Ai Overview
Hybrid LLM architecture in AI Copilot system uses multiple language models working together to balance speed, accuracy, and reasoning. It routes tasks to specialized models for writing, coding, or analysis, improving performance, reducing errors, and delivering more reliable, context aware AI responses. Deployment model selection determines cost structure, latency profile, compliance posture, and operational complexity.
Key Takeaways
- 01
Hybrid LLM Architecture combines large language models with retrieval, APIs, and memory, enabling AI copilots to handle complex enterprise tasks accurately. - 02
The orchestration layer in Hybrid LLM Architecture routes queries intelligently between model components, ensuring every AI copilot request is handled optimally. - 03
RAG integration in Hybrid LLM Architecture allows AI copilot systems to retrieve verified, domain-specific information and reduce hallucination rates significantly. - 04
API gateway design in Hybrid LLM Architecture manages authentication, rate limiting, and secure data routing across all AI copilot system components. - 05
Enterprises in the US, UAE, and India use Hybrid LLM Architecture for deployments that balance performance, compliance, and multi-region scalability requirements. - 06
Latency optimization techniques including semantic caching and parallel retrieval are critical features of a well-designed Hybrid LLM Architecture. - 07
Fault-tolerant AI copilot deployment architecture ensures uninterrupted service through redundant endpoints, health monitoring, and automatic failover mechanisms. - 08
Context assembly in Hybrid LLM Architecture merges user intent, retrieved documents, memory, and system state into a unified prompt for the LLM to process.
What is Hybrid LLM Architecture?
Hybrid LLM architecture in AI Copilot system uses multiple language models working together to balance speed, accuracy, and reasoning. It routes tasks to specialized models for writing, coding, or analysis, improving performance, reducing errors, and delivering more reliable, context aware AI responses.
Hybrid LLM Architecture is a structured AI system design model that integrates one or more large language models with retrieval systems, external knowledge bases, specialized processing modules, and orchestration logic to create a unified, production-grade AI copilot system. Unlike a simple API call to a single language model, Hybrid LLM Architecture treats the LLM as one component within a broader, interconnected system.
Over the past eight years, our team has designed and deployed intelligent automation systems for enterprise clients across the US, UAE (Dubai), and India. One of the most consequential shifts we have observed in that time is the move away from single-model AI systems toward structured, multi-component architectures. At the center of this shift is Hybrid LLM Architecture, a design model that fundamentally changes how artificial intelligence Copilot systems are built, orchestrated, and deployed at scale.
The defining characteristic of this architecture is its ability to route different types of requests to different processing pathways. A factual query might go directly to a retrieval augmented generation pipeline. A reasoning-heavy task might invoke a high-parameter foundation model. A structured data extraction request might be handled by a fine-tuned smaller model. The Hybrid LLM Architecture orchestrator manages all of this without the end user ever seeing the underlying complexity.
From our work with enterprises across India, the UAE, and the US, we have seen this architecture become the standard for any AI copilot deployment that goes beyond simple question-answering. It is the foundation for intelligent document review, automated research assistants, multi-step workflow copilots, and domain-specific knowledge platforms.
Modular Intelligence
Multiple specialized components work together under one orchestrated Hybrid LLM Architecture rather than one model doing everything.
Dynamic Routing
Every query is routed to the most appropriate model or retrieval pathway based on type, complexity, and context within the architecture.
Reliable AI Copilot
Enterprises get an AI copilot system that is accurate, scalable, auditable, and resilient to failure across all operational conditions.
Hybrid LLM Architecture System Blueprint for AI Copilots
A production-grade Hybrid LLM Architecture is not assembled from random components. It follows a deliberate blueprint where each layer serves a distinct purpose and communicates with adjacent layers through well-defined interfaces. Understanding this blueprint is the first step toward designing an AI copilot system that performs reliably under real enterprise load.
