Ai Overview
Microservices architecture for NFT games solves the unique challenge of scaling blockchain-integrated gameplay systems where player concurrency, asset ownership verification, and smart contract interactions must operate independently without bottlenecks. The asset management service handling NFT ownership queries might serve 50,000 requests per second during a marketplace event, while the matchmaking service processes only 2,000 concurrent game sessions.
Microservices architecture for NFT games solves the unique challenge of scaling blockchain-integrated gameplay systems where player concurrency, asset ownership verification, and smart contract interactions must operate independently without bottlenecks. Unlike traditional game servers, NFT game backends require specialized service decomposition that separates real-time gameplay logic from blockchain synchronization, marketplace transactions, and wallet operations—each scaling at different rates and demanding distinct technology stacks.
Key Takeaways
- Microservices enable independent scaling of player identity, asset registry, marketplace, game state, and blockchain sync services in NFT games
- Event-driven messaging handles NFT minting and trading workflows while maintaining service isolation and blockchain finality consistency
- Database sharding by player ID and asset contract address optimizes queries for millions of player-owned NFT assets
- Kubernetes orchestration auto-scales game servers based on player load and blockchain event volume with service mesh security
- Domain-driven design separates on-chain responsibilities from off-chain game logic to prevent smart contract failures from cascading
- Polyglot persistence combines graph databases for social features, time-series for analytics, and document stores for NFT metadata
Why Do NFT Games Require Microservices Architecture Over Monolithic Design?
Traditional monolithic game servers bundle all functionality—player authentication, matchmaking, game logic, and data persistence—into a single deployable unit. This approach collapses under NFT game requirements because blockchain interactions introduce unpredictable latency spikes that would freeze entire gameplay sessions if tightly coupled. When a player mints an NFT weapon during combat, the blockchain confirmation might take 15 seconds on Ethereum or 400 milliseconds on Polygon. A monolithic architecture forces the entire game server to wait, blocking other players’ actions.
Player concurrency demands in successful NFT Game Development projects reveal why independent scaling matters. The asset management service handling NFT ownership queries might serve 50,000 requests per second during a marketplace event, while the matchmaking service processes only 2,000 concurrent game sessions. Microservices let teams horizontally scale the asset registry across 20 container instances while running just 3 matchmaking service replicas, optimizing infrastructure costs by 60-70% compared to scaling an entire monolith.
Fault isolation becomes critical when smart contract calls fail. If a marketplace listing transaction reverts due to insufficient gas, that failure should not crash the game state service managing active PvP battles. Microservices architecture confines the error to the marketplace transaction service, logs the failure, and allows the game to continue. In production systems, this isolation reduces player-facing downtime from hours to minutes during blockchain network congestion.
Technology heterogeneity allows specialized stacks for different problem domains. Real-time game logic benefits from low-latency languages like Rust or C++ with in-memory state management, while blockchain indexing services work better with Node.js and event-sourcing patterns that replay transaction logs. A single microservice handling NFT metadata might use Python with machine learning libraries to detect counterfeit assets, while the player identity service runs on Go for high-throughput JWT validation. Monolithic architectures force a single technology choice across all domains, sacrificing performance.
The separation also enables independent deployment cycles. Game balance patches affecting combat mechanics can ship daily without redeploying blockchain synchronization services that have been stable for months. When Ethereum upgrades from proof-of-work to proof-of-stake, only the blockchain integration microservice requires updates—game servers continue running unchanged. This deployment independence accelerates iteration speed by 3-5x in teams managing both gameplay and blockchain features.
