Ai Overview
A high-performance order matching engine is the beating heart of any centralized cryptocurrency exchange, responsible for pairing buy and sell orders in real time with sub-millisecond latency. In 2026, designing this architecture demands careful selection of matching algorithms, in-memory data structures, and failover strategies to handle millions of trades per second while maintaining fairness and uptime.
A high-performance order matching engine is the beating heart of any centralized cryptocurrency exchange, responsible for pairing buy and sell orders in real time with sub-millisecond latency. In 2026, designing this architecture demands careful selection of matching algorithms, in-memory data structures, and failover strategies to handle millions of trades per second while maintaining fairness and uptime. This guide walks you through the core components, algorithm trade-offs, optimization techniques, and disaster recovery patterns that power the world’s fastest trading platforms.
Key Takeaways
- Modern matching engines rely on in-memory order books built with red-black trees or skip lists for O(log n) insert and delete operations.
- Price-time priority (FIFO) ensures fairness for retail spot markets, while pro-rata matching optimizes liquidity allocation for derivatives and institutional trading.
- Lock-free concurrent queues and cache-aligned memory layouts eliminate thread contention, delivering consistent sub-millisecond tick-to-trade latency.
- Hot-standby replicas with Raft or Paxos consensus, combined with event sourcing, enable zero-downtime failover and instant disaster recovery.
- Synthetic load testing and horizontal sharding by symbol or order type are essential for scaling to high-frequency trading volumes without performance degradation.
- Benchmark 99th percentile latency and jitter under peak load to validate your architecture against real-world trading stress.
What Are the Core Components of a Modern Order Matching Engine Architecture in 2026?
Every high-performance matching engine consists of three tightly coupled subsystems: the order book manager, the matching logic processor, and the trade settlement pipeline. The order book manager maintains separate bid and ask queues in memory, typically implemented as red-black trees or skip lists. These self-balancing data structures guarantee O(log n) time complexity for insertions, deletions, and price-level lookups, even when the order book contains hundreds of thousands of resting orders. Red-black trees offer predictable worst-case performance, while skip lists provide simpler lock-free implementations with probabilistic balancing—choose based on your concurrency model and latency budget.
The matching logic processor sits at the core, executing the selected algorithm (FIFO, pro-rata, or hybrid) whenever a new order arrives. It scans the opposite side of the book, identifies eligible counterparties, and generates fill events. In 2026, leading exchanges run this logic on CPU-pinned threads with isolated cores to avoid scheduler interference. The processor also enforces business rules: self-trade prevention, minimum order sizes, maximum position limits, and circuit breakers that halt trading during extreme volatility. These rules must execute inline without blocking the critical path, so pre-computed bitmaps and branch-prediction-friendly code paths are common optimizations.
The trade settlement pipeline handles post-match operations: validating fill quantities, updating user balances in the account ledger, publishing trade events to downstream systems (risk management, market data feeds, audit logs), and acknowledging order confirmations back to clients. This pipeline often runs asynchronously to decouple latency-sensitive matching from slower I/O operations. Event-driven architectures using message queues (Kafka, NATS) are standard, allowing each subsystem to scale independently. For example, a Cryptocurrency Exchange Development Company might deploy separate microservices for balance updates and market data distribution, each consuming the same trade event stream at different rates.
| Component | Data Structure | Typical Latency | Concurrency Model |
|---|---|---|---|
| Order Book Manager | Red-black tree / Skip list | 50–200 microseconds | Lock-free or single-writer |
| Matching Logic Processor | Priority queue + hash map | 20–100 microseconds | CPU-pinned thread |
| Trade Settlement Pipeline | Event log (append-only) | 200–500 microseconds | Async message queue |
| Account Ledger | In-memory hash table | 100–300 microseconds | Optimistic locking |
Separation of concerns is critical. The matching engine should never perform blocking database writes or network calls in the hot path. Instead, persist state changes to an append-only event log (event sourcing), then replay that log asynchronously to update durable storage. This pattern, borrowed from high-frequency trading systems, ensures the matching thread remains deterministic and jitter-free. When integrated with market making algorithm architecture design, the same event stream feeds real-time pricing models and liquidity provision strategies.
