Ai Overview
RPA architecture design patterns define the structural blueprint for building scalable, maintainable robotic process automation systems that can handle enterprise workloads reliably. Understanding these patterns is essential for architects designing systems that must process thousands of transactions daily while maintaining fault tolerance and security compliance.
RPA architecture design patterns define the structural blueprint for building scalable, maintainable robotic process automation systems that can handle enterprise workloads reliably. These patterns establish how orchestrators coordinate bot fleets, how work queues decouple processing stages, and how credential vaults secure sensitive access—forming the technical foundation that determines whether an automation initiative succeeds or collapses under production load. Understanding these patterns is essential for architects designing systems that must process thousands of transactions daily while maintaining fault tolerance and security compliance.
Key Takeaways
- RPA architecture consists of three core layers: orchestrator (control plane), bot execution (worker layer), and integration (connectivity layer) that must work in concert
- The orchestrator-bot framework pattern uses master-worker topology with state management and load balancing to distribute work across bot pools efficiently
- Queue-based processing architectures decouple automation stages, enable retry logic, and provide transactional boundaries for reliable work item handling
- Credential vault integration requires encrypted storage, runtime injection patterns, and multi-environment isolation to meet security and compliance requirements
- Exception handling hierarchies distinguish business errors from system failures, implement escalation workflows, and provide observability through structured logging and tracing
- Proper architecture patterns directly impact system reliability, scalability, and maintainability—critical factors that separate proof-of-concept demos from production-grade automation platforms
What Are the Core Components of RPA Architecture?
Every robust RPA system architecture is built on three foundational layers that work together to deliver reliable automation at scale. The orchestrator layer serves as the centralized control plane, managing bot deployment across distributed environments, scheduling process executions based on business rules and time triggers, and providing real-time monitoring dashboards that track bot health, queue depths, and error rates. This control plane maintains a registry of all available bots, their capabilities, current workload, and operational status—enabling intelligent task assignment and resource optimization across the entire automation fleet.
The bot execution layer contains the actual workers that perform automation tasks. Attended bots run on user workstations and assist human workers by automating repetitive steps within their workflow, requiring human initiation or oversight. Unattended bots operate autonomously on server infrastructure, executing scheduled processes or responding to queue triggers without human intervention. Each bot runs within a runtime engine—a process execution container that provides isolation, resource management, and crash recovery. Modern architectures deploy these runtime engines as containerized workloads using Docker or Kubernetes, enabling horizontal scaling and efficient resource utilization across cloud and on-premises infrastructure.
The integration layer bridges the automation platform to enterprise systems and external services. API connectors provide programmatic access to web services and microservices, enabling bots to invoke REST endpoints, consume SOAP services, and interact with SaaS applications. Database adapters allow direct SQL queries and stored procedure execution against relational databases like SQL Server, Oracle, and PostgreSQL. Credential vaults securely store authentication credentials, API keys, and certificates, injecting them at runtime without exposing secrets in bot code. Third-party service bridges connect to specialized systems like mainframe terminals, SAP modules, and legacy applications through screen scraping, COM automation, or proprietary APIs.
These three layers must communicate through well-defined interfaces. The orchestrator exposes management APIs that bots use to retrieve work items, report status, and request credentials. Bots publish telemetry data—execution logs, performance metrics, and exception details—back to the orchestrator for centralized monitoring and analytics. The integration layer provides abstraction facades that shield bot logic from underlying system complexity, allowing credential rotation, endpoint changes, and version upgrades without modifying bot code. When designing RPA Development solutions, this layered separation of concerns is critical for maintaining system flexibility and operational stability.
| Component Layer | Primary Responsibility | Key Technologies | Typical Deployment |
|---|---|---|---|
| Orchestrator | Task scheduling, bot coordination, monitoring | UiPath Orchestrator, Automation Anywhere Control Room, Blue Prism Server | High-availability cluster with load balancer, 3-5 node minimum |
| Bot Execution | Process automation, data transformation, system interaction | Bot runtime engines, Docker containers, virtual machines | Horizontal scaling: 10-50 bot instances per orchestrator |
| Integration | Credential management, API connectivity, data access | CyberArk, HashiCorp Vault, Azure Key Vault, custom adapters | Dedicated secure zone with network isolation and encryption |
| Data Storage | Queue persistence, audit logs, configuration data | SQL Server, PostgreSQL, MongoDB, Redis for caching | Replicated database cluster with automated backup every 6 hours |
A well-designed component architecture also includes supporting infrastructure for logging, monitoring, and analytics. Centralized logging aggregates bot execution logs, exception traces, and audit events into platforms like Elasticsearch or Splunk, enabling full-text search and correlation analysis. Monitoring systems collect real-time metrics on bot utilization, process duration, error rates, and queue depths, feeding dashboards that operations teams use to detect anomalies and capacity constraints. Analytics engines process historical execution data to identify optimization opportunities, predict resource needs, and measure business impact through KPIs like cycle time reduction and cost savings per transaction.