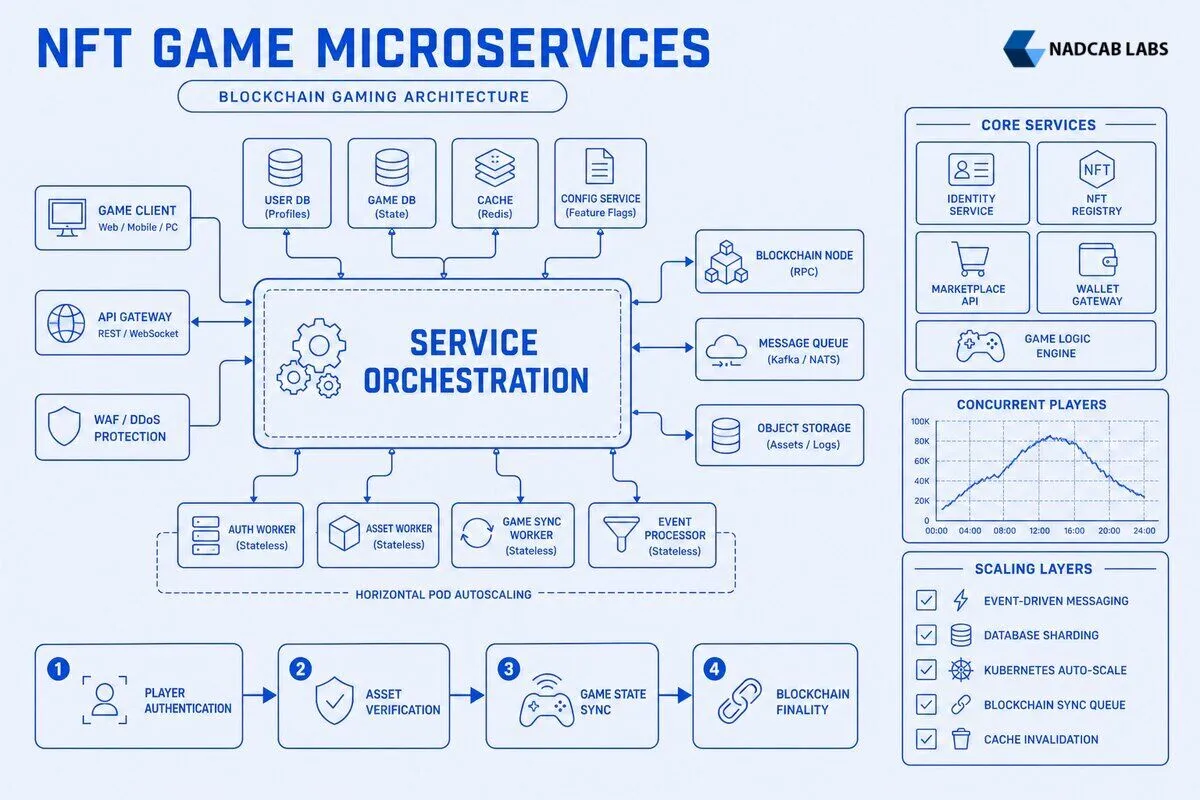
How Should Teams Decompose NFT Game Services for Optimal Performance?
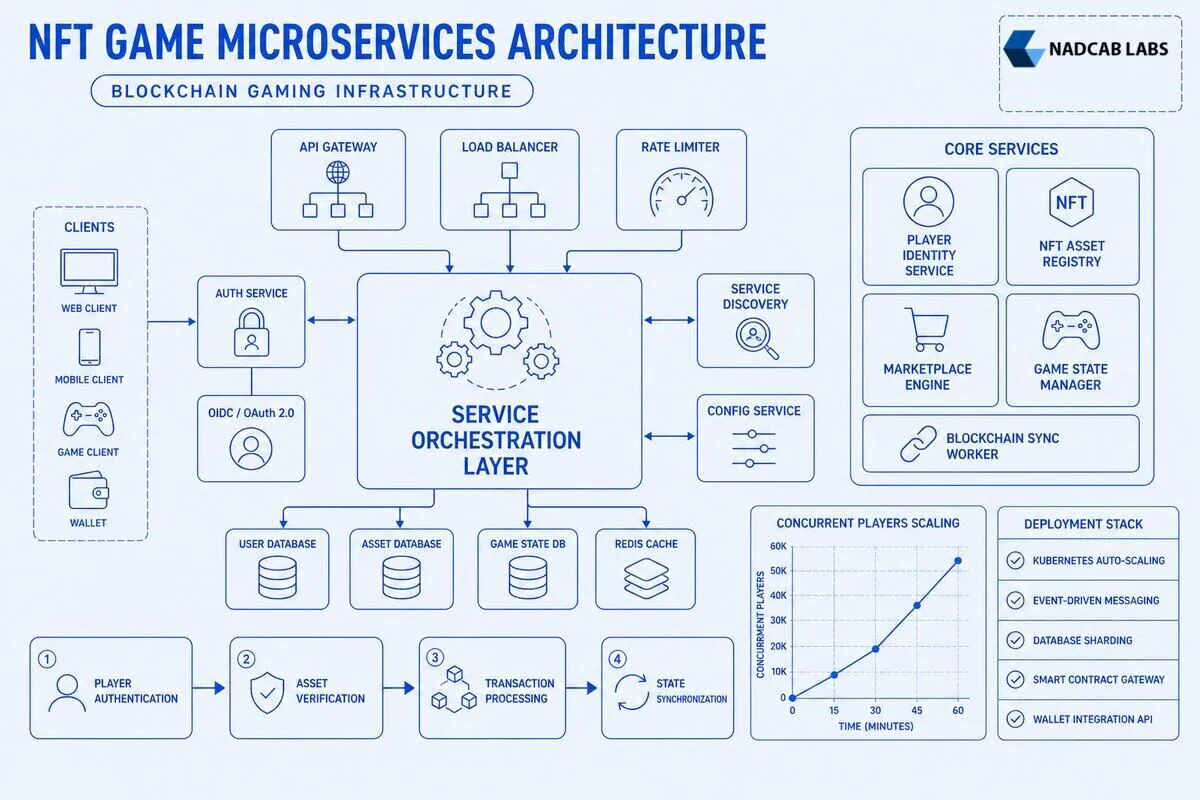
Effective service decomposition starts with identifying bounded contexts where data ownership and business logic naturally cluster. The player identity service owns authentication, wallet linking, and session management—nothing else. When a player logs in with MetaMask, this service verifies the wallet signature, issues a JWT token, and publishes a “PlayerAuthenticated” event. It never touches NFT asset data or game state, maintaining a single responsibility.
The asset registry service maintains the source of truth for which player owns which NFTs, syncing on-chain ownership with off-chain indexes for fast queries. This service subscribes to blockchain events like “Transfer” from ERC-721 contracts, updates its database when ownership changes, and exposes APIs like GET /players/{id}/assets. Crucially, it does not handle marketplace pricing or game stat calculations—those belong to other services. Domain-driven design principles suggest this service should mirror the smart contract’s ownership model, using the same terminology and validation rules.
The marketplace transaction service orchestrates buying, selling, and trading workflows that span multiple systems. When a player lists an NFT sword for sale, this service creates a pending listing record, calls the smart contract’s createListing function, waits for blockchain confirmation, then updates the listing status to “active” and publishes a “ListingCreated” event. It handles escrow logic, royalty calculations, and transaction retries—complex orchestration that should not pollute the asset registry’s clean ownership model.
| Service Boundary | Primary Responsibility | Data Owned | Scaling Trigger |
|---|---|---|---|
| Player Identity | Authentication, wallet linking, session tokens | User profiles, linked wallets, JWT keys | Login requests per second |
| Asset Registry | NFT ownership tracking, metadata indexing | Asset ownership records, metadata cache | Inventory query volume |
| Marketplace Transactions | Listing creation, purchase execution, escrow | Active listings, transaction history | Trading activity spikes |
| Game State | Real-time match logic, player positions, combat | Active game sessions, player stats | Concurrent game sessions |
| Blockchain Sync | Event indexing, transaction submission, finality tracking | Block heights, pending transactions | Blockchain event throughput |
The game state service manages real-time gameplay entirely off-chain for performance. When two players battle, this service runs combat calculations at 60 ticks per second without touching blockchain or asset services. Only when the match ends and rewards are distributed does it publish a “MatchCompleted” event that triggers the asset registry to mint victory NFTs. This separation keeps gameplay latency under 50ms while blockchain operations take seconds.
