Ai Overview
LLM chatbot architecture refers to the complete structural design of a conversational AI system built on a large language model. Getting this wrong results in either bloated context windows that slow inference and increase cost, or amnesiac systems that fail to recognize returning users and repeat questions they have already asked. Choosing the right pattern before the build begins saves enormous amounts of rework, cost, and time later.
Key Takeaways
- LLM chatbot architecture is a multi-layered system where orchestration, memory, retrieval, and fallback each serve a specific, non-interchangeable function in the pipeline.
- The chatbot orchestration layer is the central controller that sequences tool calls, routes prompts, and coordinates agent execution across the entire conversational AI architecture.
- Chatbot memory management separates into short-term session context and long-term persistent storage, and both must be designed intentionally to avoid context loss in production systems.
- RAG architecture reduces hallucination by grounding LLM responses in real-time document retrieval from a vector database, making AI outputs verifiably accurate for enterprise use.
- An AI response fallback system must be designed before launch, not added later; without structured fallback, production chatbots fail silently and damage user trust at scale.
- Multi agent chatbot architecture enables complex enterprise workflows by assigning specialized agents to distinct tasks, coordinated by a master prompt orchestration controller.
- Context window management is one of the most underestimated design challenges; exceeding token limits without a pruning or compression strategy causes severe degradation in response quality.
- Scalable chatbot infrastructure for India and UAE markets requires geo-distributed deployments, low-latency vector search, and async processing to maintain response quality under peak traffic.
- Security and governance layers in enterprise chatbot architecture are not optional additions; they must be embedded at the prompt, retrieval, and tool-calling layers from the very first build.
- Hallucination prevention in LLMs requires a combination of RAG, confidence scoring, output validation, and structured fallback triggers working together within a unified AI pipeline architecture.
Over the past eight years, our team has architected, stress-tested, and scaled dozens of conversational AI systems for enterprises across India and the UAE. One truth has remained constant: the quality of an AI chat assistant is only as strong as the chatbot architecture supporting it. When businesses in Dubai or Bengaluru face inconsistent responses, slow performance, or costly AI failures, the root cause is almost always architectural, not the language model itself.
Modern LLM chatbot architecture is no longer a single-model pipeline. It is a layered, interconnected system where orchestration, memory, fallback, retrieval, and security each play a defined role. Understanding how these layers communicate, and how to design them correctly, is what separates a production-grade AI system from a fragile prototype that breaks under real-world load. This guide covers every critical layer with the depth and precision that engineering teams and product leaders need.
What is LLM Chatbot Architecture?
LLM chatbot architecture refers to the complete structural design of a conversational AI system built on a large language model. It is not simply the model itself but rather the entire stack of components that surround the model: input processing, memory systems, retrieval pipelines, orchestration logic, fallback handlers, tool integrations, and output validators. Each component serves a distinct function, and the overall quality of the system depends entirely on how well these parts are designed and connected.
In 2026, the LLM chatbot architecture for production systems in India and UAE has evolved significantly beyond a basic prompt-response loop. Enterprises now demand conversational AI architecture that can handle multi-turn dialogues, execute backend tool calls, retrieve documents from proprietary knowledge bases, and scale to millions of concurrent sessions without latency spikes or accuracy loss. The architecture must also meet regional compliance requirements around data residency and user privacy, particularly in regulated sectors such as banking, healthcare, and government services.
At its core, chatbot architecture answers three foundational questions: How does the system understand what the user wants? How does it retrieve or generate the right information? And how does it respond reliably when the primary path fails? Every design decision in the architecture flows from the answers to these three questions. Getting this foundation right is the most important step any engineering team can take before writing a single line of code.
LLM Core Engine
The large language model serves as the reasoning and generation engine at the center of the entire chatbot architecture, processing prompts and producing outputs.
Orchestration Controller
The chatbot orchestration layer coordinates every component, deciding which tools to call, which memory to load, and which pipeline path to execute for each query.
Retrieval and Memory
RAG architecture and chatbot memory management together ensure the AI works with accurate, contextual, and up-to-date information rather than stale training data alone.
Core Layers of an LLM Based Chatbot System
A well-designed LLM chatbot architecture consists of several distinct functional layers, each responsible for a specific aspect of the system’s behavior. These layers do not operate in isolation; they communicate through defined interfaces and data contracts. Understanding each layer, its responsibilities, and its failure modes is fundamental to building a reliable conversational AI architecture for enterprise production environments.