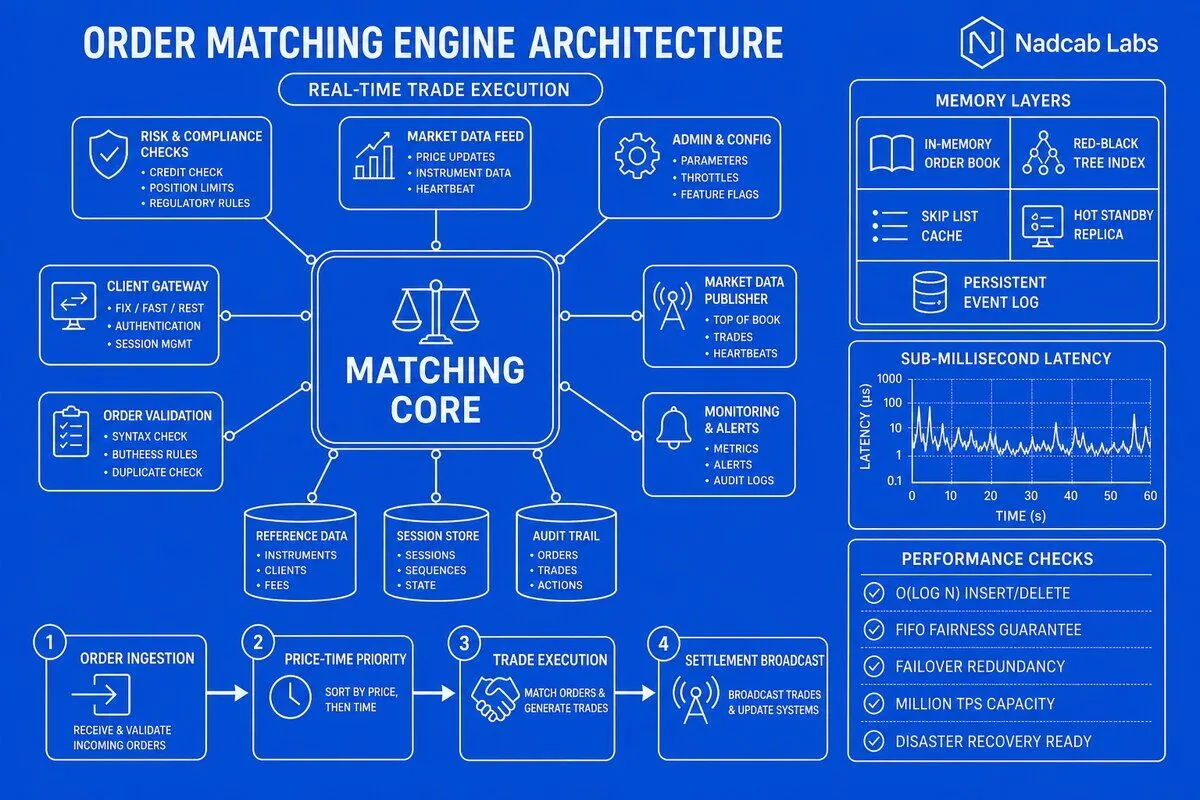
Which Order Matching Algorithms Should You Implement for Different Trading Scenarios in 2026?
Price-time priority, commonly known as FIFO (first in, first out), is the fairest and most transparent algorithm for retail spot markets. Orders at the same price level execute in strict timestamp order: the earliest order gets filled first. This simplicity builds trust with retail traders and satisfies regulatory requirements for best execution. However, FIFO demands nanosecond-precision timestamps and strict clock synchronization across all gateway servers. In 2026, exchanges use hardware timestamping (NIC-level or FPGA-based) to eliminate software stack latency and prevent timestamp manipulation. FIFO also incentivizes latency arbitrage—high-frequency traders invest heavily in co-location and microwave links to gain microsecond advantages, which can crowd out slower participants.
Pro-rata matching allocates fills proportionally to order size at each price level, rewarding liquidity providers who post large resting orders. If three market makers have orders of 100, 200, and 300 units at the best bid, an incoming 600-unit sell order fills them 100, 200, and 300 units respectively (proportional to their contribution). This algorithm is prevalent in derivatives markets and institutional trading venues, where deep liquidity and tight spreads matter more than timestamp fairness. Pro-rata reduces the winner-take-all dynamics of FIFO, encouraging multiple participants to quote competitively. The downside is complexity: you must handle fractional fills, round-off errors, and minimum fill quantities. Some exchanges use a hybrid “top-of-book FIFO, rest pro-rata” model to balance fairness and liquidity incentives.