Anti-patterns emerge when teams share databases across services. If the marketplace service directly queries the asset registry’s database to check ownership before completing a sale, you have created tight coupling that breaks during schema migrations. Instead, the marketplace should call the asset registry’s API or consume its ownership events. Another common mistake is embedding wallet operations inside game logic—when a player’s transaction fails due to low gas, the game server should not handle retry logic. That responsibility belongs to the blockchain sync service, which specializes in transaction management and nonce tracking.
Separating on-chain versus off-chain responsibilities requires clear contracts. On-chain services (smart contracts) enforce ownership rules and execute irreversible transfers. Off-chain services (microservices) provide fast queries, handle user experience, and prepare transactions for submission. The NFT game smart contract architecture defines what must be on-chain for security, while microservices handle everything else for performance. When a player equips an NFT weapon, the game state service updates immediately for responsive UI, but the blockchain sync service batches the on-chain equipment update every 5 minutes to save gas costs.
What Inter-Service Communication Protocols Work Best for Blockchain Games?
Synchronous REST APIs serve player-facing operations requiring immediate consistency. When a player opens their inventory, the game client calls GET /players/{id}/inventory on the asset registry service, which queries its database and returns results in 30-80 milliseconds. This request-response pattern works because the asset registry maintains an eventually-consistent copy of blockchain state, updated asynchronously. REST’s simplicity and universal HTTP support make it ideal for client-to-service communication where latency budgets allow 100-200ms round trips.
gRPC offers better performance for high-frequency service-to-service calls. The game state service might invoke the player identity service 10,000 times per second to validate session tokens during active gameplay. gRPC’s binary Protocol Buffers encoding reduces payload size by 60% compared to JSON, and HTTP/2 multiplexing eliminates connection overhead. In production benchmarks, gRPC reduces inter-service latency from 15ms to 4ms for token validation calls, directly improving player experience during fast-paced combat.
Event-driven messaging handles NFT minting events and marketplace updates where eventual consistency is acceptable. When a player purchases an NFT, the marketplace transaction service publishes a “NFTPurchased” event to a Kafka topic. Multiple consumers react independently: the asset registry updates ownership, the analytics service records the sale, the notification service emails the seller, and the game state service checks if the purchase unlocked achievements. This decoupling means adding new reactions (like fraud detection) requires no changes to the marketplace service.
RabbitMQ works well for smaller deployments where message volume stays under 50,000 events per second. Its rich routing features let you implement patterns like “send marketplace events to the analytics queue only if the sale price exceeds $100.” RabbitMQ’s built-in retry mechanisms and dead-letter queues handle transient failures gracefully—if the notification service is down, emails queue up and send when it recovers. For NFT games with moderate player bases (under 100,000 daily active users), RabbitMQ’s operational simplicity outweighs Kafka’s raw throughput.
Kafka becomes necessary at scale when blockchain event volume overwhelms traditional message queues. A popular NFT game might process 500,000 Transfer events per day across multiple smart contracts. Kafka’s log-based architecture lets new services replay historical events to rebuild state—when you add a new analytics dashboard, it can consume the past 30 days of marketplace events to populate trend graphs. Kafka’s partitioning also enables horizontal scaling: partition marketplace events by NFT collection address, and each consumer instance processes a subset of collections independently.
WebSocket gateways maintain real-time gameplay connections while preserving microservice isolation. The game client opens a WebSocket to an API gateway, which routes messages to the appropriate game state service instance based on the player’s active match. When the player’s NFT weapon triggers a special ability, the game state service calculates damage and broadcasts updates to all match participants through the gateway. This architecture keeps WebSocket connection management separate from game logic, allowing the gateway to handle 100,000 concurrent connections while game state services focus on simulation.
Cross-service state propagation requires careful consistency management. When a player mints a new NFT, the blockchain sync service detects the Mint event and publishes it to Kafka. The asset registry consumes the event and updates its database, but this happens asynchronously—there is a 2-5 second window where the blockchain shows the NFT but the asset registry does not. The game client must handle this by showing “pending” status until the asset registry confirms ownership. Similar patterns from RPA architecture design patterns apply: idempotent event handlers ensure processing the same Mint event twice does not create duplicate records.