The blueprint consists of seven primary layers, each contributing to the overall intelligence, reliability, and scalability of the AI copilot integration framework. Here is the structural overview:
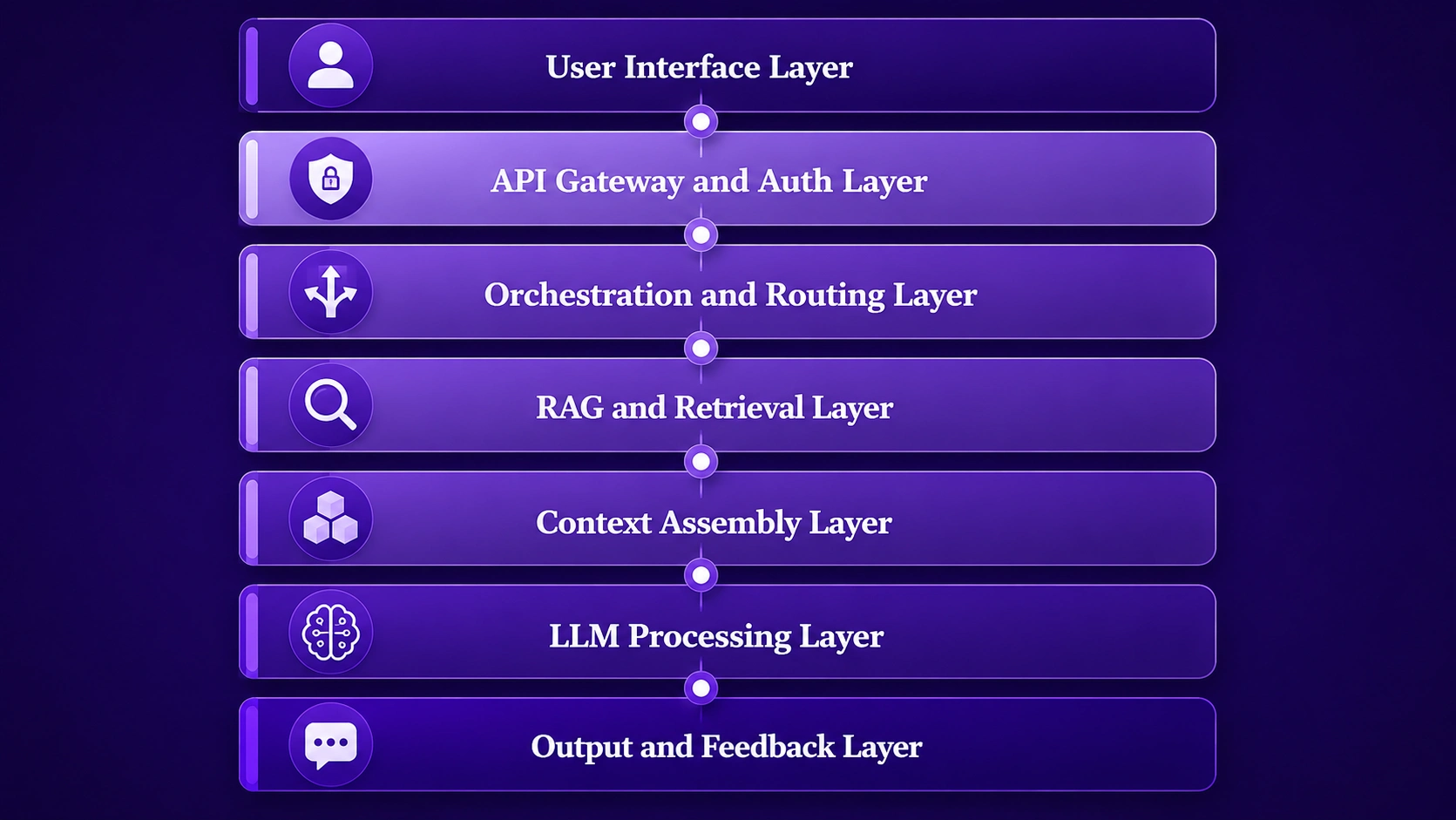
Each layer is purpose-built. The user interface layer captures raw input from the AI copilot user. The API gateway validates and routes the request securely. The orchestration layer decides which downstream components handle the query. The RAG and retrieval layer fetches relevant context. Context assembly builds the final prompt. The LLM processes it. And the output layer delivers the response while feeding back performance signals for continuous improvement.
