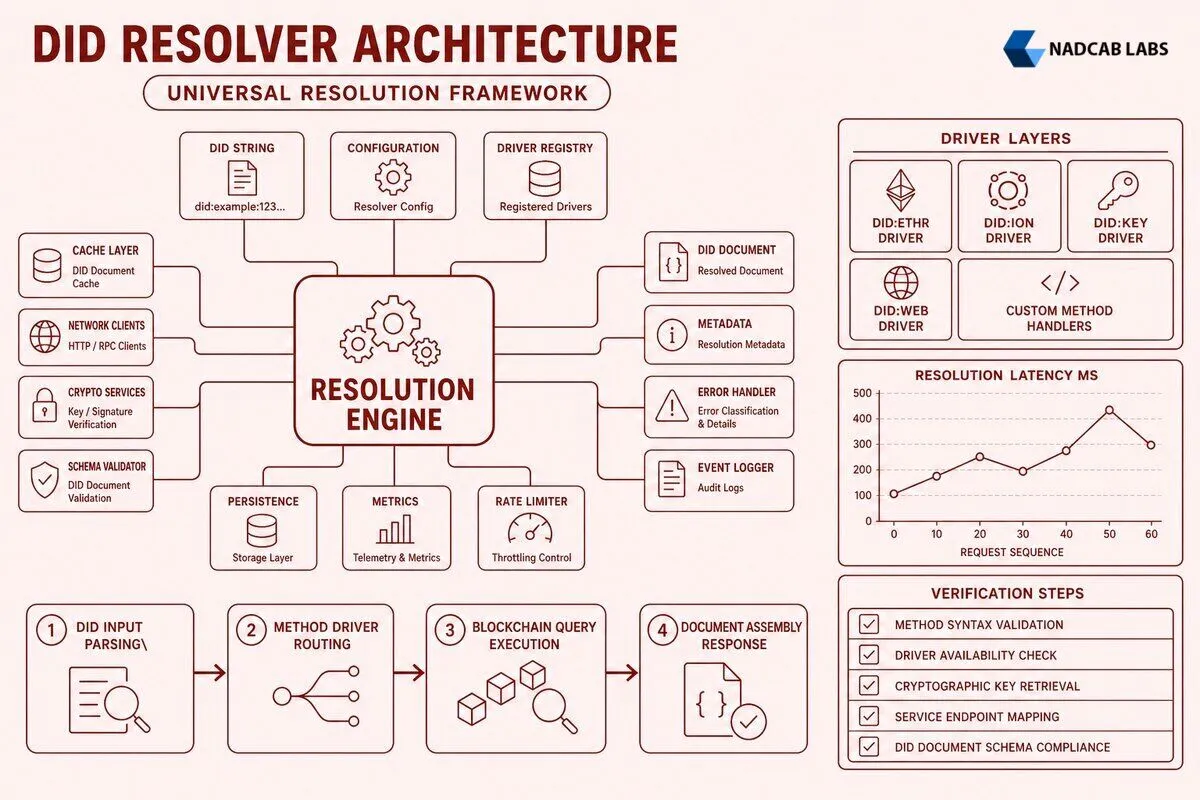
Method-specific driver implementation begins with parsing the DID syntax according to the method’s grammar rules defined in its specification document. Each DID method defines a unique syntax structure beyond the common did:method:method-specific-id format, encoding information like blockchain network identifiers, smart contract addresses, or cryptographic key fingerprints within the method-specific portion. The did:ethr method embeds Ethereum addresses or public key hashes, while did:ion encodes IPFS content identifiers pointing to DID document data stored on the ION network. The parser validates that the DID conforms to the method’s grammar using regular expressions or formal grammar parsers, extracts network parameters that determine which blockchain network to query, and converts the method-specific identifier into the format required for registry lookups. Robust parsing includes error handling for malformed DIDs, returning standardized error codes that clients can interpret consistently across different method implementations.
The blockchain interaction layer forms the core of method-specific drivers, implementing the protocol-specific logic needed to query on-chain DID registries and retrieve identity data. For methods using smart contract registries like did:ethr, the driver initializes a Web3 client connected to an Ethereum node, constructs contract call transactions targeting the registry’s getter functions, and decodes the returned ABI-encoded data into usable identity attributes. Methods built on UTXO-based blockchains like did:btcr require different interaction patterns, parsing Bitcoin transactions that embed DID document updates in OP_RETURN outputs and following chain references to reconstruct the current identity state. The driver must handle blockchain-specific failure modes including network partitions, node synchronization delays, and transaction confirmation requirements, implementing retry logic with exponential backoff and circuit breakers that prevent cascading failures when blockchain nodes become temporarily unavailable.