How Does Database Sharding Handle Millions of Player-Owned NFT Assets?
Horizontal partitioning by player ID optimizes the most common query pattern: “show me all NFTs owned by player X.” With 10 million players and 50 million NFT assets, a single PostgreSQL database cannot efficiently index ownership queries. Sharding distributes players across 16 database instances based on a hash of their player ID. Player 12345 always routes to shard 3, where all their assets live. This co-location means inventory queries scan one shard instead of 16, reducing query time from 800ms to 50ms.
The shard key choice creates trade-offs. Sharding by player ID makes inventory queries fast but complicates marketplace listings that need to show “all swords for sale under $100” across all players. That query must scatter-gather across all 16 shards and merge results, introducing latency. The solution is a secondary index service that maintains a global view of marketplace listings, sharded differently—by asset contract address and price range. This polyglot persistence pattern uses the right database structure for each query type.
Sharding by asset contract address serves marketplace queries efficiently. All NFTs from the “CryptoSwords” collection live in shard 7, making “show all swords for sale” a single-shard query. But now “show player X’s inventory” scatters across all shards because their NFTs come from multiple collections. The solution is running both sharding strategies in parallel: the asset registry uses player ID sharding for ownership queries, while the marketplace service uses contract address sharding for listing queries. Each service maintains its own database optimized for its access patterns.
Polyglot persistence means choosing different database technologies for different data types. The asset registry uses PostgreSQL for transactional ownership records where ACID guarantees matter—you cannot have two players owning the same NFT. The social features service uses Neo4j, a graph database, to model friend relationships and guild memberships where traversal queries like “find all guild members who own rare swords” perform 10x faster than relational joins. The analytics service uses TimescaleDB, a time-series database, to efficiently store and query 500 million marketplace price points over 2 years.
NFT metadata storage often uses MongoDB or DynamoDB because metadata schemas vary wildly across collections. One NFT might have attributes like “attack: 50, defense: 30” while another has “rarity: legendary, artist: 0x123.” Document databases handle this schema flexibility without migrations. The metadata service shards by token ID, storing each NFT’s JSON metadata in a document. Queries like “find all NFTs with attack > 40” use secondary indexes on frequently-queried attributes.
Consistency trade-offs between blockchain finality and game database state require careful handling. When a player transfers an NFT, the blockchain transaction enters a pending state for 15-30 seconds until confirmed. The asset registry must decide: update immediately and risk reverting if the transaction fails, or wait for confirmation and show stale data. Production systems typically use a three-state model: “blockchain_pending,” “database_confirmed,” and “fully_synced.” The game UI shows pending transfers with a loading indicator, updates to confirmed when the asset registry processes the blockchain event, and marks fully synced after verifying the blockchain state matches the database.
Replication strategies protect against data loss and improve read performance. Each shard runs a primary database with two read replicas. Write operations (ownership transfers) go to the primary, while read operations (inventory queries) distribute across replicas. This configuration handles 10,000 read queries per second per shard while maintaining single-digit millisecond replication lag. During blockchain network congestion, when ownership changes slow down, the replicas stay perfectly synchronized. During marketplace events, when read queries spike 5x, the replicas absorb the load without impacting write performance.
Which Containerization Approaches Optimize NFT Game Infrastructure Deployment?
Kubernetes orchestration enables auto-scaling based on player load and blockchain event volume. The game state service runs in a Kubernetes Deployment with a Horizontal Pod Autoscaler configured to maintain 70% CPU utilization. When player concurrency jumps from 5,000 to 20,000 during a tournament, Kubernetes automatically scales from 10 pods to 40 pods in under 2 minutes. Each pod handles 500 concurrent game sessions, and the load balancer distributes new connections to the least-loaded pods. This elasticity reduces infrastructure costs by 50% during off-peak hours when Kubernetes scales down to minimum replicas.