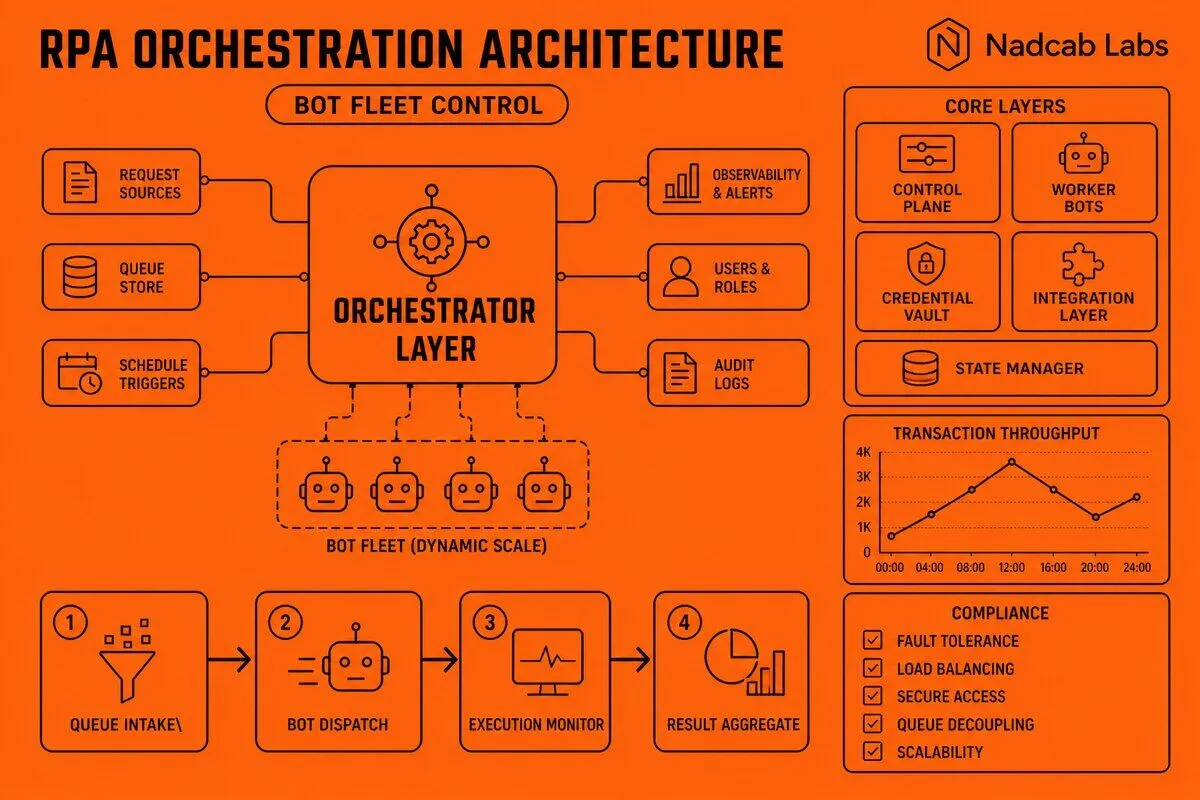
How Does the Orchestrator-Bot Framework Pattern Work?
The orchestrator-bot framework pattern implements a master-worker topology where a central orchestrator acts as the master, maintaining a pool of worker bots and intelligently distributing tasks based on availability, priority, and resource constraints. When a new automation job arrives—whether from a scheduled trigger, an API call, or a queue event—the orchestrator evaluates which bots are currently idle, which have the required capabilities (specific application credentials, language skills, or system access), and which are running in the appropriate environment (development, testing, or production). It then assigns the job to the most suitable bot, tracks execution progress, and handles results or exceptions upon completion.