Gas optimization strategies become critical for methods that require on-chain transactions during resolution, though most DID methods design registries to support read-only resolution without transaction costs. For methods that do require transactions, drivers implement batching patterns that group multiple resolution requests into single blockchain queries, reducing per-resolution gas costs by amortizing transaction overhead across multiple DIDs. Connection pooling maintains persistent connections to blockchain RPC endpoints, eliminating the overhead of establishing new connections for each resolution request. Rate limiting prevents drivers from overwhelming blockchain nodes with excessive query traffic, implementing token bucket algorithms that smooth request patterns and respect node operator rate limits. These optimizations prove essential when resolvers handle high-throughput workloads similar to those encountered in microservices architecture for NFT games where identity resolution occurs on every player authentication and item transfer operation.
DID document construction transforms raw blockchain data into standards-compliant JSON-LD documents containing verification methods, authentication relationships, and service endpoints. The driver reads public keys from the blockchain registry, encodes them in the appropriate format (typically as JWK or base58 multibase strings), and constructs verification method objects that specify key type, controller, and cryptographic material. Authentication and assertion method arrays reference these verification methods by ID, indicating which keys the identity controller can use for different purposes. Service endpoints embed URLs for communication protocols like DIDComm messaging or credential exchange endpoints, allowing verifiers to discover how to interact with the identity controller beyond simple signature verification. The document builder ensures all JSON-LD context references are valid, includes required metadata fields like document creation and update timestamps, and validates the final document against the DID Core data model schema before returning it to the universal resolver core.
Method Driver Resolution Process
Input:
did:ethr:mainnet:0x1234abcdExtract method=”ethr”, network=”mainnet”, address=”0x1234abcd”
Load Ethereum mainnet RPC endpoint from configuration
Initialize Web3 client with connection pooling enabled
Call ERC1056 registry contract:
identityOwner(0x1234abcd)Retrieve public keys, delegates, and attributes from events
Construct verification methods from retrieved keys
Build service endpoints from attribute events
Add metadata (created, updated timestamps)
Validate JSON-LD structure against DID Core schema
Return DID document + resolution metadata to caller
Error handling patterns in method drivers distinguish between transient failures that warrant retry attempts and permanent failures that should return immediately. Network timeouts and temporary node unavailability represent transient errors where the driver implements exponential backoff retry logic, attempting the blockchain query multiple times with increasing delays between attempts. Permanent errors like invalid DID syntax, deactivated identifiers, or non-existent registry entries return immediately with appropriate error codes, avoiding wasted retry attempts that cannot succeed. The driver propagates detailed error information through resolution metadata, including error codes defined in the DID Resolution specification, human-readable error messages, and method-specific diagnostic information that helps operators troubleshoot resolution failures. This error taxonomy enables client applications to implement appropriate error handling logic, distinguishing between errors that suggest retrying the resolution attempt and errors that indicate the DID cannot be resolved.
How Do DID Resolution Algorithms Handle Versioning and Deactivation?
Version-specific resolution enables verifiers to retrieve historical states of DID documents, supporting use cases like verifying credentials that were issued against older versions of an identity’s public keys or auditing the evolution of an identity’s configuration over time. The DID Core specification defines two versioning parameters: versionId for retrieving specific document versions by identifier, and versionTime for retrieving the document state as it existed at a particular timestamp. Method drivers implement versioning by querying blockchain history, retrieving the registry state at specific block heights or transaction timestamps that correspond to the requested version. For methods using event-sourced registries where DID documents are reconstructed from a sequence of update events, the driver replays events up to the specified version point and constructs the document from the resulting state. This historical resolution capability proves essential in HIPAA compliant blockchain architecture where audit trails must demonstrate which identity attributes were active when specific healthcare data access occurred.
Deactivation detection mechanisms identify when identity controllers have permanently disabled their decentralized identifiers, signaling that associated credentials should no longer be trusted and authentication attempts should fail. Different DID methods implement deactivation through varying on-chain patterns. Some methods use explicit deactivation flags in smart contract registries, where identity controllers call a deactivate function that sets a boolean flag indicating the DID is no longer active. Other methods employ tombstone records—special registry entries that mark the DID as deactivated while preserving minimal metadata about when deactivation occurred and who initiated it. Methods without explicit deactivation support may rely on metadata signaling patterns where the absence of any active keys in the DID document implicitly indicates deactivation. The resolver driver checks these method-specific deactivation indicators during every resolution attempt, setting the deactivated property in resolution metadata to true when deactivation is detected and returning an empty or minimal DID document that prevents successful verification operations.