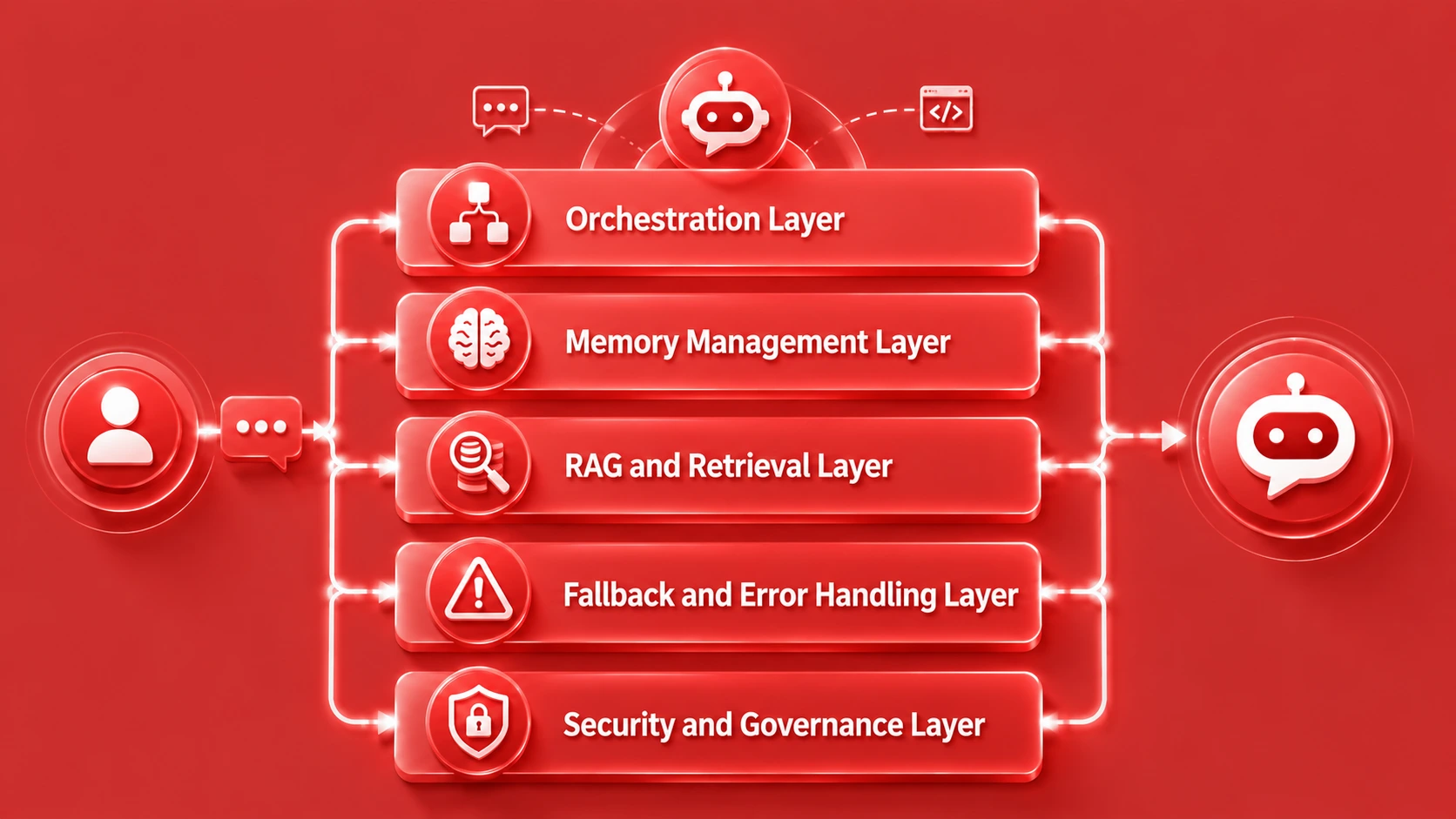
Core Layers and Functional Weight in a Production Chatbot System
The input processing layer handles tokenization, language detection, intent classification, and initial sanitization of user messages. The AI pipeline architecture then passes this processed input to the orchestration layer, which determines the execution path. The LLM layer generates the response, while the output layer validates, formats, and delivers the final reply through the appropriate interface channel such as web, mobile, or API.