This topology solves the fundamental challenge of coordinating multiple automation processes across a distributed bot fleet. Without an orchestrator, each bot would need to independently poll for work, manage its own schedule, and coordinate with other bots to avoid conflicts—a recipe for race conditions, duplicate processing, and resource contention. The orchestrator provides a single source of truth for work distribution, eliminating these coordination problems through centralized control. It maintains priority queues where high-urgency jobs jump ahead of routine tasks, implements fair scheduling algorithms that prevent any single process from monopolizing bot resources, and enforces capacity limits that prevent overload when work volume spikes unexpectedly.
State management is a critical aspect of this pattern. The orchestrator persists workflow state at key checkpoints throughout process execution, storing information about completed steps, intermediate data values, and pending decisions. If a bot crashes mid-execution, the orchestrator can restart the process from the last checkpoint rather than beginning from scratch, avoiding duplicate transactions and wasted processing time. This checkpoint recovery mechanism relies on transactional boundaries—points in the workflow where all preceding operations have completed successfully and can be safely committed. If an error occurs between checkpoints, the orchestrator rolls back to the previous consistent state, undoes any partial changes, and either retries the failed operation or routes the work item to an exception queue for manual review.
Load balancing strategies determine how the orchestrator distributes work across the bot pool when multiple bots could handle a given task. Round-robin allocation cycles through available bots sequentially, ensuring even distribution but ignoring bot performance characteristics. Priority-based allocation considers job urgency and bot specialization, assigning critical tasks to the most reliable bots while routing routine work to general-purpose workers. Capacity-aware allocation monitors current bot workload—CPU usage, memory consumption, and active process count—and avoids assigning new tasks to bots that are already near capacity limits. Sophisticated implementations combine these strategies, using priority queues for job ordering and capacity-aware selection for bot assignment, ensuring both urgency and resource efficiency.
The robotic process automation framework also handles bot lifecycle management. When a bot starts, it registers with the orchestrator, advertising its capabilities, available credentials, and resource capacity. The orchestrator performs health checks at regular intervals, sending heartbeat requests and expecting timely responses. If a bot fails to respond—due to a crash, network partition, or resource exhaustion—the orchestrator marks it as unavailable, reassigns any in-progress jobs to healthy bots, and triggers alerts for operations teams. When a bot completes maintenance or recovers from a failure, it re-registers with the orchestrator and resumes accepting work assignments. This dynamic registration and health monitoring enables the bot fleet to scale elastically, adding capacity during peak periods and reducing it during low-demand windows without manual intervention.
What Is Queue-Based Processing Architecture in RPA?
Queue-based processing architecture decouples the stages of an automation workflow by introducing work item queues between process steps, allowing each stage to operate independently at its own pace without blocking upstream or downstream components. A work item represents a single unit of processing—an invoice to extract, a customer record to update, or a report to generate. These items are placed into queues where they wait for available bots to retrieve and process them. This pattern transforms a monolithic end-to-end automation into a series of specialized stages connected by queues, each stage focusing on a specific task and consuming items as fast as its bot pool can handle.
Work item queues come in several structural variants. FIFO (first-in-first-out) queues process items in the order they arrive, appropriate for workflows where all items have equal priority and fairness matters. Priority queues assign each work item an urgency score, processing high-priority items before low-priority ones regardless of arrival order—critical for SLA-driven processes where certain customers or transaction types require expedited handling. Deadline-driven queues incorporate time-to-process constraints, automatically escalating items that approach their deadline and potentially rerouting them to dedicated high-speed bot pools to ensure on-time completion. Many production systems use hybrid queue structures that combine priority and deadline logic, with configurable rules that balance urgency, fairness, and resource optimization.
Retry and exception handling patterns are fundamental to queue-based architectures. When a bot encounters a transient error—a temporary network timeout, a locked database record, or an application that is momentarily unresponsive—the system should not immediately fail the work item. Instead, it implements exponential backoff retry logic, waiting progressively longer intervals (2 seconds, 4 seconds, 8 seconds, 16 seconds) before reattempting the operation. This pattern allows transient conditions to resolve without overwhelming the failing system with rapid retry attempts. After a configured maximum retry count (typically 3 to 5 attempts), the work item moves to a dead-letter queue—a holding area for items that could not be processed despite multiple attempts. Operations teams review dead-letter queues periodically, investigating root causes and either correcting the underlying issue (fixing data format problems, restoring system connectivity) or manually processing the exceptions.