| Deactivation Pattern | Implementation Method | Detection Reliability |
|---|---|---|
| Explicit Flag | Smart contract boolean field set via deactivate() function | 100% – unambiguous on-chain state |
| Tombstone Record | Special registry entry with deactivation timestamp and reason | 100% – explicit deactivation event |
| Key Removal | DID document contains zero verification methods | 95% – could indicate temporary state during key rotation |
| Transfer to Null Address | Registry ownership transferred to 0x0000…0000 address | 100% – irreversible ownership burn |
| TTL Expiration | Document includes expiration timestamp, now past | 90% – controller may have intended renewal |
Caching invalidation strategies for versioned and deactivated DIDs require careful consideration to balance performance with accuracy guarantees. Resolvers typically implement aggressive caching for historical versions since past document states are immutable—once a versionId or versionTime resolves to a specific document, that result will never change and can be cached indefinitely. Current document resolution requires more conservative caching with TTLs calibrated to the method’s expected update frequency and the application’s tolerance for stale data. High-security applications like financial services may require TTLs measured in seconds to minimize the window where cached documents diverge from on-chain state, while lower-stakes applications can use minute or hour-scale TTLs to maximize cache hit rates. Deactivation events trigger immediate cache invalidation through blockchain monitoring systems that watch for deactivation transactions and proactively clear affected cache entries, ensuring resolvers never return cached documents for DIDs that have been deactivated since the cache entry was populated.
The resolution algorithm’s handling of deactivated identifiers extends beyond simply detecting deactivation to providing verifiers with sufficient context to understand the deactivation’s implications. Resolution metadata includes a deactivation timestamp indicating when the identity was disabled, allowing verifiers to determine whether credentials issued before deactivation should still be trusted. Some methods support deactivation reasons encoded in on-chain metadata, enabling identity controllers to signal whether deactivation resulted from key compromise (credentials should be immediately distrusted) versus planned identity migration (credentials may remain valid if re-issued against the new DID). This nuanced deactivation handling enables verifiers to implement sophisticated trust policies that account for the circumstances of identity deactivation rather than treating all deactivations as equivalent security events.
Cache Performance by Resolution Type
What Production Deployment Considerations Impact Resolver Performance and Reliability?
Horizontal scaling patterns enable DID resolver deployments to handle high-throughput workloads by distributing resolution requests across multiple resolver instances running in parallel. Load balancers route incoming HTTP requests to a pool of stateless resolver processes, with each process maintaining its own driver instances and blockchain client connections. This architecture allows organizations to scale resolution capacity by adding more resolver instances as traffic grows, with the load balancer automatically distributing requests to maintain even utilization across the pool. Driver pooling within each resolver instance pre-initializes multiple driver instances for frequently-used DID methods, eliminating the overhead of driver instantiation on every resolution request. Connection pooling to blockchain RPC endpoints maintains persistent connections that resolver instances reuse across multiple resolution operations, avoiding the TCP handshake and SSL negotiation overhead that would occur if each resolution opened a new connection.
Distributed caching layers implement multi-tier cache architectures that balance memory constraints with cache hit rates. The first tier uses in-process memory caches within each resolver instance, storing recently-resolved DID documents in local RAM for sub-millisecond retrieval. This tier handles the hottest DIDs—identities that are resolved hundreds or thousands of times per minute—without any network round trips. The second tier deploys a Redis cluster shared across all resolver instances, providing a distributed cache that achieves cache hits even when requests for the same DID land on different resolver instances. Redis persistence ensures cache contents survive resolver restarts, eliminating cold-start periods where empty caches force all resolutions to query blockchain networks. The third tier implements content delivery network (CDN) caching for public resolver deployments, serving cached DID documents from edge locations close to client applications and reducing latency for geographically distributed identity systems, similar to optimization strategies used in multi-chain MLM smart contract architecture where performance across multiple blockchain networks is critical.
Blockchain node infrastructure requirements vary significantly across DID methods, with each method imposing different demands on node connectivity, synchronization state, and query capabilities. Methods built on Ethereum require access to archive nodes for historical resolution queries, as standard full nodes only maintain recent state and cannot reconstruct DID documents as they existed at past block heights. Archive node access typically requires dedicated infrastructure or premium RPC service subscriptions, as public archive node endpoints often implement strict rate limiting that proves insufficient for production resolver deployments. Methods using Bitcoin or other UTXO-based chains require full nodes with transaction indexing enabled, allowing resolvers to efficiently query specific transactions by hash without scanning the entire blockchain. The resolver must implement RPC endpoint selection logic that chooses appropriate nodes based on the resolution request type, routing historical queries to archive nodes while directing current-state queries to faster full nodes.