How the Orchestration Layer Works in Chatbot Architecture?
The chatbot orchestration layer is the operational brain of any modern LLM chatbot architecture. Its primary role is to receive a processed input, determine which combination of tools, agents, or retrieval pipelines should be activated, sequence those activations in the correct order, and pass results between components before returning a synthesized final output. Without a well-engineered orchestration layer, even the most capable language model produces inconsistent and unreliable results in production.
Prompt orchestration specifically refers to the science of constructing the right prompt at the right moment, combining system instructions, retrieved context, memory summaries, user input, and tool outputs into a coherent and effective prompt that the LLM can process with maximum accuracy. In enterprise chatbot architecture, this process must be deterministic, auditable, and version-controlled to ensure consistent behavior across thousands of daily interactions.
Orchestration Layer: Step-by-Step Execution Flow
User Input Reception
Raw message is received, tokenized, sanitized, and passed through intent classification before entering the orchestration pipeline.
Memory Retrieval
Orchestrator queries both short-term session context and long-term memory stores to build a comprehensive context window for the current turn.
Tool and Agent Routing
Based on intent, the tool calling architecture routes to appropriate APIs, database queries, or specialized agents within the multi agent chatbot architecture.
Prompt Construction
Prompt orchestration assembles memory summaries, retrieved documents, tool outputs, and system instructions into the final structured prompt sent to the LLM.
Output Validation and Delivery
LLM output is scored for confidence, validated against guardrails, and either delivered to the user or passed to the AI response fallback system if quality thresholds are not met.
AI workflow automation depends heavily on the orchestration layer functioning without bottlenecks. In high-volume environments such as Dubai-based e-commerce platforms or Indian banking chatbots, the orchestration layer must handle thousands of concurrent pipelines with sub-second latency. This requires asynchronous execution, priority queuing, and intelligent caching at the orchestration level.
Understanding the Memory Layer in Conversational AI Systems
Chatbot memory management is one of the most technically nuanced aspects of conversational AI architecture. An LLM has no inherent memory between API calls; it only knows what is present in the current context window. This means that the memory layer in the chatbot architecture is entirely the responsibility of the engineering team, not the model itself. How this layer is designed will determine whether users experience a coherent, personalized conversation or a frustrating series of disconnected exchanges.
In our work as an AI app development company building AI assistant architecture for enterprise clients across India and UAE, we consistently find that memory layer design is underestimated in early project phases and becomes the most expensive problem to fix after launch. A proper memory system must handle storage, retrieval, compression, and expiry of context data in a way that is both computationally efficient and contextually meaningful for the AI pipeline architecture to consume.
Short Term vs Long Term Memory in LLM Based Chatbots
The distinction between short-term and long-term memory in LLM based chatbots is one of the most practically important concepts in chatbot architecture design. Getting this wrong results in either bloated context windows that slow inference and increase cost, or amnesiac systems that fail to recognize returning users and repeat questions they have already asked. Both failure modes are unacceptable in enterprise deployments.
Short Term vs Long Term Memory: Comparison
| Attribute | Short Term Memory | Long Term Memory in AI Chatbots |
|---|---|---|
| Scope | Single session only | Persists across sessions indefinitely |
| Storage | Context window or in-memory cache | Vector database, relational DB, or key-value store |
| Retrieval Method | Direct inclusion in prompt payload | Semantic search via vector embeddings |
| Expiry | Ends with session closure | Policy-driven TTL or manual deletion |
| Use Case | Turn-by-turn context continuity | User profiling, personalization, history recall |
| Cost Impact | Token cost per session only | Storage and retrieval infrastructure cost |
Context window management is the critical operational concern for short-term memory. As conversations grow longer, token counts rise and costs increase. Production systems must implement sliding window strategies, summary compression, or selective pruning to keep context windows within model limits while retaining the most relevant conversational history. Failing to manage this results in truncation errors and sudden context loss that users experience as the chatbot “forgetting” what was just discussed.
How Fallback Mechanisms Are Structured in AI Systems?
The AI response fallback system is the safety net of the entire chatbot architecture. It activates when the primary LLM pathway produces a response that is below acceptable confidence thresholds, is factually inconsistent with retrieved documents, falls outside the defined scope of the system, or encounters a technical failure such as a timeout or API error. A well-engineered fallback system is transparent to the end user and graceful in its handling of edge cases.