Manual intervention triggers provide a safety valve for complex exceptions that require human judgment. When a bot encounters an ambiguous situation—unclear invoice data that could be interpreted multiple ways, a customer request that falls outside standard procedures, or a system error that suggests data corruption—it can escalate the work item to a human review queue. A human operator examines the situation, makes a decision, and either completes the task manually or provides corrective input that allows the bot to continue. The system logs these interventions, tracking which exception types require human oversight most frequently and enabling process improvement efforts that reduce manual intervention over time through better data validation, expanded decision logic, or improved error handling.
Transactional boundaries ensure that work item processing is atomic—either all operations within a work item complete successfully, or none of them do. When a bot begins processing a work item, it marks the item as “in progress” in the queue, preventing other bots from retrieving the same item. It then performs all required operations—data extraction, system updates, file generation—within a logical transaction. If all operations succeed, the bot commits the transaction, marks the work item as “completed,” and removes it from the queue. If any operation fails, the bot rolls back the transaction, undoes any partial changes, and returns the work item to the queue for retry. This atomic processing prevents data inconsistencies where some systems reflect updated information while others remain in the old state.
Idempotency guarantees complement transactional boundaries by ensuring that processing the same work item multiple times produces the same result as processing it once. This property is critical when retries occur after uncertain failures—situations where a bot completed some operations but crashed before confirming success, leaving the orchestrator unsure whether to retry. Idempotent operations check whether they have already been performed before executing, using unique transaction identifiers, timestamp comparisons, or state flags to detect duplicates. For example, an invoice processing bot might check whether an invoice number already exists in the accounts payable system before attempting to insert it, preventing duplicate payment processing even if the work item is retried multiple times.
Similar to market making algorithm architecture, queue-based RPA systems benefit from sophisticated monitoring and optimization. Queue depth metrics track how many work items are waiting for processing, alerting operations teams when backlogs grow beyond thresholds that indicate insufficient bot capacity. Processing time distributions reveal which work items take significantly longer than average, highlighting candidates for process optimization or additional bot specialization. Throughput rates measure items processed per hour, enabling capacity planning and cost-benefit analysis for adding more bots or optimizing existing automation logic.
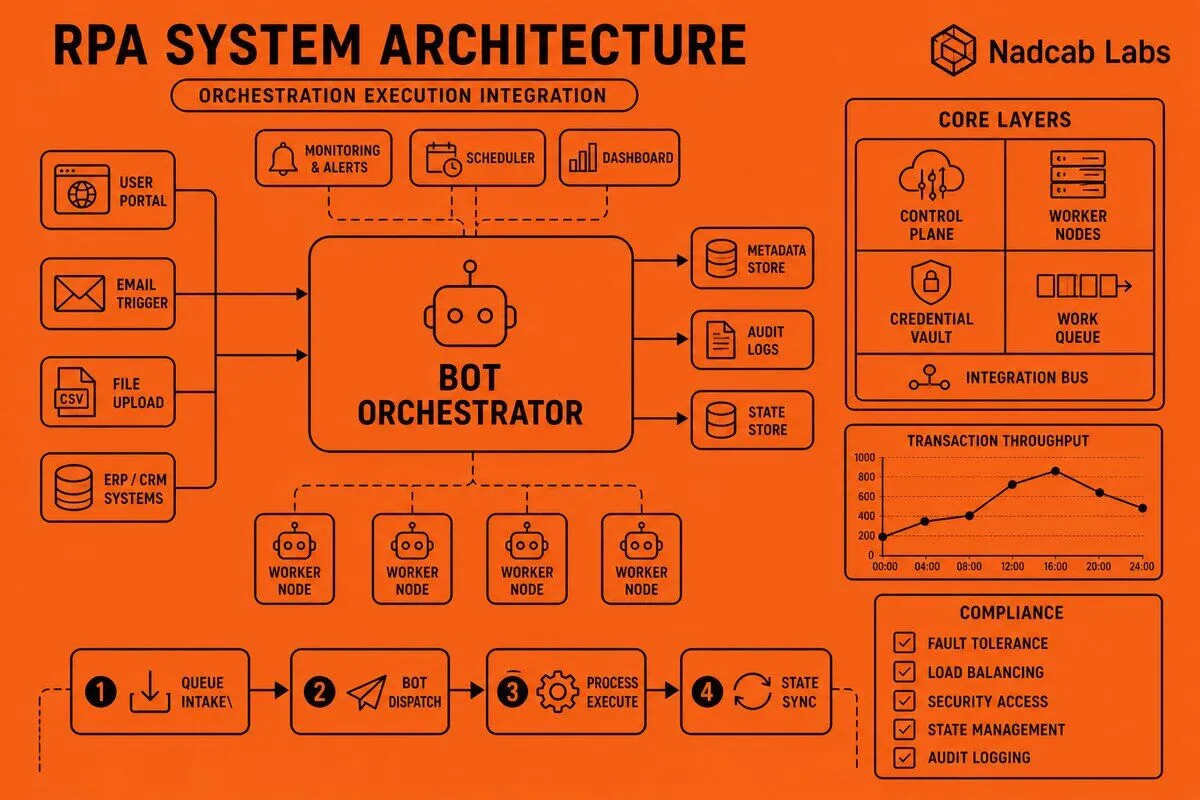
How Should Credential Vault Integration Be Designed?