Time-weighted and hybrid models blend FIFO and pro-rata based on order age or trader tier. For example, orders resting longer than a threshold (say, 100 milliseconds) might receive priority over newer orders, even if the newer order is larger. This discourages quote-stuffing and rewards passive liquidity. Another variant is maker-taker tiering: designated market makers receive preferential allocation in exchange for tighter spreads and continuous quoting obligations. In 2026, exchanges increasingly customize matching logic per symbol or contract type, running different algorithms on the same engine. This requires a pluggable algorithm interface and careful testing to avoid unintended arbitrage opportunities between symbols.
Order Matching Algorithm Decision Flow
Choosing the right algorithm requires understanding your user base and market structure. A P2P exchange escrow smart contract architecture might use simple FIFO for transparency, while a professional derivatives platform needs pro-rata to attract institutional liquidity. Test each algorithm under realistic order flow—run Monte Carlo simulations with historical trade data to measure fill rates, spread impact, and latency distribution. Document the trade-offs clearly in your exchange’s rulebook so traders can optimize their strategies accordingly.
How Do You Optimize In-Memory Data Structures for Sub-Millisecond Latency in 2026?
Lock-free concurrent queues are the foundation of low-latency matching engines. Traditional mutexes introduce unpredictable blocking: if one thread holds a lock and gets preempted by the OS scheduler, all other threads stall. Lock-free data structures use atomic compare-and-swap (CAS) operations to coordinate updates without blocking. For example, a lock-free queue might use a head pointer and a tail pointer, both updated atomically. Threads retry CAS operations in a tight loop until they succeed, eliminating kernel-level context switches. In 2026, mature libraries like Boost.Lockfree and Intel TBB provide production-ready implementations, but many exchanges still hand-roll custom structures to squeeze out every nanosecond.
Cache-aligned memory layouts prevent false sharing—a subtle performance killer where two threads modify adjacent memory locations that happen to share the same CPU cache line. When one thread writes, the entire cache line is invalidated on other cores, forcing expensive memory synchronization. The fix is to pad data structures so each frequently updated field occupies its own cache line (typically 64 bytes on x86). Modern C++ compilers support alignas(64) attributes, and Rust has #[repr(align(64))]. Combine this with CPU pinning: bind each matching thread to a dedicated physical core, disable hyperthreading, and isolate those cores from OS interrupts using kernel boot parameters (e.g., isolcpus on Linux). This setup delivers deterministic latency with minimal jitter.
Benchmark-driven tuning is non-negotiable. Measure tick-to-trade latency—the time from receiving an order to publishing a fill event—under peak load. Use hardware performance counters (Intel VTune, Linux perf) to identify cache misses, branch mispredictions, and memory stalls. A common mistake is optimizing for average latency when 99th percentile latency matters more: a single slow operation can cascade into order queue buildup and missed arbitrage opportunities. Profile your code with realistic order distributions (Pareto-distributed sizes, bursty arrival patterns) and stress-test with synthetic load generators that replay historical tick data at 10x speed. Tools like Gatling and Locust can simulate millions of concurrent WebSocket connections, but custom C++ or Rust harnesses often provide tighter control.
Latency Reduction Techniques (Impact on 99th Percentile)
Zero-copy networking with kernel bypass (DPDK, Solarflare) eliminates system call overhead by mapping NIC buffers directly into user space. This technique is standard in high-frequency trading but adds operational complexity—you lose standard TCP/IP tooling and must implement your own congestion control. For most exchanges, optimizing the application layer first (data structures, algorithms) yields better ROI than exotic networking. When latency targets drop below 10 microseconds, consider FPGA-based matching engines that execute the entire order book in hardware. Firms like Exegy and Enyx offer turnkey FPGA solutions, though they require specialized VHDL or Verilog skills to customize. For broader context on system design trade-offs, see our guide on private blockchain architecture design patterns, which shares similar principles around deterministic performance and fault isolation.