Data Flow Design in AI Copilot Systems
Data flow design is one of the most critical aspects of Hybrid LLM Architecture. How information moves through the system, where it is transformed, and how efficiently it reaches the LLM for processing determines the overall responsiveness and accuracy of the AI copilot.
In a well-architected Hybrid LLM Architecture, data flows in two primary directions: the request pipeline and the response pipeline. The request pipeline carries user input through Preprocessing, routing, retrieval, and context assembly before reaching the LLM. The response pipeline carries the LLM output back through post-processing, safety checks, formatting, and delivery to the user interface.
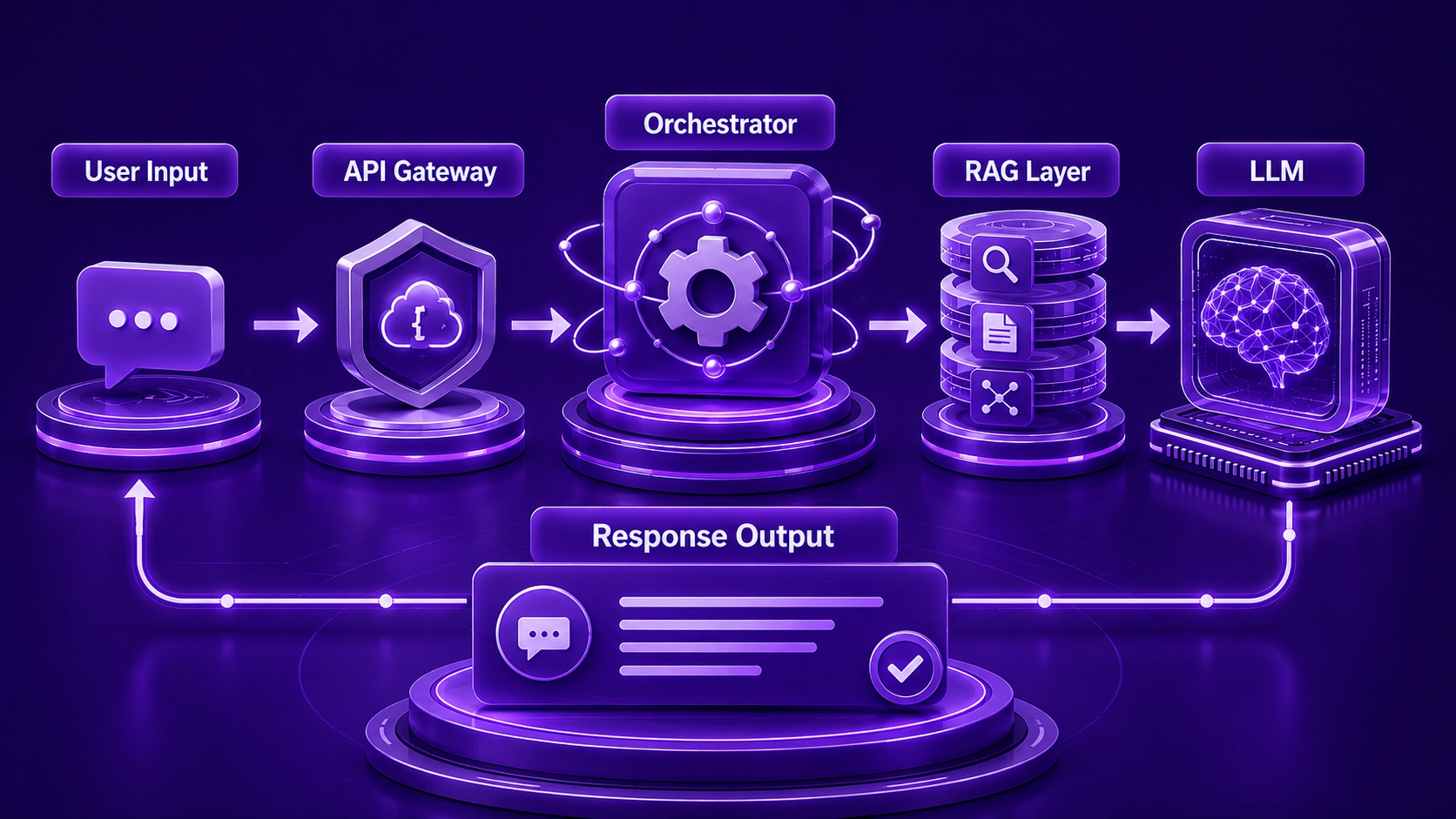
Enterprises operating AI copilots at scale in the US must design data flows that handle high concurrency without degradation. In the UAE and India, where data sovereignty is a growing concern, data flow architecture must also account for regional routing rules that keep sensitive information within approved infrastructure boundaries.