Credential vault integration is the cornerstone of secure RPA infrastructure design, providing encrypted storage for sensitive authentication credentials, API keys, certificates, and secrets that bots need to access target systems. A credential vault acts as a centralized, hardened repository where credentials are stored with strong encryption (typically AES-256), protected by access control policies that specify which bots, processes, and users can retrieve specific credentials. This centralization eliminates the dangerous practice of embedding credentials directly in bot code or configuration files, where they would be visible to anyone with access to the automation repository and vulnerable to exposure through version control systems, log files, or error messages.
Modern vault implementations like HashiCorp Vault, CyberArk, and Azure Key Vault provide several critical security features beyond basic encryption. Role-based access control (RBAC) defines granular permissions, allowing specific bots to retrieve only the credentials they need for their assigned processes—a principle of least privilege that limits the damage if a bot is compromised. Credential rotation policies automatically change passwords and API keys at regular intervals (every 30, 60, or 90 days), reducing the window of opportunity for stolen credentials to be exploited. Audit logging records every credential access attempt, capturing which bot retrieved which credential at what time, creating a tamper-evident trail that security teams use to detect unauthorized access or investigate security incidents.
Runtime credential injection implements just-in-time retrieval patterns where bots request credentials from the vault only when needed, use them for the immediate operation, and then discard them from memory rather than caching them for future use. This approach minimizes credential exposure time and reduces the risk of credentials being captured through memory dumps or process inspection. Session-scoped secrets take this further by generating temporary credentials that are valid only for a single bot execution session, automatically expiring after a short duration (15 minutes to 1 hour). When the bot completes its task or the session expires, the temporary credentials become invalid, rendering them useless to attackers even if intercepted.
| Credential Storage Pattern | Security Level | Use Case | Implementation Complexity |
|---|---|---|---|
| Embedded in Code | Very Low (not recommended) | Proof-of-concept demos only, never production | Trivial but dangerous |
| Configuration Files | Low (legacy systems) | Legacy applications with limited security requirements | Simple but exposes credentials in file system |
| Encrypted Vault (Basic) | Medium | Standard enterprise automation with moderate security needs | Moderate – requires vault setup and integration |
| Vault with RBAC + Rotation | High | Financial services, healthcare, regulated industries | High – needs policy management and rotation automation |
| Session-Scoped Secrets | Very High | Payment processing, PII handling, critical infrastructure | Very High – requires dynamic credential generation |
Multi-environment strategies address the challenge of maintaining separate credential sets for development, testing, and production environments while preventing cross-environment credential leakage. Environment-specific vault mappings ensure that bots running in the development environment can only access development credentials, even if the same bot code is deployed across all environments. This isolation is typically implemented through namespace separation within the vault—dev credentials stored under a /dev namespace, test credentials under /test, and production credentials under /prod—with access policies that restrict each bot’s token to its corresponding namespace. Configuration management systems inject environment-specific vault connection parameters (vault URL, namespace, authentication token) at deployment time, ensuring bots automatically connect to the correct vault instance for their environment.
