Ai Overview
DePIN network architecture defines how decentralized physical infrastructure networks coordinate thousands of independent nodes to deliver storage, compute, wireless connectivity, and sensor services at scale. In a flat architecture where every node participates in consensus, adding 1,000 new edge nodes increases the total messages by roughly 1,000 × (existing node count).
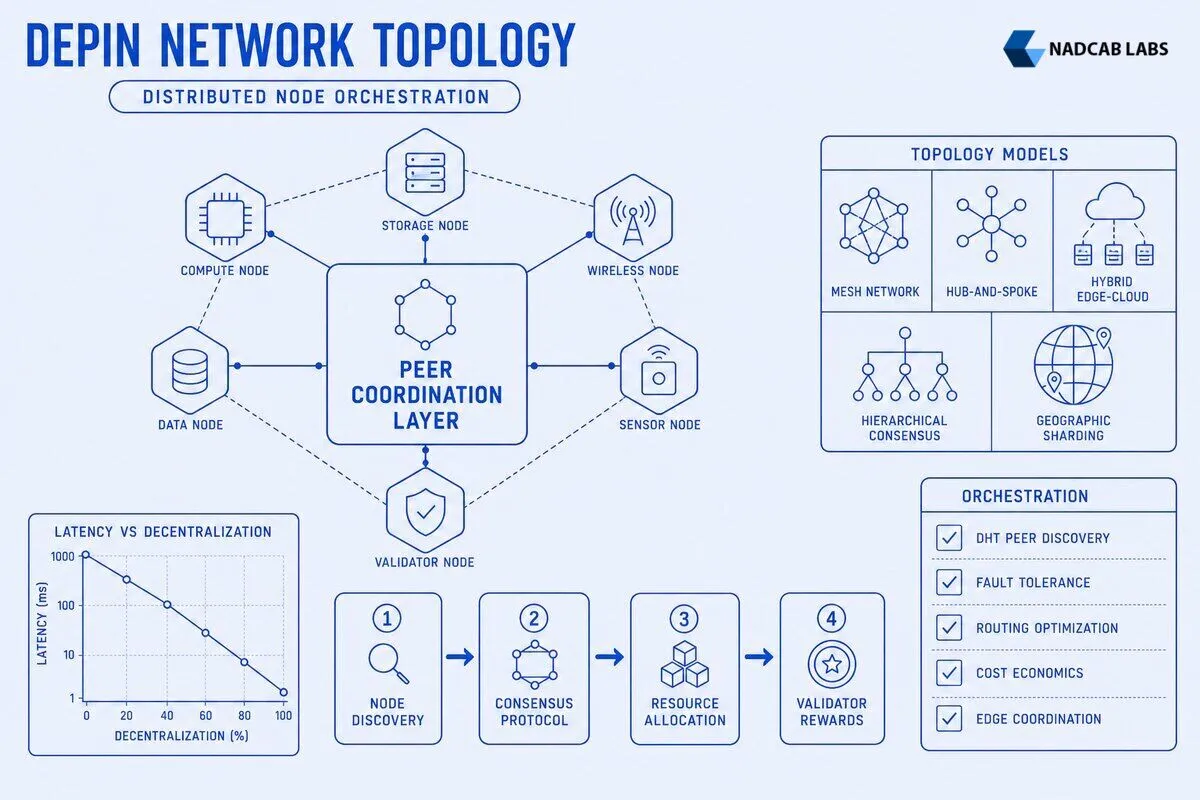
DePIN network architecture defines how decentralized physical infrastructure networks coordinate thousands of independent nodes to deliver storage, compute, wireless connectivity, and sensor services at scale. Unlike traditional cloud architectures that rely on centralized orchestrators, DePIN systems distribute control across peer-to-peer topologies, layered node hierarchies, and hybrid edge-cloud models to balance latency, fault tolerance, and cost. The choice of topology model—hub-and-spoke, mesh, or hybrid—directly impacts resource discovery speed, consensus overhead, and the economics of validator rewards. Effective DePIN system design patterns combine distributed hash tables for peer discovery, hierarchical consensus to reduce communication costs, and geographic data sharding to meet low-latency requirements while preserving decentralization.
Key Takeaways
- Topology choice matters: Mesh topologies maximize fault tolerance but increase routing complexity; hub-and-spoke models reduce latency but introduce single points of failure.