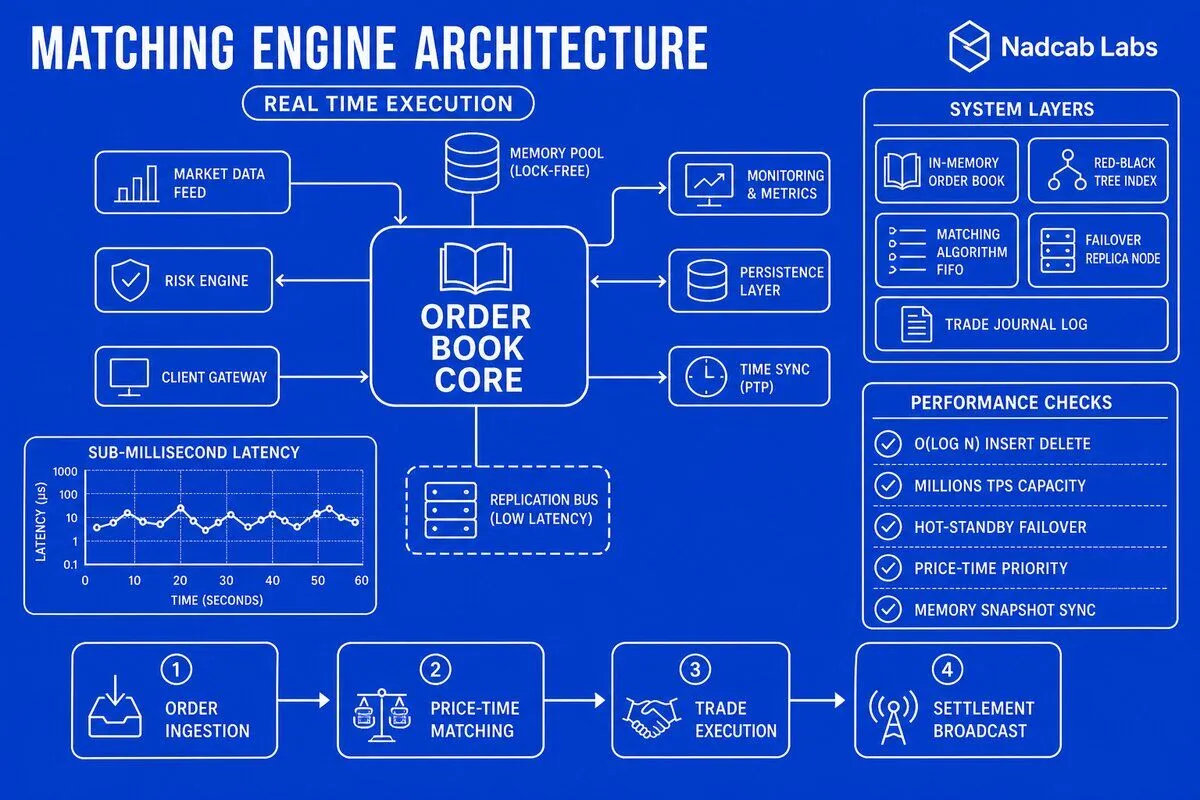
What Failover and Disaster Recovery Strategies Ensure Matching Engine Uptime in 2026?
Hot-standby replicas with state synchronization are the gold standard for high-availability matching engines. The primary engine processes all orders and replicates every state change (order inserts, fills, cancellations) to one or more standby replicas in real time. If the primary fails, a standby promotes itself to primary within milliseconds and resumes processing without data loss. Raft and Paxos are proven consensus algorithms for this pattern: they guarantee that all replicas agree on the order of operations, even in the presence of network partitions or partial failures. Raft is easier to implement and reason about, while Multi-Paxos offers slightly lower latency for write-heavy workloads. In 2026, many exchanges use etcd or Consul (both Raft-based) to manage leader election and configuration, then stream order events over a separate high-throughput channel.
Event sourcing and snapshot recovery enable zero-downtime restarts. Instead of persisting the current order book state to a database after every trade, the engine appends every command (place order, cancel order, fill) to an immutable event log. To recover, a new instance replays the log from the beginning, reconstructing the in-memory order book. Snapshots—periodic checkpoints of the full order book—speed up recovery by allowing replay from the most recent snapshot rather than the entire history. For example, snapshot every 10,000 events; on restart, load the snapshot and replay the last few thousand events. This approach also simplifies auditing and regulatory compliance: the event log is a complete, tamper-proof record of all trading activity. Combine event sourcing with crypto payment gateway security architecture principles—encrypt logs at rest, sign events cryptographically, and replicate across geographically distributed data centers.