Hallucination prevention in LLMs is one of the primary motivations for building a robust fallback mechanism. When a language model generates confident-sounding but factually incorrect information, the fallback layer must detect this and either trigger a retrieval-grounded retry, escalate to a human agent, or deliver a safe, pre-approved fallback response. This is especially critical in enterprise chatbot architecture for financial services and healthcare applications in India and UAE, where incorrect information carries regulatory and reputational risk.
Confidence-Based Fallback
When LLM confidence scores fall below a defined threshold, the fallback handler triggers a RAG-based retry or routes the query to a secondary model for re-evaluation.
Out-of-Scope Fallback
Queries that fall outside the system’s defined knowledge boundary are caught by intent classifiers and redirected to pre-written safe responses or human escalation pathways.
Technical Failure Fallback
API timeouts, model errors, or database connection failures are caught by circuit breakers that deliver graceful degradation responses instead of raw error messages to users.
Data Flow Between Orchestration, Memory, and Fallback Layers
Understanding the exact data flow between the orchestration, memory, and fallback layers of the LLM chatbot architecture is essential for both initial design and ongoing troubleshooting. These three layers exchange structured data payloads at every step of a conversation, and any mismatch in data format, missing fields, or latency spikes at the interface between layers will degrade the entire system’s performance.
Data Flow: Layer Interactions in a Production Chatbot System
| Data Exchange | Source Layer | Destination Layer | Data Type |
|---|---|---|---|
| User intent + entities | Input Processing | Orchestration | Structured JSON |
| Memory retrieval request | Orchestration | Memory Layer | User ID + session ID |
| Context payload | Memory Layer | Orchestration | Token-compressed text |
| LLM output + confidence | LLM Engine | Orchestration | Text + score float |
| Fallback trigger signal | Orchestration | Fallback Layer | Error code + reason |
In production AI pipeline architecture, this data flow must be observable and logged at every exchange point. Distributed tracing tools integrated into the scalable chatbot infrastructure allow engineering teams to identify exactly where latency is introduced or where data quality degrades across the system. This observability is especially important when debugging why a specific user query failed or produced an unexpected response.
Chatbot Architecture Patterns for Production Systems
Different production environments require different chatbot architecture patterns. Over eight years of building AI systems for enterprise clients in India, UAE, and globally, we have identified three primary patterns that cover the vast majority of production use cases. Choosing the right pattern before the build begins saves enormous amounts of rework, cost, and time later.
How Each Layer Connects in an LLM Chatbot System?
The practical connectivity between layers in an LLM chatbot architecture determines the system’s actual reliability. Each layer exposes an interface, either a function call, an API endpoint, a message queue, or a shared database, through which it communicates with adjacent layers. These interfaces must be designed with strict contracts: defined input schemas, output schemas, error codes, and timeout behaviors that every connected layer respects.
In our experience building scalable chatbot infrastructure across enterprise deployments, the most common source of production failures is interface mismatches between layers built by different teams or at different times. When the memory layer returns a compressed context object that the orchestration layer’s prompt builder does not expect, the entire pipeline silently degrades. This is why interface contracts must be defined, tested, and versioned as first-class assets of the AI assistant architecture.
According to a recent report by DesignRush, enterprises in 2026 are moving beyond isolated chatbots toward fully orchestrated multi-agent systems, with over 60% of Fortune 500 companies actively experimenting with agentic AI architectures that require precisely the kind of structured, governed layer connectivity described here.[1]
Layer Connection Timeline in a Single Query Lifecycle
0ms: Input Layer
User message tokenized, language detected, intent classified. Output passed to orchestration as structured payload.
15ms: Memory Layer
Session context retrieved from working memory. User history queried from long term memory in AI chatbots store. Context compressed for token efficiency.
30ms: Retrieval Layer
RAG architecture queries vector database for chatbots. Semantic search chatbot returns top-k relevant document chunks grounded in the knowledge base.
45ms: Orchestration + LLM
Prompt orchestration assembles final prompt. LLM generates response. Confidence scoring runs immediately post-generation.
60-80ms: Output or Fallback
If confidence passes, response is validated and delivered. If not, AI response fallback system activates and delivers a safe, governed alternative response.