- Layered hierarchies cut overhead: Separating edge nodes, validators, and aggregators allows DePIN networks to scale horizontally without quadratic consensus costs.
- Orchestration patterns vary: Distributed hash tables and gossip protocols enable fully decentralized peer discovery, while federated registries offer faster lookups with moderate centralization.
- Edge-cloud hybrids optimize latency: Placing compute at the edge for real-time workloads and using cloud validators for consensus balances performance with decentralization.
- Architecture drives economics: Node tier, uptime, and bandwidth contribution determine reward distribution, aligning incentives with network health and resource availability.
- Scalability requires sharding: Geographic and functional partitioning of the node fleet prevents bottlenecks and reduces storage and bandwidth costs per validator.
What are the core topology models used in DePIN network architecture?
Physical infrastructure network topology determines how nodes communicate, discover peers, and route requests across the decentralized network. The three primary models—hub-and-spoke, mesh, and hybrid—each offer distinct trade-offs between latency, fault tolerance, and operational complexity.
In a hub-and-spoke topology, a small number of central aggregator nodes coordinate communication between edge nodes. This model minimizes the number of hops required to reach any peer, reducing latency for request routing and resource discovery. Hub nodes act as service registries, maintaining indexes of available resources and forwarding queries to the appropriate edge provider. The main advantage is simplicity: new nodes register with a known hub, and clients query a predictable endpoint. However, hub-and-spoke introduces centralization risk. If a hub node fails or is compromised, the entire spoke cluster loses connectivity until failover mechanisms activate. This pattern works well for DePIN networks that prioritize low-latency lookups and can tolerate moderate centralization, such as decentralized content delivery or IoT sensor aggregation.
A mesh topology eliminates central coordinators by allowing every node to communicate directly with multiple peers. Each node maintains a routing table of neighboring nodes and propagates service advertisements through gossip protocols or flooding. Mesh networks excel at fault tolerance: if one peer fails, requests automatically reroute through alternate paths. This resilience makes mesh topologies ideal for DePIN applications requiring high availability, such as decentralized wireless networks, distributed storage grids, and modern AI app builder platforms that rely on decentralized infrastructure to support scalable and resilient AI-powered services. The downside is increased routing complexity and bandwidth overhead. Every node must process and forward discovery messages, and the number of peer connections grows with network size. Without careful design, mesh topologies can suffer from message storms or slow convergence when the network topology changes frequently.
Hybrid topologies combine elements of both models to balance latency and decentralization. A common pattern uses regional hub nodes to aggregate local edge clusters, while the hubs themselves form a mesh overlay for inter-region communication. This two-tier structure reduces the number of long-distance hops for local requests while preserving global fault tolerance. For example, a decentralized compute network might deploy hub validators in each geographic region to coordinate edge servers, then use a mesh protocol to synchronize state across regions. Hybrid architectures require careful tuning of hub placement and peer selection policies to avoid creating bottlenecks or single points of failure at the regional level.
Overlay networks play a crucial role in all three topologies. An overlay is a logical peer-to-peer network built on top of the physical internet infrastructure, allowing DePIN nodes to discover and route to each other without relying on centralized DNS or IP addressing. Protocols like Kademlia (used in IPFS) or Chord implement distributed hash tables (DHT) that map resource identifiers to node addresses, enabling efficient lookups even in large, dynamic networks. The overlay handles peer discovery, routing table maintenance, and NAT traversal, abstracting the underlying physical topology from the application layer.
| Topology Model | Latency | Fault Tolerance | Bandwidth Overhead | Best Use Case |
|---|---|---|---|---|
| Hub-and-Spoke | Low (1-2 hops) | Moderate (hub SPOF) | Low | CDN, IoT aggregation |
| Mesh | Variable (multi-hop) | High (automatic reroute) | High (gossip flood) | Wireless, storage grids |
| Hybrid (Regional Mesh) | Low (local), Moderate (global) | High (regional failover) | Moderate | Compute, global storage |
Choosing the right topology requires evaluating the DePIN application’s latency tolerance, expected churn rate, and geographic distribution. Networks with stable node sets and regional clustering benefit from hybrid models, while highly dynamic environments with frequent joins and departures favor pure mesh designs. For teams building custom DePIN infrastructure, DePIN Development services can model topology performance under realistic load and churn scenarios before deployment.