Geographic redundancy and circuit breakers isolate cascading failures. Deploy matching engine clusters in multiple AWS regions or on-premises data centers, each with its own order book replica. Route user traffic to the nearest cluster for low latency, but allow instant failover to a remote cluster if a region goes down. Circuit breakers monitor system health metrics (CPU usage, queue depth, error rates) and automatically halt trading if thresholds are breached. For example, if the matching engine’s processing queue exceeds 10,000 pending orders, stop accepting new orders until the backlog clears. This prevents a slow degradation from spiraling into a full outage. Modern observability stacks (Prometheus, Grafana, Datadog) make it easy to define these rules and trigger automated remediation workflows.
| Strategy | Failover Time | Data Loss Risk | Complexity |
|---|---|---|---|
| Hot-standby (Raft) | 1–5 seconds | Zero (replicated log) | High |
| Warm-standby (periodic sync) | 10–30 seconds | Last sync interval | Medium |
| Cold-standby (manual restart) | 5–15 minutes | Depends on snapshot age | Low |
| Geographic multi-master | Sub-second (automatic) | Zero (conflict resolution) | Very High |
Test your disaster recovery plan regularly. Run chaos engineering experiments: kill the primary engine mid-trade, partition the network between replicas, simulate disk failures. Tools like Chaos Monkey and Gremlin automate these tests in production-like environments. Document your RTO (recovery time objective) and RPO (recovery point objective) clearly—most exchanges target RTO under 5 seconds and RPO of zero (no data loss). When designing failover logic, consider the user experience: should in-flight orders be automatically re-submitted after failover, or should clients be notified to retry? Clear API contracts and idempotent order IDs prevent duplicate fills and maintain trust during outages.
How Can You Benchmark and Scale Your Matching Engine for High-Frequency Trading in 2026?
Synthetic load testing with realistic order distributions is the only way to validate performance claims. Generate millions of orders per second using a Pareto distribution for sizes (most orders are small, a few are huge) and a Poisson process for arrival times (bursty, not uniform). Replay historical market data at accelerated speed to test how your engine handles flash crashes, liquidity squeezes, and coordinated market maker withdrawals. Measure three key metrics: throughput (orders processed per second), latency (median, 99th percentile, 99.9th percentile tick-to-trade time), and jitter (standard deviation of latency). A production-grade engine should sustain 1 million orders per second with 99th percentile latency under 500 microseconds and jitter below 50 microseconds.
Horizontal scaling patterns depend on your workload. Sharding by symbol is the simplest approach: each matching engine instance handles a subset of trading pairs (e.g., BTC/USD, ETH/USD on engine A; LTC/USD, XRP/USD on engine B). This works well when order flow is evenly distributed across symbols. For exchanges with a few dominant pairs, partition by order type instead: one engine for limit orders, another for market orders, a third for stop orders. This requires cross-engine coordination to execute stop orders when price thresholds are hit, adding complexity. Advanced architectures use consistent hashing to dynamically rebalance load as trading volumes shift, similar to how Generative AI System Design distributes inference requests across GPU clusters.
Real-world performance metrics reveal hidden bottlenecks. Track queue depth at every stage: gateway ingress queue, matching engine input queue, settlement pipeline output queue. A growing queue indicates a bottleneck—either the component is too slow or downstream consumers are falling behind. Monitor CPU cache hit rates and memory bandwidth utilization; if cache misses exceed 5%, revisit your data structure layout. Log every order’s end-to-end journey with nanosecond timestamps: gateway receipt, queue insertion, matching start, fill generation, settlement acknowledgment. Aggregate these traces to build latency heatmaps and identify outliers. Tools like Jaeger and Zipkin support distributed tracing, but for sub-millisecond precision, custom instrumentation with RDTSC (CPU timestamp counter) is more accurate.