Scaling and Performance Design in Conversational AI
Scalable chatbot infrastructure is a non-negotiable requirement for any enterprise conversational AI deployment in 2026. As user bases grow across India’s tier-1 and tier-2 cities or UAE’s high-volume commercial sectors, the architecture must scale horizontally without proportional increases in latency or cost. This requires careful planning at every layer of the AI pipeline architecture, from the input gateway to the vector retrieval engine.
The most computationally expensive operations in a conversational AI architecture are LLM inference, vector similarity search, and real-time memory retrieval. Each of these must be independently scalable so that a spike in one area does not cascade into failures across the system. Deploying these components as independently scalable microservices with auto-scaling policies ensures that the architecture can handle Black Friday-scale traffic spikes without engineering intervention.
Performance Design Strategies for Scalable Chatbot Infrastructure
| Strategy | Layer Applied | Impact |
|---|---|---|
| Semantic caching of frequent queries | Retrieval + Orchestration | 40-60% reduction in LLM API calls |
| Async pipeline processing | Orchestration Layer | Non-blocking execution, lower perceived latency |
| Vector index sharding | Vector Database | Sub-50ms retrieval at 100M+ document scale |
| Model quantization for inference | LLM Engine | 3-5x cost reduction without accuracy loss |
| Context window compression | Memory Layer | 30-50% token reduction per request |
Security and Governance Layer in LLM Based Systems
Security and governance are not afterthoughts in enterprise chatbot architecture. They are structural requirements that must be embedded into the design from the very first sprint. In regulated markets like India and UAE, where data privacy laws and sector-specific compliance requirements apply, an LLM chatbot architecture without a robust governance layer is a liability rather than an asset.
The security layer in a conversational AI architecture operates at four distinct levels: input security (prompt injection detection, PII filtering), model security (output sanitization, content moderation), retrieval security (permission-aware RAG that only surfaces documents the user is authorized to access), and infrastructure security (encryption in transit and at rest, audit logging, access control). Each of these must be independently tested and continuously monitored in production.
Prompt Injection Defense
Input validation layers detect and neutralize adversarial prompt injections before they reach the LLM, protecting system instruction integrity in all enterprise chatbot architecture deployments.
PII Detection and Masking
Automated PII detection identifies and masks sensitive personal data in both user inputs and LLM outputs before any data is stored, logged, or transmitted to third-party services.
Governance Audit Logging
Every prompt, retrieval query, tool call, and LLM output is logged with timestamps and user IDs to a tamper-resistant audit trail required by DPDP Act compliance in India and UAE regulations.
Common Design Mistakes in Chatbot Architecture
After auditing dozens of AI systems built by other teams, we have identified a recurring set of design mistakes in chatbot architecture that consistently lead to production failures, cost overruns, or poor user experiences. These mistakes are not the result of poor intent but rather of skipping foundational design work during the early phases of the project, often due to timeline pressure or overconfidence in the LLM’s capabilities.
No Context Window Budget
Teams that do not plan context window management from day one hit token limits in production, causing sudden context loss and confusing user experiences under real conversation lengths.
Fallback as an Afterthought
Building the AI response fallback system after the main pipeline is complete results in shallow, untested fallback logic that fails at the worst possible moments in production environments.
Monolithic Orchestration
Building the chatbot orchestration layer as a single monolithic function makes the system brittle and impossible to scale independently as different layers grow at different rates.
Skipping Vector Database Design
Storing documents in a vector database for chatbots without careful embedding strategy and indexing design results in poor retrieval quality that no amount of prompt engineering can fix.
Ignoring Memory Architecture
Teams that treat the LLM as stateful when it is stateless by design create systems with no genuine chatbot memory management, causing frustrating repeated questions and lost conversational context.
No Hallucination Detection
Deploying without hallucination prevention in LLMs means confident incorrect answers reach users unchecked, eroding trust rapidly and creating compliance exposure in regulated industries.
Best Practices for Building a Reliable LLM Chatbot System
Building a reliable LLM chatbot architecture requires more than technical knowledge. It requires a systematic approach to design, testing, and operational discipline. The following best practices are drawn from our agency’s experience delivering production-grade conversational AI architecture to enterprise clients across India, UAE, and globally. Each practice addresses a specific failure mode that we have encountered repeatedly in real-world deployments.