Failover mechanisms protect resolver availability when blockchain nodes become unavailable due to network issues, node crashes, or maintenance windows. The resolver maintains a prioritized list of RPC endpoints for each supported blockchain network, automatically failing over to backup endpoints when primary nodes return errors or exceed timeout thresholds. Health checking runs continuously in the background, probing each RPC endpoint with lightweight requests and marking unhealthy endpoints as unavailable until they recover. Circuit breakers prevent cascading failures by temporarily stopping resolution attempts for methods whose blockchain infrastructure is completely unavailable, returning cached documents when available or explicit error responses when caches are empty. This failure isolation ensures that issues with one blockchain network don’t impact resolution of DIDs using other methods, maintaining partial availability even during significant infrastructure disruptions.
Rate limit management coordinates resolver query patterns with the rate limits imposed by blockchain RPC providers, preventing the resolver from exceeding allowed request rates and triggering throttling or service bans. Token bucket algorithms track request rates per RPC endpoint, delaying outgoing queries when approaching rate limits and queuing resolution requests for processing when capacity becomes available. The resolver prioritizes queued requests based on client priority levels, ensuring high-value clients receive resolution capacity during periods of congestion while lower-priority requests wait. For organizations running their own blockchain nodes, rate limiting focuses on preventing resolver traffic from overwhelming node resources, implementing backpressure mechanisms that slow resolution throughput when node CPU or memory utilization exceeds safe thresholds. These patterns prove essential for maintaining stable resolver operations similar to the reliability requirements in blockchain cold chain compliance systems where identity resolution failures could disrupt time-sensitive supply chain operations.
| Infrastructure Component | Scaling Strategy | Typical Configuration |
|---|---|---|
| Resolver Instances | Horizontal scaling behind load balancer | 3-10 instances for 1000 req/sec throughput |
| Redis Cache Cluster | Sharded cluster with replication | 3-node cluster, 16GB RAM per node |
| Ethereum Archive Nodes | Primary + backup endpoints with failover | 2 dedicated nodes or premium RPC service |
| Load Balancer | Active-active pair for high availability | NGINX or cloud load balancer with health checks |
| Monitoring Stack | Centralized metrics aggregation | Prometheus + Grafana with 30-day retention |
Monitoring and observability implementation provides operational teams with the visibility needed to maintain resolver performance and quickly diagnose issues when they occur. Resolution latency metrics track the end-to-end time from request receipt to response delivery, broken down by DID method to identify performance variations across different blockchain networks. Percentile metrics (p50, p95, p99) reveal latency distribution patterns, highlighting whether occasional slow resolutions result from blockchain network congestion or systematic issues in driver implementation. Cache hit ratio monitoring tracks the percentage of resolutions served from cache versus requiring blockchain queries, with declining hit ratios signaling changes in resolution patterns or cache configuration issues that warrant investigation. Method-specific error rates quantify resolution failures by DID method and error type, enabling teams to quickly identify whether errors stem from blockchain network issues, driver bugs, or invalid DIDs submitted by clients.
Distributed tracing instruments resolution requests as they flow through resolver components, capturing timing information for each processing stage from initial request parsing through driver invocation, blockchain query execution, document construction, and response serialization. Trace data reveals performance bottlenecks within the resolution pipeline, showing whether latency concentrates in blockchain queries (suggesting node performance issues) or document construction (indicating driver optimization opportunities). Correlation IDs link traces across multiple resolver instances and external service calls, enabling teams to reconstruct the complete request flow for troubleshooting complex failure scenarios. This observability foundation supports continuous optimization of resolver infrastructure, similar to the monitoring practices required for token vesting smart contract architecture where tracking contract execution performance ensures reliable token distribution operations.
Operational dashboards aggregate monitoring data into actionable views that enable teams to assess resolver health at a glance and quickly respond to incidents. Real-time dashboards display current throughput, average latency, error rates, and cache hit ratios, with color-coded indicators that flag metrics exceeding acceptable thresholds. Method-specific panels break down these metrics by DID method, revealing whether issues affect all methods uniformly or concentrate in specific blockchain networks. Alerting rules trigger notifications when critical metrics deviate from baseline patterns, such as sustained error rates above 1%, p95 latency exceeding 500ms, or cache hit ratios dropping below 80%. These alerts integrate with on-call rotation systems, ensuring operations teams receive timely notification of resolver issues that could impact identity verification services for downstream applications. The combination of comprehensive monitoring, distributed tracing, and proactive alerting creates the operational foundation necessary for maintaining production-grade resolver infrastructure that delivers the reliability and performance expectations of modern decentralized identity systems, following patterns established in private blockchain architecture design patterns where enterprise-grade monitoring proves essential for production deployments.