Scaling Bottleneck Diagnosis Process
Capacity planning requires forward-looking projections. If your exchange currently handles 100,000 orders per second during peak hours, design for 10x that capacity to accommodate growth and flash events. Over-provisioning is cheaper than downtime: a single hour of outage during high volatility can cost millions in lost fees and reputational damage. Use auto-scaling policies to spin up additional matching engine instances during traffic spikes, but pre-warm them—cold starts add latency. For exchanges with complex UI UX Design requirements, ensure your WebSocket gateways can handle the corresponding increase in market data subscriptions without overwhelming the matching engine with status queries.
Collaborate with your infrastructure team to optimize the full stack. Network engineers should configure multicast UDP for market data distribution, reducing CPU load on the matching engine. Database administrators must tune write-ahead logs and replication lag to keep settlement pipelines fast. Security teams need to implement rate limiting and DDoS protection without adding latency to legitimate traffic. When every microsecond counts, cross-functional alignment is as important as code optimization. Consider adopting patterns from ai chatbot architecture for real-time monitoring dashboards—stream matching engine metrics to a low-latency analytics layer that can trigger alerts and auto-remediation before users notice degradation.
Final Thoughts
Designing a high-performance order matching engine architecture in 2026 requires balancing algorithmic fairness, sub-millisecond latency, and bulletproof reliability. By selecting the right matching algorithm for your market type, optimizing in-memory data structures with lock-free techniques and cache alignment, implementing robust failover with event sourcing and consensus protocols, and rigorously benchmarking under realistic load, you can build a system that rivals the world’s top exchanges. Remember that performance is not a one-time achievement—continuous profiling, capacity planning, and chaos testing are essential to maintain competitive latency as trading volumes grow. Whether you are launching a new platform or upgrading legacy infrastructure, these architectural patterns provide a proven roadmap to production-grade matching engine design.
Frequently Asked Questions
Q1.What is the difference between FIFO and pro-rata order matching algorithms in 2026?
FIFO (First-In-First-Out) matches orders strictly by time priority in 2026, rewarding speed and ensuring fairness for early participants. Pro-rata distributes fills proportionally based on order size at each price level, favoring larger liquidity providers. FIFO suits retail-focused exchanges; pro-rata benefits institutional markets. Your choice depends on target user base, liquidity incentives, and regulatory requirements in 2026.
Q2.How do in-memory data structures reduce latency in order matching engines in 2026?
In-memory data structures eliminate disk I/O, enabling sub-microsecond access to order books and trade data in 2026. Using hash maps, lock-free queues, and red-black trees keeps critical matching logic in CPU cache, drastically reducing latency. This architecture supports millions of operations per second, essential for high-frequency trading and competitive exchange performance in 2026.
Q3.What are the best failover strategies for crypto exchange matching engines in 2026?
Hot-standby replication with event sourcing ensures seamless failover in 2026, maintaining order state across primary and backup nodes. Implement heartbeat monitoring, automatic leader election via consensus protocols, and sub-second switchover. Geographic redundancy across data centers prevents single points of failure. Regular disaster recovery drills validate failover procedures, ensuring zero downtime during incidents in 2026.
Q4.How can I benchmark the performance of my order matching engine in 2026?
Measure throughput (orders per second), latency percentiles (p50, p99, p99.9), and order-to-trade time under realistic load in 2026. Use synthetic order generators simulating peak traffic, stress test with 10× expected volume, and profile CPU/memory usage. Compare against industry standards (sub-millisecond latency). Tools like JMH, Gatling, or custom harnesses provide reproducible metrics for optimization in 2026.
Q5.Why is lock-free programming important for high-frequency trading matching engines in 2026?
Lock-free programming eliminates thread contention and context switching, critical for microsecond-level latency in 2026. Traditional locks cause unpredictable delays under high concurrency, unacceptable for HFT. Atomic operations and compare-and-swap enable safe concurrent access without blocking. This approach maximizes CPU efficiency, ensures deterministic performance, and scales linearly with cores in high-frequency trading matching engines in 2026.
Q6.What role does event sourcing play in matching engine disaster recovery in 2026?
Event sourcing stores every order, cancel, and trade as immutable events, enabling complete state reconstruction in 2026. During disaster recovery, replaying the event log rebuilds the order book to any point in time. This guarantees audit trails, regulatory compliance, and zero data loss. Combined with snapshotting, event sourcing provides fast recovery and forensic analysis capabilities for matching engines in 2026.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.