Best Practices Mapped to Architecture Layer
| Best Practice | Architecture Layer | Outcome |
|---|---|---|
| Design memory schema before writing code | Memory Layer | Prevents costly refactors when scale increases |
| Version control all system prompts | Orchestration Layer | Enables rollback when prompt changes degrade quality |
| Test fallback paths with adversarial inputs | Fallback Layer | Guarantees graceful handling of edge cases in production |
| Implement embedding refresh pipelines | RAG Layer | Keeps vector database current with latest knowledge |
| Monitor confidence score distributions daily | Output Validation | Early detection of model drift or retrieval degradation |
| Separate orchestration logic from business rules | Orchestration Layer | Makes chatbot architecture maintainable as requirements evolve |
Building with these practices from the start creates an enterprise chatbot architecture that is not only functional at launch but continues to improve over time. The systems that deliver the best long-term ROI for businesses in India and UAE are those built with disciplined architectural foundations, not those assembled fastest. Every shortcut taken during architecture design compounds into a larger technical debt that is far more expensive to resolve in production.
The convergence of RAG architecture, multi agent chatbot architecture, semantic search chatbot capabilities, and AI workflow automation within a single unified LLM chatbot architecture marks the standard for what enterprise-grade AI systems look like in 2026. Organizations that invest in getting this architecture right from the outset will operate with a durable competitive advantage over those still patching together disconnected tools and hoping for coherent behavior.
Build Your LLM Chatbot Architecture the Right Way
Our team has 8+ years designing scalable, production-ready conversational AI systems for enterprises across India and UAE. Let us architect yours.
Frequently Asked Questions About AI Chatbots
Q1.1. What exactly is chatbot architecture and why does it matter?
Chatbot architecture is the structural blueprint that defines how all components of a conversational AI system connect, process information, and generate responses. It determines scalability, accuracy, and reliability for businesses in India, UAE, and beyond.
Q2.2. How does the orchestration layer work in an LLM chatbot?
The chatbot orchestration layer acts as the central controller that routes user inputs, manages tool calls, coordinates between agents, and sequences prompts. It ensures that every part of the system executes in the correct order for accurate and consistent AI responses.
Q3.3. What is the role of memory in a conversational AI system?
Chatbot memory management allows the system to retain context from previous turns in a conversation. Without memory, the AI treats every message as independent, resulting in confusing and repetitive responses that frustrate users and reduce trust in the system.
Q4.4. What is a fallback mechanism in an AI chatbot system?
An AI response fallback system is a set of rules and backup processes that activate when the primary LLM fails, produces low-confidence output, or encounters an out-of-scope query. It prevents the chatbot from hallucinating or returning empty, harmful responses.
Q5.5. What is RAG and how does it fit into chatbot architecture?
Retrieval augmented generation (RAG architecture) combines a language model with real-time document retrieval from a vector database. This grounds responses in verified data, reduces hallucination, and makes the AI assistant architecture far more accurate for knowledge-intensive tasks.
Q6.6. What is the difference between short term and long term memory in an LLM chatbot?
Short term memory holds context within a single session using the context window, while long term memory in AI chatbots stores user preferences and historical data in persistent databases. Together, they enable personalized and coherent multi-session conversations at scale.
Q7.7. How is enterprise chatbot architecture different from a basic bot setup?
Enterprise chatbot architecture includes security layers, multi-agent coordination, governance controls, scalable cloud infrastructure, audit logging, and compliance management. Basic bots lack these components and cannot handle the complexity of production-grade business workflows in regulated industries.
Q8.8. What is a vector database and why is it used in AI chatbots?
A vector database for chatbots stores information as numerical embeddings that allow the system to perform semantic search chatbot queries. Instead of exact keyword matching, the system finds conceptually relevant answers, making retrieval far more accurate and context-aware for end users.
Q9.9. How do multi agent chatbot systems handle complex workflows?
In a multi agent chatbot architecture, specialized agents are assigned specific tasks such as data retrieval, user authentication, or API calls. A master orchestration layer coordinates these agents, passes results between them, and synthesizes a unified response for the user.
Q10.10. What are the most common mistakes teams make when designing chatbot architecture?
Common mistakes include skipping proper context window management, ignoring fallback design, building without a vector database, failing to separate orchestration from business logic, and neglecting security governance. These errors cause production failures that are expensive and time-consuming to fix later.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.