DID resolver implementation represents a critical infrastructure layer that enables decentralized identity systems to function without centralized dependencies. The architectural patterns explored here—universal resolver frameworks with pluggable drivers, method-specific implementation strategies, versioning and deactivation handling, and production deployment considerations—provide teams with the technical foundation needed to build reliable, performant resolution services. As decentralized identity adoption accelerates across industries from healthcare to financial services, resolver infrastructure will become as fundamental to digital identity as DNS is to internet naming, making robust implementation practices essential for organizations building next-generation identity systems.
Frequently Asked Questions
Q1.What is the difference between a universal DID resolver and a method-specific resolver?
A universal DID resolver supports multiple DID methods through a pluggable driver architecture, routing resolution requests to appropriate method-specific handlers. A method-specific resolver implements resolution logic for a single DID method (like did:ethr or did:key), directly interfacing with that method’s underlying infrastructure. Universal resolvers provide broader interoperability but add complexity, while method-specific resolvers offer optimized performance and simpler deployment for dedicated use cases.
Q2.How does a DID resolver retrieve a DID document from a blockchain network?
A DID resolver parses the DID to extract the method and identifier, then queries the corresponding blockchain smart contract or registry using RPC calls. It retrieves on-chain data containing public keys, service endpoints, and verification methods, then constructs a standardized DID document according to W3C specifications. The resolver may query multiple nodes for consensus verification and handle network-specific encoding formats before returning the resolved document.
Q3.What are the main components of a DID resolution algorithm?
Core components include the DID parser (extracting method and identifier), method driver (handling method-specific logic), network interface (blockchain/distributed ledger connection), document constructor (assembling W3C-compliant output), metadata generator (resolution timestamps and versioning), and error handler (managing not-found, deactivated, or malformed DIDs). Additional components include caching layer, authentication mechanisms, and representation transformer for different output formats like JSON-LD or CBOR.
Q4.How do you implement caching for DID resolvers without compromising security?
Implement time-bound caching with configurable TTL values based on DID method update frequency, typically 5-60 minutes. Include cache invalidation triggers for known updates and verification of cryptographic proofs on cached documents. Store resolution metadata including cache timestamp and blockchain block height. Implement cache-control headers respecting DID document metadata, and use secure cache storage with encryption. Critical operations should bypass cache or verify freshness against authoritative sources.
Q5.What blockchain node infrastructure is required to run a production DID resolver?
Production DID resolver implementation requires redundant full nodes or archive nodes for each supported blockchain, load balancers distributing RPC requests, and monitoring systems tracking node health and synchronization status. Infrastructure includes high-availability database for caching, backup nodes across geographic regions, rate-limiting and DDoS protection, and automated failover mechanisms. Archive nodes are essential for resolving historical DID states. Minimum 99.9% uptime requires at least three synchronized nodes per network.
Q6.How does a DID resolver handle deactivated or revoked decentralized identifiers?
When resolving a deactivated DID, the resolver checks the on-chain registry status flag or deactivation transaction. It returns a DID resolution result with error code ‘deactivated’ and metadata indicating deactivation timestamp and block number. The resolver may optionally return the last valid DID document with deactivation metadata. For revoked credentials, the resolver checks revocation registries and includes revocation status in resolution metadata, allowing verifiers to make informed trust decisions.
Explore Services
Related Services
Reviewed by

Naman Singh
Co-Founder & CEO, Nadcab Labs
Naman Singh is the Co-Founder and CEO of Nadcab Labs, where he drives the company’s vision, global growth, and strategic expansion in blockchain, fintech, and digital transformation. A serial entrepreneur, Naman brings deep hands-on experience in building, scaling, and commercializing technology-driven businesses. At Nadcab Labs, Naman works closely with enterprises, governments, and startups to design and implement secure, scalable, and business-ready Web3 and blockchain solutions. He specializes in transforming complex ideas into high-impact digital products aligned with real business objectives. Naman has led the development of end-to-end blockchain ecosystems, including token creation, smart contracts, DeFi and NFT platforms, payment infrastructures, and decentralized applications. His expertise extends to tokenomics design, regulatory alignment, compliance strategy, and go-to-market planning—helping projects become investor-ready and built for long-term sustainability. With a strong focus on real-world adoption, Naman believes in building blockchain solutions that deliver measurable value, solve practical problems, and unlock new growth opportunities for organizations worldwide.