LLM Orchestration Layer in Copilot Architecture
The orchestration layer is the strategic core of any Hybrid LLM Architecture. It is the component that makes the system intelligent at the structural level, before any individual LLM even processes a word. The orchestrator receives a parsed query from the gateway layer and makes routing decisions based on query type, complexity score, available model capacity, and predefined business rules.
In a well-built AI copilot orchestration layer, these decisions happen in milliseconds. The orchestrator maintains a registry of available model endpoints, each with its own performance profile, specialization domain, and current load. It selects the optimal path for each request and manages the full lifecycle of that request from initiation to response delivery.
Query Classifier
Analyzes incoming queries to determine type, domain, complexity, and intent before routing begins within the Hybrid LLM Architecture.
Model Registry
Maintains a live catalog of all LLM endpoints, their specializations, current availability, and latency metrics for intelligent selection.
Load Balancer
Distributes requests across available model endpoints to prevent bottlenecks and maintain AI copilot responsiveness under high traffic.
Task Decomposer
Breaks complex multi-part requests into sub-tasks that can be processed in parallel or sequence within the AI copilot system design.
State Manager
Preserves conversation state, session context, and task progress across multi-turn interactions within the AI copilot powered by LLMs.
Error Handler
Catches failures at any point in the orchestration pipeline and triggers fallback logic or human escalation paths automatically.
RAG Integration Pipeline in Hybrid LLM Architecture
Retrieval Augmented Generation is one of the most transformative integrations within Hybrid LLM Architecture. RAG allows the AI copilot to move beyond the static knowledge baked into model weights and access live, domain-specific, and organization-specific information at inference time.
The RAG pipeline in a Hybrid LLM Architecture consists of four sequential stages. Each stage must perform reliably for the overall retrieval quality to be high enough to power an accurate enterprise AI copilot. [1]
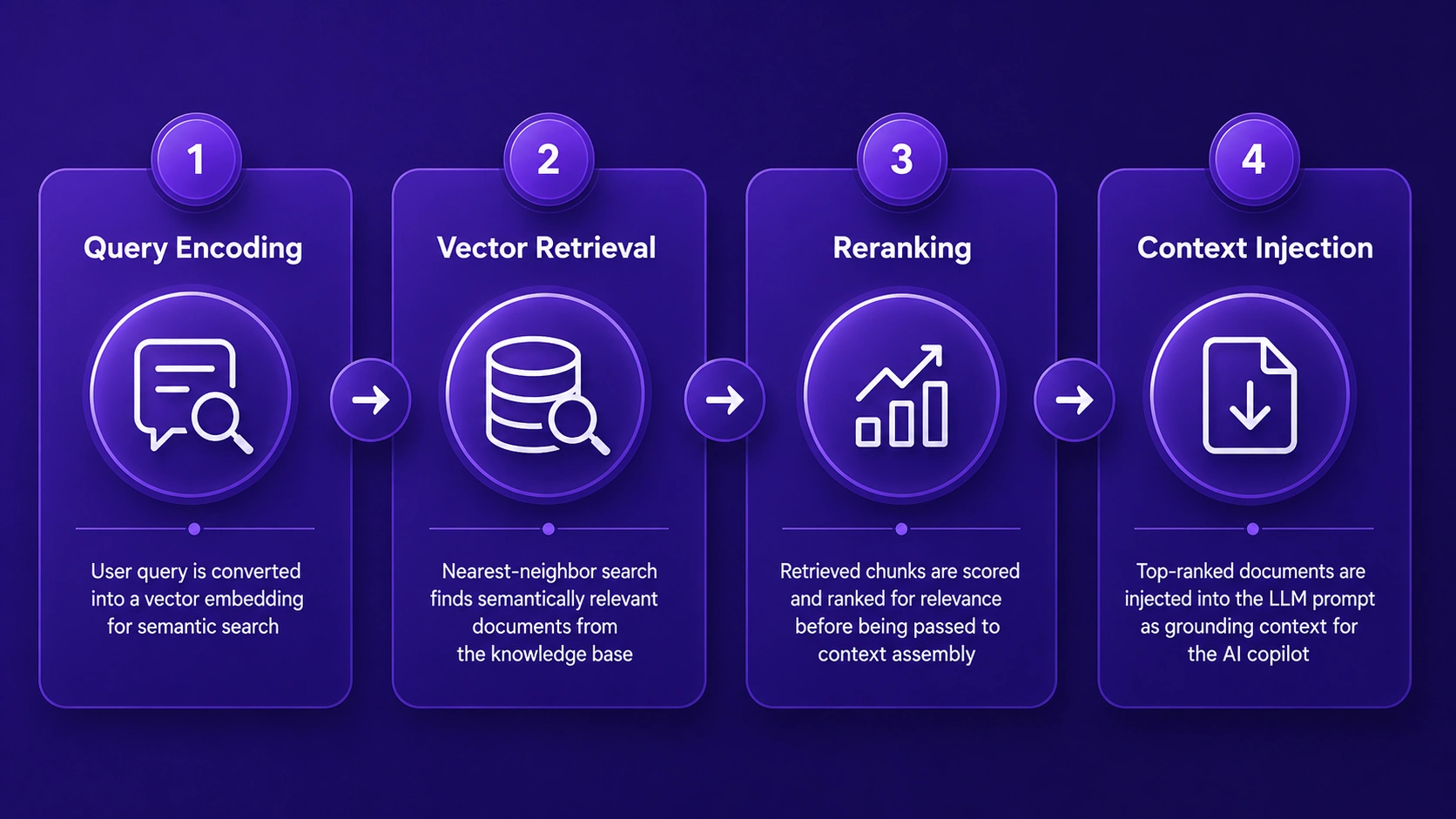
For enterprises in Dubai building AI copilot integration frameworks for financial or legal use cases, the RAG pipeline must be tuned to retrieve from proprietary document sets, regulatory databases, and internal knowledge repositories. The quality of the vector index and the precision of the reranking model directly determine how accurate and trustworthy the AI copilot with RAG systems becomes.