The blockchain sync service scales differently—based on event volume rather than player count. A Kubernetes CronJob runs every 60 seconds, queries the pending blockchain event queue depth, and adjusts the sync service replica count. During an NFT drop when 10,000 mints happen in 10 minutes, the queue fills with Transfer events. The autoscaler spins up 20 sync service pods to process events in parallel, each handling a different block range. Once the queue drains, replicas scale back to 3 for normal operation. This event-driven scaling prevents blockchain lag from accumulating during traffic spikes.
Service mesh implementations like Istio add security and observability without code changes. Istio injects a sidecar proxy into each pod, intercepting all network traffic. The marketplace transaction service calls the asset registry service through the proxy, which automatically enforces mutual TLS encryption, validates JWT tokens, and records latency metrics. When the asset registry service has a slow database query, Istio’s distributed tracing shows the exact call chain: marketplace → asset registry → PostgreSQL shard 5 → slow query. This visibility cuts debugging time from hours to minutes.
Linkerd offers a lighter-weight alternative for teams prioritizing simplicity over features. It provides automatic retries, timeouts, and circuit breaking without the complexity of Istio’s full feature set. When the blockchain sync service calls an external Ethereum node that occasionally times out, Linkerd automatically retries with exponential backoff. If the node stays down for 30 seconds, Linkerd opens the circuit breaker and fails fast instead of queuing requests. This resilience prevents cascading failures when external dependencies become unreliable.
CI/CD pipelines must coordinate smart contract upgrades with backend service deployments. A typical pipeline starts with a Git commit that changes both the marketplace smart contract and the marketplace transaction service. The pipeline compiles the contract using Hardhat, runs Slither for security analysis, and deploys to a Sepolia testnet. Simultaneously, it builds a Docker image for the marketplace service and deploys it to a staging Kubernetes cluster. Integration tests verify the new service version correctly calls the upgraded contract’s functions. Only after tests pass does the pipeline deploy the contract to mainnet and roll out the new service to production.
Blue-green deployment strategies minimize downtime during service updates. Kubernetes maintains two identical production environments: blue (current version) and green (new version). When deploying a new asset registry service, Kubernetes spins up green pods running the new code while blue pods continue serving traffic. Health checks verify green pods are healthy, then the load balancer switches all traffic to green in under 1 second. If the new version has bugs, the load balancer switches back to blue instantly. This approach eliminates the 5-10 minute downtime window of traditional rolling updates.
Canary deployments reduce risk for high-stakes changes. When upgrading the blockchain sync service with a new transaction batching algorithm, Kubernetes routes 5% of traffic to the new version while 95% stays on the old version. Monitoring dashboards track error rates and latency for both versions. If the new version shows 0.1% higher error rates, the deployment automatically rolls back. If metrics look good after 30 minutes, Kubernetes gradually shifts traffic to 25%, then 50%, then 100% over 2 hours. This gradual rollout catches issues before they impact all players.
Infrastructure as Code using Terraform or Pulumi ensures reproducible deployments. The entire Kubernetes cluster configuration—node pools, autoscaling rules, service mesh settings, database instances—lives in version-controlled code. To spin up a new environment for testing a major architecture change, engineers run terraform apply and get an identical cluster in 15 minutes. This approach also enables disaster recovery: if the production cluster fails, the same Terraform configuration rebuilds it in a different region. Similar principles apply to compliance-focused architectures like HIPAA compliant blockchain architecture, where infrastructure audit trails matter.
Resource limits and quotas prevent runaway services from consuming all cluster capacity. Each microservice’s Kubernetes manifest specifies CPU and memory requests (guaranteed resources) and limits (maximum allowed). The game state service requests 500m CPU and 1GB RAM per pod, with limits of 2 CPU and 4GB RAM. If a memory leak causes a pod to exceed 4GB, Kubernetes kills and restarts it before it impacts other services. Namespace-level quotas ensure the development team’s test deployments cannot starve production services of resources.