Compliance controls integrate credential vault patterns with regulatory requirements like SOX, HIPAA, PCI-DSS, and GDPR. These regulations often mandate specific credential management practices: passwords must be changed every 90 days, access must be logged and auditable for 7 years, privileged credentials must require multi-factor authentication, and credentials must never be transmitted or stored in plaintext. Vault implementations provide built-in compliance features—automated rotation schedules, immutable audit logs, integration with MFA providers, and encryption-at-rest and encryption-in-transit guarantees—that help organizations meet these requirements without building custom security infrastructure. When designing automation that handles sensitive data, integrating with a compliant credential vault is not optional—it is a fundamental requirement that determines whether the system can be deployed in regulated environments.
The credential vault also serves as the integration point for identity and access management (IAM) systems. Rather than maintaining a separate user database for bot credentials, the vault can authenticate against enterprise Active Directory, LDAP, or SAML identity providers, inheriting their user lifecycle management, password policies, and access control rules. When an employee leaves the organization, their credentials are automatically revoked across all systems, including bot access, through the centralized IAM system. This integration reduces administrative overhead and ensures consistent security posture across human and bot identities. Similar patterns appear in private blockchain architecture design patterns, where credential management and access control are equally critical for maintaining system integrity.
What Are the Best Practices for Exception Handling Hierarchies?
Exception handling hierarchies establish a layered strategy for classifying, responding to, and escalating errors that occur during automation execution. The fundamental distinction is between business exceptions and system exceptions. Business exceptions occur when the automation encounters data or conditions that violate business rules but do not indicate a technical failure—an invoice with a missing purchase order number, a customer record that fails validation checks, or a transaction amount that exceeds approval thresholds. These exceptions represent legitimate edge cases that the business process must handle through defined workflows: routing the item to a manual review queue, requesting additional information from the submitter, or applying fallback processing rules. Business exceptions do not indicate a problem with the automation itself; they are expected variations in business data that require special handling.
System exceptions, by contrast, indicate technical failures in the automation infrastructure or target systems—network timeouts, database connection failures, application crashes, authentication errors, or resource exhaustion. These exceptions suggest that something is wrong with the underlying technology stack and that the automation cannot proceed until the issue is resolved. System exceptions are further classified into retry-able and fatal errors. Retry-able errors are transient conditions that may resolve on their own: a temporary network glitch, a locked database record that will be released shortly, or an application that is briefly unresponsive during a restart. Fatal errors represent permanent failures that will not resolve through retries: invalid credentials that require manual correction, missing files that must be restored from backup, or software bugs that require code fixes.
The bot framework design implements this classification through structured exception handling in the automation code. Each bot operation is wrapped in try-catch blocks that inspect exception types and attributes to determine the appropriate response. When a business exception occurs, the bot logs the exception details, marks the work item with the specific business rule violation, and routes it to the designated business exception queue where human reviewers can address it. When a retry-able system exception occurs, the bot increments a retry counter, waits for the backoff interval, and reattempts the operation. When a fatal system exception occurs, the bot logs comprehensive diagnostic information (stack traces, system state, input data), marks the work item as failed, and triggers alerts to technical support teams who can investigate and resolve the underlying issue.
Escalation workflows define the sequence of automated and manual interventions that occur when exceptions cannot be resolved through standard retry logic. The first escalation level is typically automated recovery: the bot attempts alternative processing paths, uses fallback data sources, or invokes redundant system instances to work around the failure. If automated recovery fails, the second escalation level routes the work item to a supervisor notification queue, where a designated team member receives an alert (email, SMS, or Slack message) and can investigate the issue during business hours. If the supervisor cannot resolve the exception within a defined SLA (2 hours, 4 hours, or 24 hours depending on process criticality), the third escalation level triggers incident management procedures: creating a support ticket, paging on-call engineers, or initiating a formal problem investigation.
Fallback process paths provide alternative workflows that maintain business continuity when primary automation fails. For example, if an automated invoice processing bot cannot access the accounts payable system due to a prolonged outage, the fallback path might export pending invoices to a CSV file and email them to the AP team for manual processing, ensuring that critical vendor payments are not delayed. Fallback paths are designed during the automation development phase, identifying critical processes that cannot tolerate extended downtime and defining manual or semi-automated alternatives that can be activated when needed. These paths are tested regularly through disaster recovery drills to ensure they function correctly when invoked under actual failure conditions.