Query Routing Between LLM and Retrieval Layer
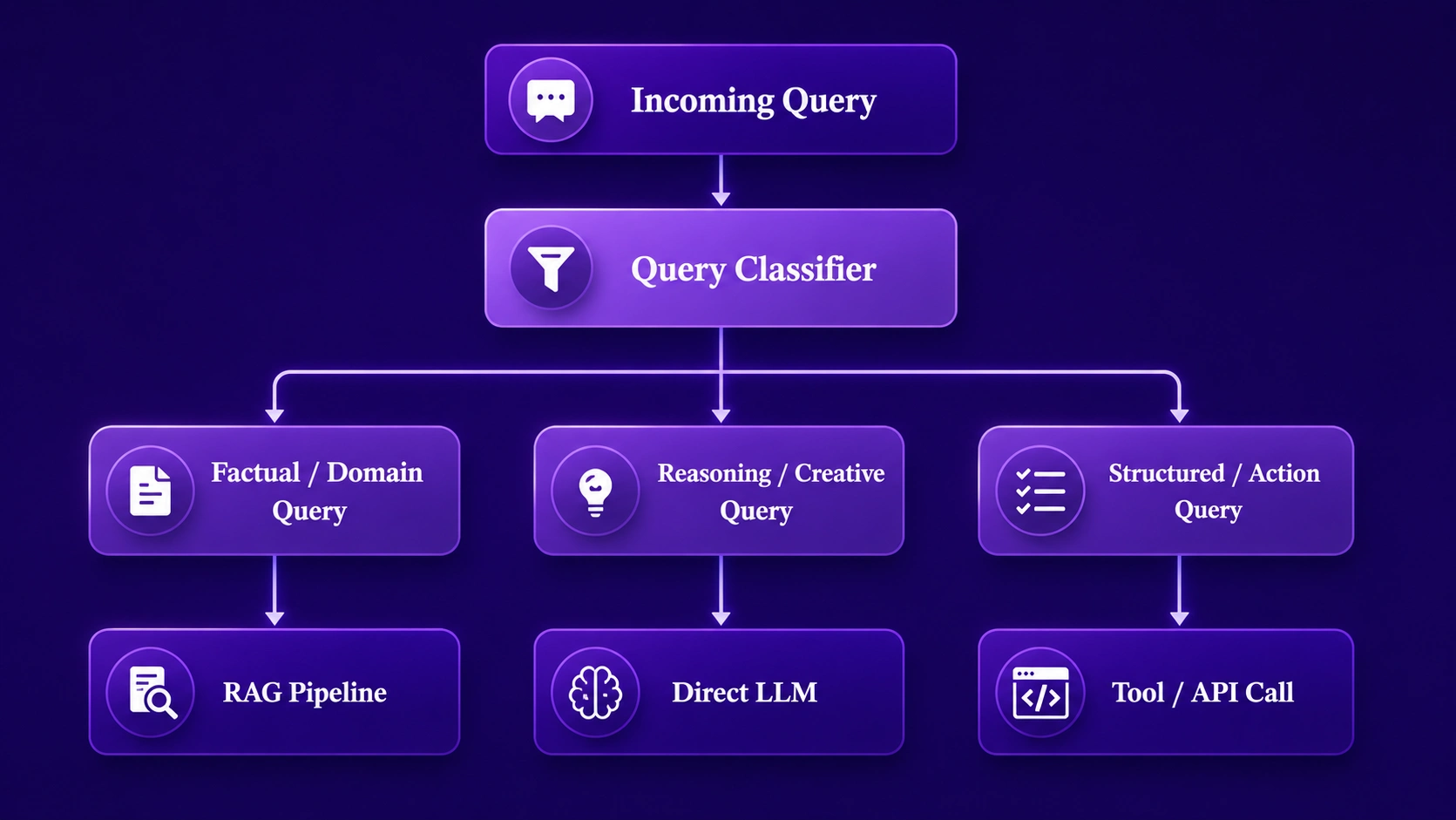
Query routing is the decision-making process within Hybrid LLM Architecture that determines whether a given query needs retrieval augmentation, direct LLM generation, tool invocation, or a combination of all three. Getting this routing logic right is one of the most impactful engineering decisions in AI copilot system design.
A poorly designed routing layer sends every query through the full retrieval pipeline, adding unnecessary latency for queries that the LLM can answer directly. An overly permissive routing layer sends knowledge-dependent queries straight to the LLM without retrieval, producing hallucinated answers. The optimal Hybrid LLM Architecture routing layer uses a lightweight classifier to make routing decisions rapidly and accurately.
Context Assembly in Hybrid LLM Architecture Systems
Context assembly is the process of constructing the final input that the LLM will process. In Hybrid LLM Architecture, this is not as simple as passing the user’s raw query to the model. The context assembly layer combines multiple information streams into a single, structured, token-efficient prompt that gives the LLM everything it needs to produce an accurate and relevant response.