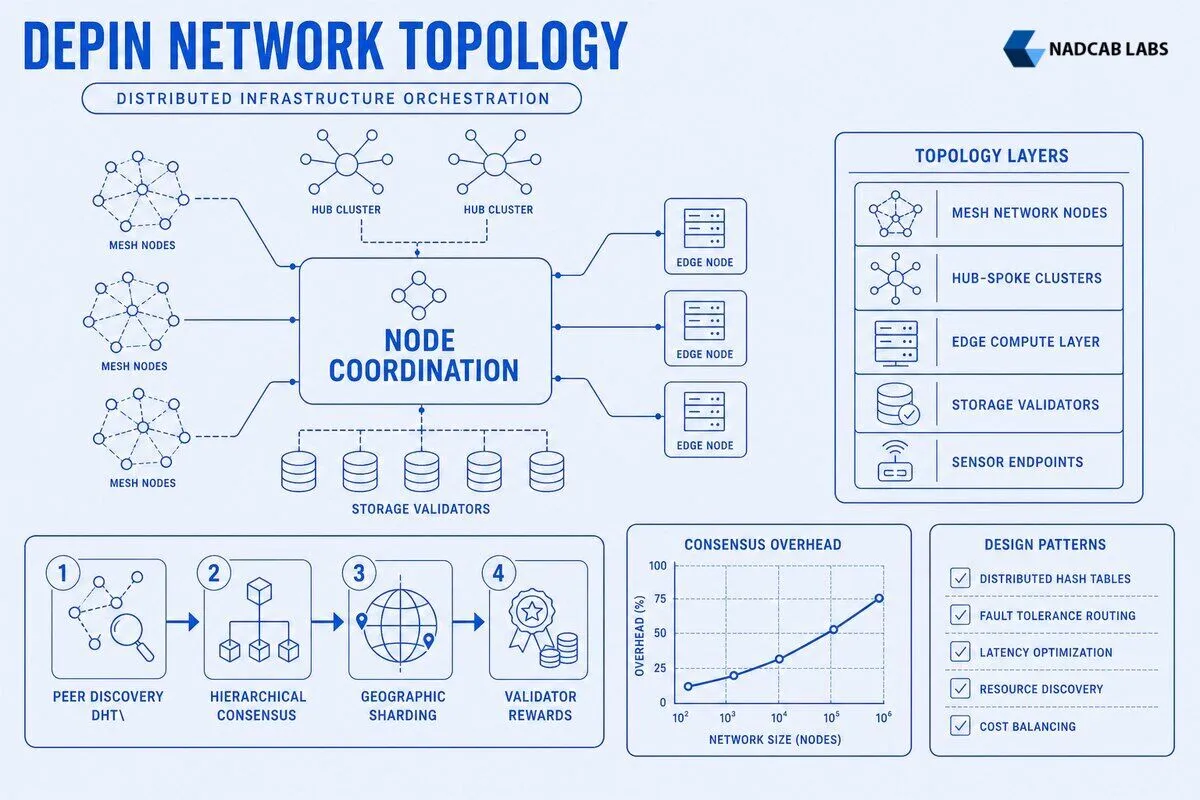
How do layered node hierarchies optimize DePIN resource allocation?
Layered node hierarchies partition the DePIN network into specialized tiers—edge nodes, validator nodes, and aggregator nodes—each with distinct roles, resource requirements, and reward structures. This separation of concerns reduces consensus overhead, improves resource allocation efficiency, and aligns economic incentives with network health.
Edge nodes are the workhorses of the DePIN network, providing the actual physical infrastructure: storage capacity, compute cycles, wireless bandwidth, or sensor data streams. These nodes typically run on consumer-grade hardware or IoT devices with limited CPU, memory, and uptime guarantees. Edge nodes do not participate directly in consensus; instead, they register their available resources with higher-tier validators and respond to client requests. For example, in a decentralized storage network, an edge node might offer 500 GB of disk space and serve file chunks to clients, reporting usage metrics to validators for proof-of-contribution verification. Edge nodes earn rewards proportional to their uptime, bandwidth served, and quality-of-service metrics, creating a direct link between resource provision and token distribution.