Observability patterns provide the instrumentation and monitoring capabilities that make exception handling effective. Structured logging emits exception events in a consistent JSON format that includes exception type, severity level, timestamp, bot identifier, work item ID, stack trace, and contextual data about the operation that failed. These structured logs feed into centralized logging platforms (Elasticsearch, Splunk, or Azure Monitor) where they can be searched, filtered, and analyzed to identify patterns—recurring exceptions that indicate systemic problems, error spikes that correlate with system deployments, or specific work item characteristics that trigger failures. Distributed tracing extends this observability across multi-stage workflows, assigning a unique trace ID to each work item and propagating it through all processing stages, enabling engineers to follow the complete execution path and pinpoint exactly where failures occur in complex automation chains.
Real-time alerting for anomaly detection uses statistical methods and machine learning to identify unusual exception patterns that warrant immediate investigation. Baseline exception rates are established during normal operation—perhaps 2 to 3 percent of work items encounter business exceptions, and 0.5 percent encounter system exceptions. When exception rates exceed these baselines by statistically significant margins (2 standard deviations above the mean), the monitoring system triggers alerts indicating that something abnormal is happening: a data quality issue in the source system, a configuration change that broke an integration, or a capacity constraint causing timeouts. These anomaly-based alerts catch problems that might not trigger individual exception thresholds but indicate emerging issues that could escalate into major incidents if not addressed promptly. The approach mirrors patterns seen in blockchain disaster recovery architecture, where proactive monitoring and rapid response to anomalies are essential for maintaining system reliability.
Exception metrics feed continuous improvement processes. Operations teams review exception reports weekly or monthly, analyzing which exception types occur most frequently, which processes have the highest exception rates, and which exceptions require the most manual intervention time. This analysis identifies opportunities for process optimization: improving data validation to catch business rule violations earlier, enhancing error handling logic to automatically recover from common failures, or working with target system owners to improve API reliability. Over time, mature RPA implementations reduce exception rates significantly through iterative refinement, achieving straight-through processing rates above 95 percent for well-designed processes. This continuous improvement cycle, supported by comprehensive observability and data-driven decision-making, transforms RPA from a fragile automation layer into a robust production system that delivers consistent business value.
When designing exception handling for automation systems, consider how these patterns integrate with broader enterprise architecture. Exceptions should feed into existing incident management systems (ServiceNow, Jira Service Desk) rather than creating parallel tracking mechanisms. Alert routing should respect on-call schedules and escalation policies already defined in the organization’s runbook. Compliance requirements may mandate specific exception retention periods, audit trails, and reporting formats that must be incorporated into the design. By aligning RPA exception handling with enterprise standards, you create a cohesive operational model that leverages existing processes and tools rather than introducing new silos. This integration is particularly important when RPA systems interact with other advanced architectures like ai chatbot architecture or RWA tokenization smart contract architecture, where exception handling must coordinate across multiple technology domains.
Finally, exception handling design must account for the human factors involved in manual intervention and escalation. Review queues should present exception details clearly, providing all context needed for a human reviewer to make an informed decision without hunting through multiple systems. Escalation alerts should include actionable information—not just “bot failed” but “bot failed because API returned 503 Service Unavailable; check system status page and retry after service restoration.” Training materials should explain the exception classification scheme and the expected response for each exception type, ensuring that operations teams handle exceptions consistently. User interfaces for exception management should prioritize usability, allowing reviewers to quickly triage exceptions, take corrective actions, and provide feedback that improves future automation behavior. A well-designed exception handling hierarchy balances automated resilience with human judgment, creating a system that handles routine failures autonomously while escalating complex situations to people who can apply expertise and creativity to resolve them.
Final Thoughts
RPA architecture design patterns provide the structural foundation that determines whether automation initiatives deliver sustained business value or collapse under production load. The orchestrator-bot framework establishes centralized control and intelligent work distribution, queue-based processing decouples workflow stages for resilience and scalability, credential vaults secure sensitive access through encryption and access control, and exception handling hierarchies distinguish business rule violations from system failures while enabling automated recovery and human escalation. These patterns work together to create robust automation platforms that can process thousands of transactions daily while maintaining security, reliability, and operational transparency. Organizations that invest in proper architectural design—rather than rushing to deploy quick automation scripts—build systems that scale efficiently, adapt to changing requirements, and integrate seamlessly with enterprise infrastructure. When combined with comprehensive monitoring, continuous improvement processes, and alignment with existing enterprise standards, these patterns transform RPA from a tactical automation tool into a strategic platform that delivers measurable business outcomes. For teams planning RPA implementations, understanding and applying these architecture patterns is not optional—it is the difference between proof-of-concept demos that never reach production and enterprise-grade automation that becomes a competitive advantage. To leverage these patterns in your automation strategy, explore how RPA Development services can help design and implement scalable, secure automation architectures tailored to your specific business needs.