The five inputs that typically feed the context assembly layer are: the user’s current query, the conversation history from the session memory module, the top retrieved documents from the RAG pipeline, relevant system instructions and persona definitions, and any structured tool outputs from previous steps in the same request chain.
For AI copilot systems handling sensitive data in Indian financial services or UAE healthcare platforms, the context assembly layer must also apply privacy filters, removing personally identifiable information before it enters the LLM prompt. This makes context assembly not just a performance concern but a compliance-critical function within Hybrid LLM Architecture.
Multi-Layer Processing in AI Copilot Design
One of the defining strengths of Hybrid LLM Architecture is its multi-layer processing capability. Rather than a single model handling every aspect of a request, the architecture distributes processing across specialized layers, each optimized for its specific function.
This parallel and sequential processing design allows AI copilot systems to deliver both speed and depth simultaneously, something that single-model architectures fundamentally cannot achieve.
Preprocessing Layer
Cleans, normalizes, and tokenizes raw user input. Handles language detection and input safety screening before routing begins.
Semantic Layer
Converts queries into vector embeddings for similarity search and intent classification within the AI copilot with RAG systems pipeline.
Inference Layer
The LLM processing core. Receives the fully assembled context and generates a reasoned, coherent response aligned with the copilot’s task domain.
Post-Processing Layer
Formats the LLM output, applies content safety filters, and structures the response for the target interface within the AI copilot system.
Evaluation Layer
Scores response quality, relevance, and safety in real time, triggering regeneration or escalation if quality thresholds are not met.
Feedback Layer
Captures user signals and system performance metrics to continuously improve routing decisions and model selection within the Hybrid LLM Architecture.
API Gateway Structure in AI Copilot Systems
The API gateway is the secured entry point for all requests entering a Hybrid LLM Architecture AI copilot system. Every request from a user, an external application, or an automated system must pass through the gateway before any processing begins. This makes the API gateway a critical control point for performance, security, and observability.
For enterprise AI copilot API gateway design, the gateway must handle authentication, authorization, rate limiting, request logging, input validation, and version routing simultaneously without becoming a bottleneck.
API Gateway Functions in Hybrid LLM Architecture
| Gateway Function | Purpose | Enterprise Relevance |
|---|---|---|
| Authentication | Verifies identity of every requesting entity using tokens, API keys, or OAuth flows | Critical for enterprise access control in US and UAE regulated environments |
| Rate Limiting | Prevents abuse and manages LLM inference cost by capping requests per user or service | Ensures fair usage and protects against denial-of-service scenarios in shared copilots |
| Input Validation | Sanitizes and validates all incoming data to prevent injection attacks and malformed prompts | Essential for maintaining prompt integrity in AI copilot architecture deployments |
| Request Logging | Records all requests with metadata for observability, debugging, and compliance auditing | Required for regulatory compliance in India, UAE, and US financial sectors |
| Version Routing | Routes requests to the appropriate API version, enabling rolling updates without service interruption | Supports zero-downtime AI copilot model upgrades across enterprise deployments |
Deployment Models for Hybrid LLM Architecture
How you deploy your Hybrid LLM Architecture is as important as how you design it. Deployment model selection determines cost structure, latency profile, compliance posture, and operational complexity. Enterprises across different markets choose different models based on their specific regulatory and performance requirements.
Public Cloud
Fast to deploy, globally scalable. Preferred by US startups and tech firms. LLM API calls managed by cloud providers.
Private Cloud
Full data sovereignty. Preferred by regulated sectors in UAE and India. Higher cost but maximum control over LLM infrastructure.
Hybrid Cloud
Balances performance and compliance. Sensitive data stays on-premises while compute-heavy LLM inference runs on cloud bursts.
On-Premises
Maximum control and zero external data transfer. Used by defense, government, and highly regulated industries deploying Hybrid LLM Architecture.