Validator nodes form the consensus layer, verifying proofs submitted by edge nodes, finalizing state transitions, and maintaining the canonical ledger of resource allocations and payments. Validators run on more powerful hardware with high availability and low-latency network connections, often in data centers or cloud environments. They execute the consensus protocol—whether proof-of-stake, proof-of-authority, or a hybrid mechanism—to agree on the current state of the network. In hierarchical architectures, validators aggregate proofs from multiple edge nodes within a geographic region or service domain, reducing the total number of messages that must be broadcast network-wide. For instance, a regional validator might collect storage proofs from 100 edge nodes, verify them locally, and submit a single aggregated proof to the global consensus layer. This batching reduces the communication complexity from O(n²) to O(n/k), where k is the number of validators.
Aggregator nodes sit between edge and validator tiers, performing intermediate data processing, caching, and load balancing. Aggregators are optional in some architectures but critical for scaling large node fleets. They collect telemetry from edge nodes, pre-filter invalid proofs, and forward only valid submissions to validators. Aggregators also serve as local service registries, answering client queries for nearby resources without requiring a global DHT lookup. In a decentralized wireless network, an aggregator might manage a cluster of base stations, routing client connections to the least-loaded station and reporting aggregate bandwidth usage to validators. Aggregators earn fees for their coordination work, typically a percentage of the rewards distributed to the edge nodes they manage.
Dynamic node promotion and demotion mechanisms ensure that the hierarchy adapts to changing network conditions. Nodes that consistently meet performance thresholds—measured by uptime, proof accuracy, and stake size—can be promoted from edge to aggregator or from aggregator to validator, increasing their influence and reward share. Conversely, nodes that fail health checks, submit invalid proofs, or go offline for extended periods are demoted or slashed, losing staked tokens and tier privileges. This dynamic adjustment prevents centralization around a fixed validator set while incentivizing continuous infrastructure investment. The promotion criteria are typically encoded in smart contracts, with automatic tier transitions triggered by on-chain performance metrics. For example, an edge node that maintains 99.9% uptime for 90 days and stakes 10,000 tokens might automatically qualify for aggregator status.
Node Tier Promotion Process
Provide resources
Track uptime
Meet threshold
Lock collateral
Verify 99%+ uptime
Validate proofs
Coordinate cluster
Earn coordination fees
Hierarchical consensus reduces the total message complexity and bandwidth requirements for large DePIN networks. In a flat architecture where every node participates in consensus, adding 1,000 new edge nodes increases the total messages by roughly 1,000 × (existing node count). In a three-tier hierarchy with 10 validators, 100 aggregators, and 10,000 edge nodes, only the validators exchange consensus messages, keeping communication overhead constant as edge nodes scale. This architectural pattern is essential for networks targeting millions of devices, such as decentralized sensor grids or global wireless infrastructure. Teams designing similar systems can explore private blockchain architecture design patterns that apply hierarchical consensus to enterprise use cases.
Which orchestration patterns handle node discovery and service registration?
Node discovery and service registration are foundational orchestration challenges in DePIN network architecture. Without a central directory, nodes must autonomously find peers, advertise their capabilities, and maintain up-to-date routing information as the network topology changes. Three primary patterns—distributed hash tables (DHT), gossip protocols, and federated registries—offer different trade-offs between decentralization, lookup speed, and operational complexity.
Distributed hash tables map resource identifiers to node addresses using a consistent hashing scheme that distributes responsibility across all participants. Each node stores a portion of the global routing table and forwards lookup queries to the peer closest to the target identifier. DHT protocols like Kademlia, Chord, or Pastry guarantee that any resource can be located in O(log n) hops, where n is the total number of nodes. When a new edge node joins the network, it generates a unique node ID, queries the DHT to find its position in the keyspace, and announces its available services (storage capacity, compute specs, geographic location) to the responsible DHT nodes. Clients looking for a specific resource—say, 100 GB of storage in the US-West region—hash the query parameters to produce a lookup key, then traverse the DHT to retrieve a list of matching providers. DHTs excel at full decentralization and resilience: no single node controls the directory, and the network self-heals as nodes join or leave. However, DHT lookups incur latency due to multi-hop routing, and the protocol generates significant background traffic for routing table maintenance, especially in high-churn environments.