Frequently Asked Questions
Q1.What is the difference between attended and unattended bot architecture in RPA?
Attended bots run on user workstations requiring human interaction and triggers, operating in foreground mode with real-time user collaboration. Unattended bots execute autonomously on dedicated servers without human intervention, running scheduled or event-triggered processes in background mode. Attended architecture prioritizes user interface responsiveness and desktop integration, while unattended architecture focuses on scalability, parallel execution, and centralized orchestration for batch processing across distributed infrastructure.
Q2.How does an RPA orchestrator manage bot scheduling and resource allocation?
RPA orchestrators manage scheduling through priority queues, time-based triggers, and event-driven execution policies. They allocate bot resources by monitoring machine availability, CPU/memory utilization, and license pools. The orchestrator distributes workloads across bot fleets using load balancing algorithms, enforces concurrency limits, handles queue assignments, and maintains execution logs. Advanced orchestrators implement dynamic scaling, failover mechanisms, and resource reservation to optimize throughput while preventing resource contention across enterprise automation infrastructure.
Q3.What are the key design patterns for handling exceptions in RPA workflows?
Key exception handling patterns include Try-Catch-Finally blocks for structured error management, retry mechanisms with exponential backoff for transient failures, and circuit breaker patterns to prevent cascade failures. Business exception queues separate technical from application errors. Compensation patterns rollback partial transactions, while dead-letter queues isolate problematic items. Logging frameworks capture detailed error context, and notification services alert stakeholders. Graceful degradation patterns maintain partial functionality during failures, ensuring robust automation resilience.
Q4.How should credential vaults be integrated into RPA architecture for security?
Credential vaults integrate through secure API connections with encrypted communication channels, never storing passwords in bot code or configuration files. Bots authenticate to vault services using certificates or tokens, retrieving credentials at runtime with automatic rotation support. Architecture implements least-privilege access, credential checkout/check-in workflows, and audit logging. Vaults should support multi-tenancy, role-based access control, and integration with enterprise identity management systems. Credentials remain encrypted in memory and are never logged or exposed in error messages.
Q5.What is queue-based processing and why is it important in RPA design?
Queue-based processing decouples work item collection from execution, storing tasks in persistent queues that multiple bots consume concurrently. This pattern enables horizontal scaling, load distribution, and prioritization of work items. Queues provide transaction boundaries, automatic retry logic, and progress tracking. They buffer workload spikes, enable asynchronous processing, and maintain state during bot failures. Queue architecture supports parallel execution, resource optimization, and clear separation between data ingestion and processing layers, critical for enterprise-scale automation reliability.
Q6.How do you design RPA architecture for high availability and fault tolerance?
High availability RPA architecture deploys redundant bot instances across multiple servers with load balancers distributing workload. Implement active-passive failover clusters for orchestrators, replicated queue databases, and distributed credential vaults. Design stateless bots enabling seamless failover, use health monitoring with automatic restart policies, and maintain transaction logs for recovery. Geographic distribution across data centers prevents single points of failure. Implement circuit breakers, graceful degradation, and automated backup strategies ensuring continuous operation despite infrastructure failures.
Explore Services
Related Services
Reviewed by

Naman Singh
Co-Founder & CEO, Nadcab Labs
Naman Singh is the Co-Founder and CEO of Nadcab Labs, where he drives the company’s vision, global growth, and strategic expansion in blockchain, fintech, and digital transformation. A serial entrepreneur, Naman brings deep hands-on experience in building, scaling, and commercializing technology-driven businesses. At Nadcab Labs, Naman works closely with enterprises, governments, and startups to design and implement secure, scalable, and business-ready Web3 and blockchain solutions. He specializes in transforming complex ideas into high-impact digital products aligned with real business objectives. Naman has led the development of end-to-end blockchain ecosystems, including token creation, smart contracts, DeFi and NFT platforms, payment infrastructures, and decentralized applications. His expertise extends to tokenomics design, regulatory alignment, compliance strategy, and go-to-market planning—helping projects become investor-ready and built for long-term sustainability. With a strong focus on real-world adoption, Naman believes in building blockchain solutions that deliver measurable value, solve practical problems, and unlock new growth opportunities for organizations worldwide.