Observability stacks combine Prometheus for metrics, Jaeger for tracing, and Loki for logs. Prometheus scrapes metrics from each microservice every 15 seconds, tracking request rates, error rates, and latency percentiles. When the marketplace transaction service’s p99 latency jumps from 200ms to 2 seconds, Prometheus alerts the on-call engineer. Jaeger’s distributed tracing shows the slow request spent 1.8 seconds waiting for a blockchain RPC call, pointing to the root cause. Loki aggregates logs from all pods, making it easy to search for error messages across the entire system. This unified observability reduces mean time to resolution from 45 minutes to 8 minutes.
Cost optimization in Kubernetes involves right-sizing pods and using spot instances. Production monitoring reveals the asset registry service averages 30% CPU utilization during normal operation. Reducing CPU requests from 1 core to 500m allows Kubernetes to pack twice as many pods per node, cutting infrastructure costs by 35%. For batch workloads like the nightly analytics job that processes marketplace data, Kubernetes can use spot instances that cost 70% less than on-demand instances. If AWS reclaims a spot instance mid-job, Kubernetes reschedules the work to another node automatically.
Multi-region deployments improve latency for global player bases. A game with players in North America, Europe, and Asia runs Kubernetes clusters in three AWS regions. The game client connects to the nearest region’s API gateway, reducing round-trip latency from 200ms to 40ms. Each region runs a complete copy of all microservices, but they share a global blockchain sync service that writes to all regions’ databases. When a player in Tokyo mints an NFT, the sync service updates the Asia cluster’s database immediately and replicates to North America and Europe within 2 seconds. This eventually-consistent multi-region architecture balances latency and data consistency.
Secrets management uses Kubernetes Secrets or external vaults like HashiCorp Vault. Database passwords, blockchain RPC API keys, and JWT signing keys never appear in code or Docker images. Instead, Kubernetes mounts secrets as environment variables or files at runtime. The marketplace transaction service reads its database password from /var/secrets/db-password, which Kubernetes populates from a Secret object. Rotating secrets happens without redeploying services: update the Secret, and Kubernetes restarts pods to load the new value. This approach prevents credential leaks and simplifies compliance with standards similar to blockchain cold chain compliance requirements.
GitOps workflows using ArgoCD or Flux keep Kubernetes state synchronized with Git. All Kubernetes manifests live in a Git repository. When an engineer commits a change to increase the game state service’s replica count from 10 to 15, ArgoCD detects the diff and applies it to the cluster automatically. This declarative approach eliminates configuration drift—the cluster always matches the Git repository. It also provides an audit trail: every infrastructure change has a Git commit showing who made it, when, and why. Rollbacks become as simple as reverting a Git commit.
The integration with Web3 infrastructure layers requires careful service design. The blockchain sync service must handle multiple RPC providers (Infura, Alchemy, QuickNode) with automatic failover. When Infura rate-limits requests, the service switches to Alchemy within 100ms. It also batches RPC calls: instead of making 1,000 individual eth_getTransactionReceipt calls, it uses eth_batchRequest to fetch 100 receipts per call, reducing latency by 90%. These optimizations are critical for maintaining sync performance during blockchain network congestion.
Cross-chain architectures inspired by multi-chain MLM smart contract architecture add complexity. A game supporting Ethereum, Polygon, and Binance Smart Chain runs three separate blockchain sync services, one per chain. Each service publishes events to the same Kafka topics with a “chain” field indicating origin. The asset registry consumes events from all chains and maintains a unified view of cross-chain assets. When a player bridges an NFT from Ethereum to Polygon, the Ethereum sync service publishes a “Burned” event and the Polygon sync service publishes a “Minted” event. The asset registry processes both and updates the NFT’s chain field, maintaining accurate ownership across chains.
Regulatory compliance features, such as those needed for stablecoin regulation framework adherence, fit naturally into microservices architecture. A dedicated compliance service monitors marketplace transactions for suspicious patterns—rapid buying and selling, large volume from new accounts, or price manipulation. This service consumes marketplace events from Kafka, applies machine learning models to detect anomalies, and flags transactions for review. Because it is a separate microservice, adding compliance features does not require changes to the marketplace transaction service, and compliance rules can be updated independently based on evolving regulations.