Gossip protocols propagate service advertisements through epidemic-style message flooding. Each node periodically broadcasts its current state—available resources, pricing, uptime statistics—to a random subset of peers, who in turn forward the message to their neighbors. Over multiple rounds, the advertisement reaches all reachable nodes with high probability. Gossip is simple to implement and highly fault-tolerant: even if 50% of nodes fail simultaneously, the remaining nodes continue to exchange state and eventually converge on a consistent view. The downside is bandwidth overhead and eventual consistency. In a network with 10,000 nodes, a single service update might generate tens of thousands of redundant messages before full propagation. Gossip works best for small to medium-sized DePIN networks (hundreds to low thousands of nodes) or for propagating infrequent updates like validator set changes or protocol upgrades.
Federated service registries strike a middle ground by delegating discovery to a small set of semi-trusted registry nodes. Each registry maintains an index of available services within its domain (geographic region, service type, or stake tier) and synchronizes with peer registries using a consensus protocol. Clients query the nearest registry for resource lookups, receiving results in a single round-trip with minimal latency. Registry nodes can be elected by stake, rotated periodically, or operated by reputable network participants. This pattern reduces lookup latency and bandwidth overhead compared to DHTs and gossip, but introduces moderate centralization risk. If all registries in a region go offline, clients in that region lose discovery capability until the registries recover. Federated registries are common in DePIN networks that prioritize low-latency client experience and can tolerate temporary regional outages, such as decentralized compute marketplaces or real-time sensor data feeds.
Health-check mechanisms ensure that registered services remain available and meet quality standards. Nodes periodically submit heartbeat messages or proofs-of-uptime to the discovery layer, and entries are automatically removed if a node fails to respond within a timeout window. More sophisticated health checks include active probing: a validator or aggregator sends test requests to edge nodes and measures response time, error rate, and data integrity. Nodes that consistently fail health checks are flagged as unreliable and deprioritized in client routing decisions. Automatic failover strategies complement health checks by redirecting client requests to backup nodes when the primary provider becomes unavailable. For example, a decentralized storage client might maintain a list of three replica nodes for each file chunk; if the first node times out, the client immediately retries with the second node without waiting for the full timeout period. Failover policies can be encoded in smart contracts or implemented in client-side SDKs, depending on the desired level of decentralization.
| Orchestration Pattern | Lookup Latency | Decentralization | Bandwidth Overhead | Best For |
|---|---|---|---|---|
| DHT (Kademlia) | O(log n) hops (~150ms) | Full (no SPOF) | Moderate (routing table sync) | Large, stable networks |
| Gossip Protocol | Variable (eventual) | Full (epidemic spread) | High (redundant floods) | Small networks, infrequent updates |
| Federated Registry | Single query (~20ms) | Moderate (trusted registries) | Low (direct lookup) | Low-latency, regional services |
Hybrid orchestration architectures combine multiple patterns to optimize for different query types. A DePIN network might use a DHT for global resource discovery and a local gossip protocol within each regional cluster for rapid state synchronization. Clients first query the DHT to find the nearest regional cluster, then use gossip to locate the best-performing node within that cluster. This layered approach minimizes wide-area network traffic while preserving fast local lookups. For applications requiring real-world asset tracking or geographic routing, concepts from Real Estate Tokenization Explained demonstrate how location metadata and ownership records integrate with decentralized registries.
What edge-cloud hybrid models balance latency and decentralization?
Edge-cloud hybrid models distribute DePIN workloads between low-latency edge nodes close to end-users and high-availability cloud validators that handle consensus and state finalization. This architectural pattern addresses the fundamental tension in decentralized infrastructure: edge compute delivers the millisecond response times required for real-time applications, while cloud consensus provides the security and consistency guarantees needed for trustless coordination.
In a typical hybrid deployment, edge compute nodes run on user-operated hardware—home servers, IoT gateways, or small data centers—located in residential or enterprise environments. These nodes handle latency-sensitive tasks like video transcoding, AI inference, sensor data aggregation, or CDN caching. Because edge nodes are geographically distributed and close to clients, they achieve sub-50ms response times, comparable to centralized cloud regions. However, edge nodes have limited uptime guarantees, variable network connectivity, and potential security vulnerabilities due to physical access by untrusted operators. They are not suitable for running consensus protocols or storing canonical state.
Cloud validators operate in professional data centers with redundant power, high-bandwidth connectivity, and 24/7 monitoring. They execute the consensus protocol, verify proofs submitted by edge nodes, and maintain the authoritative ledger of resource allocations, payments, and slashing events. Validators do not serve client requests directly; instead, they act as a trust anchor, ensuring that edge nodes cannot cheat by reporting false usage metrics or withholding data. When a client requests a compute job, the request is routed to the nearest edge node for execution. The edge node performs the work, generates a proof (cryptographic hash, zero-knowledge proof, or trusted execution environment attestation), and submits the proof to a cloud validator. The validator verifies the proof, records the work on-chain, and triggers the corresponding token reward. This separation of concerns allows the network to scale horizontally by adding more edge nodes without increasing the consensus load on validators.
Data locality patterns are critical for optimizing hybrid architectures. Caching stores frequently accessed data at the edge to reduce latency and bandwidth costs. For example, a decentralized video streaming network might cache popular video chunks on edge nodes in each city, while storing the full archive on cloud storage backends. Replication duplicates data across multiple edge nodes to ensure availability even if some nodes go offline. A decentralized storage network typically maintains three to five replicas of each file chunk, distributed across different geographic regions and network operators to prevent correlated failures. Sharding partitions the dataset across nodes based on geographic region, content type, or user cohort, reducing the total storage and bandwidth required per node. A global DePIN network might shard data by continent, with European edge nodes storing European user data and Asian nodes storing Asian data, minimizing cross-region traffic.
Cost and performance trade-offs between on-premise edge hardware and cloud infrastructure depend on the application’s resource profile and revenue model. Edge nodes have high upfront capital costs (purchasing servers, networking equipment) but low recurring costs (residential electricity, consumer internet). Cloud validators incur ongoing operational expenses (data center rent, enterprise bandwidth, redundant infrastructure) but require minimal capital investment. For DePIN networks with high transaction volumes and stable revenue, operating dedicated cloud validators can be more cost-effective than renting cloud instances from AWS or Azure. For early-stage networks with uncertain demand, using cloud providers for validators and incentivizing community-run edge nodes reduces financial risk. The optimal mix depends on the ratio of compute cost to consensus cost: applications with heavy compute workloads (video rendering, AI training) benefit from maximizing edge deployment, while applications with light compute but frequent state updates (IoT telemetry, financial transactions) benefit from robust cloud consensus.
Edge-Cloud Workload Distribution
Geographic data sharding reduces cross-region bandwidth costs and improves compliance with data sovereignty regulations. By partitioning the network into regional clusters, each cluster can operate semi-independently, synchronizing only aggregate state with the global consensus layer. For example, a decentralized compute network might deploy separate validator sets in North America, Europe, and Asia, with each set responsible for verifying proofs from edge nodes in its region. Regional validators periodically submit merkle roots of their local state to a global coordinator, which maintains a unified view of the entire network. This architecture reduces the total inter-region bandwidth by 80-90% compared to a fully global consensus model, while preserving the ability to audit and verify any regional cluster’s state. For insights into how tokenized assets leverage similar geographic partitioning, see RWA tokenization smart contract architecture, which covers multi-jurisdiction compliance and state synchronization patterns.
How do architectural choices impact scalability and validator economics?
Architectural decisions—topology model, node hierarchy, consensus mechanism, and data partitioning strategy—directly determine a DePIN network’s scalability ceiling and the economic viability of operating validator and edge nodes. Poorly designed architectures create bottlenecks that prevent horizontal scaling, while misaligned incentives cause validator centralization or edge node churn.
Horizontal scaling via sharding and partitioning is the primary strategy for growing DePIN networks beyond a few thousand nodes. Sharding divides the network into independent partitions, each responsible for a subset of the total workload. In a decentralized storage network, sharding might partition files by content hash prefix: nodes with IDs starting with 0x00-0x0F store files in that range, while nodes with IDs 0x10-0x1F store a different range. Each shard operates its own consensus protocol, reducing the per-shard communication complexity to O(n/k), where k is the number of shards. Sharding enables near-linear scalability: doubling the number of shards doubles the network’s total throughput and storage capacity. However, cross-shard operations (retrieving a file stored across multiple shards, coordinating a multi-region compute job) require additional coordination overhead and can become bottlenecks if not carefully managed. Effective sharding strategies co-locate related data within the same shard and minimize cross-shard dependencies.