In conclusion, microservices architecture for NFT games delivers independent scaling, fault isolation, and technology flexibility that monolithic designs cannot match. By decomposing systems into player identity, asset registry, marketplace transactions, game state, and blockchain sync services—each with appropriate database sharding and communication protocols—teams build resilient backends that handle millions of players and blockchain events. Kubernetes orchestration with service meshes, CI/CD pipelines, and multi-region deployments provides the operational foundation for production-grade NFT gaming platforms.
Frequently Asked Questions
Q1.What is the difference between monolithic and microservices architecture for NFT games?
Monolithic architecture runs all game functions—authentication, inventory, marketplace, blockchain integration—in a single codebase and deployment. Microservices split these into independent services that communicate via APIs. For NFT games, microservices enable isolated scaling of high-demand components like minting or trading, faster updates without full redeployment, and fault isolation so a marketplace bug doesn’t crash player authentication or wallet connections.
Q2.How do microservices improve scalability in blockchain-based games?
Microservices let you scale individual components independently. During NFT drops, you scale only the minting service; during tournaments, scale matchmaking and leaderboard services. Each service uses dedicated resources, preventing bottlenecks. Horizontal scaling adds instances per service, load balancers distribute traffic, and stateless design allows dynamic provisioning. This targeted scaling reduces infrastructure costs while handling peak loads efficiently without over-provisioning the entire backend.
Q3.Which database sharding strategy is best for NFT game player inventories?
Range-based sharding by player ID works best for NFT inventories. Partition data into shards (e.g., users 1-100k in shard A, 100k-200k in shard B). This ensures single-shard queries for player assets, minimizing cross-shard joins. Use consistent hashing for even distribution as player base grows. Store NFT metadata references (token IDs, contract addresses) in shards while keeping immutable on-chain data separate, reducing database load and query latency.
Q4.What messaging protocols should NFT games use for real-time asset updates?
Use WebSocket for client-facing real-time updates (inventory changes, marketplace listings) and message queues like RabbitMQ or Apache Kafka for backend service communication. WebSocket maintains persistent connections for instant push notifications. Kafka handles high-throughput event streams—minting events, transfer confirmations, auction bids—with guaranteed delivery and replay capability. Combine both: blockchain listeners publish to Kafka, which triggers WebSocket broadcasts to affected players, ensuring reliable real-time synchronization.
Q5.How does Kubernetes help scale NFT game backend services?
Kubernetes automates container orchestration for microservices. It provides horizontal pod autoscaling based on CPU/memory or custom metrics like transaction queue depth. Rolling updates deploy new service versions without downtime. Service discovery and load balancing route traffic across replicas. For NFT games, Kubernetes schedules resource-intensive blockchain indexing pods separately from lightweight API pods, manages secrets for wallet keys, and ensures high availability through automatic pod restarts and multi-zone deployments.
Q6.Can microservices architecture reduce blockchain transaction costs in games?
Yes, through batching and off-chain optimization. Dedicated microservices aggregate multiple player actions (item crafts, transfers) into single batch transactions, reducing gas fees. Separate services handle off-chain validation and state channels for frequent low-value interactions, only settling final states on-chain. Transaction queue services optimize gas price timing and nonce management. This architectural separation lets you implement cost-saving strategies—Layer 2 integration, meta-transactions, lazy minting—without affecting core gameplay services.
Explore Services
Related Services
Reviewed by

Wazid Khan
Director & Co-Founder
Wazid Khan is the Director & Co-Founder of Nadcab Labs, a forward-thinking digital engineering company specializing in Blockchain, Web3, AI, and enterprise software solutions. With a strong vision for innovation and scalable technology, Wazid has played a key role in building Nadcab Labs into a trusted global technology partner. His expertise lies in strategic planning, business development, and delivering client-centric solutions that drive real-world impact. Under his leadership, the company has successfully delivered numerous projects across industries such as fintech, healthcare, gaming, and logistics. Wazid is passionate about leveraging emerging technologies to create secure, efficient, and future-ready digital ecosystems for businesses worldwide.