Bandwidth and storage optimization techniques reduce the operational costs for validators and edge nodes, improving the network’s economic sustainability. Data compression reduces the size of proofs, state snapshots, and peer-to-peer messages, cutting bandwidth usage by 40-70% depending on the data type. Erasure coding allows storage networks to achieve the same redundancy level with less total storage: instead of storing three full replicas of a file (3× storage cost), the network can encode the file into five fragments where any three fragments reconstruct the original (1.67× storage cost). Lazy state synchronization reduces the bandwidth required for new validators to join the network by allowing them to download only recent state and fetch historical data on-demand. These optimizations directly impact validator economics: a validator that can reduce bandwidth costs from $500/month to $150/month can operate profitably at lower transaction volumes, increasing the network’s decentralization by enabling smaller operators to participate.
Alignment of architecture with tokenomics ensures that reward distribution incentivizes the desired network behavior. In a hierarchical architecture, edge nodes earn rewards proportional to the resources they contribute (storage capacity, bandwidth served, compute hours) and their uptime percentage. Validators earn transaction fees and block rewards for processing consensus, with rewards scaled by their stake size and historical performance. Aggregators earn a percentage of the rewards flowing through their cluster, creating an incentive to recruit high-quality edge nodes and maintain low cluster-wide failure rates. The tokenomics model must account for the different cost structures of each tier: edge nodes have low ongoing costs but high capital costs, so rewards should be front-loaded to compensate for hardware investment. Validators have high ongoing costs but low capital costs, so rewards should be stable and predictable to support long-term operational planning. For detailed guidance on designing incentive structures that align with network architecture, refer to DePIN tokenomics design frameworks that model supply curves, vesting schedules, and reward decay functions.
| Node Tier | Primary Cost | Reward Structure | Typical Monthly Earnings |
|---|---|---|---|
| Edge Node | Hardware ($800-$2,000) | Per-GB, per-hour, uptime bonus | $50-$300 |
| Aggregator | Bandwidth ($100-$400/mo) | Coordination fee (5-10% of cluster) | $400-$1,500 |
| Validator | Hosting ($300-$1,200/mo) | Block rewards + tx fees | $1,000-$8,000 |
Scalability bottlenecks often emerge at the consensus layer when the network grows beyond the design capacity. If every validator must process every transaction, throughput is limited by the slowest validator’s processing speed. Hierarchical consensus and sharding decouple transaction throughput from the number of validators, allowing the network to scale by adding more shards or regional clusters rather than upgrading validator hardware. However, this introduces complexity in cross-shard coordination and state synchronization. Architectural patterns from high-frequency trading systems, such as those described in order matching engine architecture, offer lessons in partitioning order books and coordinating distributed state machines under strict latency constraints.
Validator economics also depend on the choice of consensus mechanism. Proof-of-stake validators must lock capital in staked tokens, creating an opportunity cost that must be offset by staking rewards. Proof-of-work validators incur electricity and hardware depreciation costs. Hybrid mechanisms like proof-of-spacetime (used in decentralized storage) or proof-of-coverage (used in wireless networks) require validators to prove they are storing data or providing wireless coverage, aligning validator incentives with the network’s service delivery. The optimal consensus mechanism depends on the DePIN application’s trust model, latency requirements, and energy budget. For networks targeting enterprise adoption, proof-of-authority or delegated proof-of-stake may offer better performance and regulatory compliance, while community-driven networks may prioritize permissionless participation through proof-of-work or proof-of-stake. Concepts from token vesting smart contract architecture can be applied to lock validator stakes and enforce slashing conditions programmatically, reducing the need for manual governance interventions.
Finally, architectural choices affect the network’s ability to integrate with external data sources and off-chain infrastructure. DePIN networks that provide sensor data, geolocation services, or real-world asset tracking must bridge on-chain state with off-chain telemetry. Oracle architectures, trusted execution environments, and cryptographic attestation schemes enable validators to verify off-chain data without trusting individual edge nodes. For teams building DePIN applications that combine machine learning inference with decentralized compute, Data Science and ML Model Development Services can design inference pipelines that run on edge nodes and submit verifiable predictions to validators, ensuring that AI models remain auditable and tamper-resistant even when executed on untrusted hardware.
Designing a scalable, economically sustainable DePIN network architecture requires balancing decentralization, latency, fault tolerance, and operational costs across multiple layers. Topology models determine how nodes discover and route to each other. Layered hierarchies reduce consensus overhead and enable horizontal scaling. Orchestration patterns handle peer discovery and service registration with varying trade-offs between latency and decentralization. Edge-cloud hybrid models optimize for low-latency workloads while preserving trustless consensus. Architectural choices directly impact validator economics and the network’s ability to scale to millions of nodes. By applying these design patterns systematically and aligning incentives with network health, DePIN builders can create infrastructure networks that deliver decentralized services at cloud-scale performance and cost.
Frequently Asked Questions
Q1.What is the difference between hub-and-spoke and mesh topology in DePIN networks?
Hub-and-spoke routes all traffic through central relay nodes, simplifying management but creating single points of failure. Mesh topology connects nodes peer-to-peer, offering redundancy and resilience but increasing routing complexity and bandwidth overhead. DePIN networks often use hybrid models: mesh for critical validator communication, hub-and-spoke for edge device aggregation, balancing fault tolerance with operational efficiency.
Q2.How does node orchestration work in decentralized physical infrastructure?
Node orchestration in DePIN uses smart contracts and distributed schedulers to assign tasks, allocate resources, and manage lifecycle events across physical nodes. Orchestrators monitor node health, enforce SLA compliance, trigger failover, and distribute workloads based on geographic proximity, capacity, and stake. Kubernetes-like control planes adapted for blockchain governance automate deployment, scaling, and reward distribution without central authority.
Q3.Which DePIN architecture pattern is best for low-latency applications?
Edge-first mesh architectures minimize latency by processing data locally and routing peer-to-peer without central hops. Layered hierarchies with regional aggregators reduce consensus latency while maintaining decentralization. For real-time IoT or streaming, DePIN designs prioritize direct node-to-node communication, off-chain state channels for instant settlement, and geographic clustering to keep critical paths under 50ms round-trip time.
Q4.How do layered node hierarchies reduce consensus overhead in DePIN?
Layered hierarchies partition nodes into tiers: edge devices collect data, regional validators aggregate and verify locally, and global consensus nodes finalize state. Only summarized proofs propagate upward, reducing message volume and validator compute. This sharding-like approach limits full-network broadcasts, enabling DePIN to scale to millions of devices while maintaining sub-second finality for critical transactions.
Q5.What are the trade-offs of edge-cloud hybrid models in DePIN design?
Edge-cloud hybrids balance local processing speed with cloud-scale analytics and redundancy. Edge nodes deliver low latency and privacy but have limited compute and storage. Cloud aggregators provide elasticity and machine learning but introduce centralization risk and higher costs. DePIN designs must carefully partition workloads, use cryptographic proofs to verify edge results, and ensure cloud components remain permissionless and auditable.
Q6.How does DePIN network architecture affect validator rewards and economics?
Architecture determines reward distribution: mesh topologies reward all active relays, hub models concentrate earnings on gateway operators. Layered hierarchies allocate higher rewards to regional validators handling aggregation complexity. Edge nodes earn for data provision, validators for consensus work. Topology choices influence token velocity, staking requirements, and profitability per node class, shaping long-term economic sustainability and participation incentives.
Explore Services
Related Services
Reviewed by

Naman Singh
Co-Founder & CEO, Nadcab Labs
Naman Singh is the Co-Founder and CEO of Nadcab Labs, where he drives the company’s vision, global growth, and strategic expansion in blockchain, fintech, and digital transformation. A serial entrepreneur, Naman brings deep hands-on experience in building, scaling, and commercializing technology-driven businesses. At Nadcab Labs, Naman works closely with enterprises, governments, and startups to design and implement secure, scalable, and business-ready Web3 and blockchain solutions. He specializes in transforming complex ideas into high-impact digital products aligned with real business objectives. Naman has led the development of end-to-end blockchain ecosystems, including token creation, smart contracts, DeFi and NFT platforms, payment infrastructures, and decentralized applications. His expertise extends to tokenomics design, regulatory alignment, compliance strategy, and go-to-market planning—helping projects become investor-ready and built for long-term sustainability. With a strong focus on real-world adoption, Naman believes in building blockchain solutions that deliver measurable value, solve practical problems, and unlock new growth opportunities for organizations worldwide.