Scalability Design in AI Copilot Systems
Scalability in Hybrid LLM Architecture is not achieved by simply adding more GPU capacity. It requires deliberate architectural decisions at every layer: how models are containerized, how retrieval indexes are sharded, how the orchestration layer handles concurrent requests, and how the API gateway manages traffic spikes.
The most scalable Hybrid LLM Architecture deployments use stateless microservices for each processing layer, enabling horizontal scaling without shared state dependencies. Vector databases are partitioned by data domain and replicated for read performance. LLM inference is served through auto-scaling endpoint pools that spin up capacity during peak hours and scale down during low-traffic periods to manage cost.
For large Indian enterprises handling millions of daily AI copilot requests across customer-facing applications, this architectural scalability is not optional. It is a baseline requirement. The same is true for US-based SaaS platforms embedding AI copilot powered by LLMs into their products, where any degradation in response time directly impacts customer satisfaction and churn.
Scalability Capabilities in Hybrid LLM Architecture
Latency Optimization in Hybrid LLM Architecture
Latency is one of the most visible performance concerns in AI copilot systems. Users in fast-paced business environments in the US, Dubai, and India expect near-instant responses. Hybrid LLM Architecture provides multiple leverage points for reducing end-to-end latency without sacrificing response quality.
The six most effective latency optimization techniques in Hybrid LLM Architecture are:
Semantic Caching
Stores embeddings of previous queries and their responses. When a semantically similar query arrives, the cached response is served instantly without invoking the LLM again.
Parallel Retrieval
Executes multiple retrieval queries simultaneously rather than sequentially, cutting RAG pipeline latency by up to 60% for multi-source AI copilot architectures.
Streaming Responses
Begins sending the LLM output token-by-token as it is generated, reducing perceived latency significantly for users of conversational AI copilot systems.
Speculative Execution
A smaller, faster model generates a draft response while the full LLM verifies or refines it in parallel, reducing total generation time in the Hybrid LLM Architecture.
Model Quantization
Reduces LLM model precision from 32-bit to 8-bit or 4-bit representations, cutting inference time and memory consumption with minimal impact on output quality.
Edge Deployment
Deploys smaller, optimized LLMs at edge nodes geographically close to users, reducing network round-trip time for latency-sensitive AI copilot deployment scenarios.
Fault-Tolerant AI Copilot Deployment Architecture
In enterprise environments, an AI copilot system that fails under load or during a model update is not just an inconvenience. It is a business risk. Fault-tolerant design in Hybrid LLM Architecture ensures that the system continues operating reliably even when individual components encounter errors, timeouts, or resource exhaustion.
The following architectural patterns are essential for building a fault-tolerant AI copilot deployment architecture using the Hybrid LLM Architecture approach:
For enterprises in the UAE and India where service level agreements govern AI copilot deployment uptime, fault-tolerant architecture is a contractual necessity. In the US, where user expectations for always-on AI copilot integration are high, graceful degradation and redundant endpoints are baseline features, not optional enhancements.
Hybrid LLM Architecture Deployment Readiness by Market
| Market | Primary Architecture Preference | Key Compliance Need | Scalability Priority |
|---|---|---|---|
| United States | Public Cloud with Hybrid LLM Architecture | SOC 2, HIPAA, CCPA | Very High |
| UAE (Dubai) | Hybrid Cloud Hybrid LLM Architecture | PDPL, DIFC Data Law | High |
| India | Private Cloud or On-Premises Hybrid LLM Architecture | DPDP Act, RBI Guidelines | Very High |
Building Enterprise AI Copilots on Hybrid LLM Architecture
Hybrid LLM Architecture is not simply a technical choice. It is a strategic commitment to building AI copilot systems that are genuinely capable of handling the complexity, variability, and scale of real enterprise operations. The companies that adopt this architecture today are building a meaningful capability advantage over those relying on simpler, single-model approaches.
From the orchestration layer to the RAG pipeline, from the API gateway to the fault-tolerant deployment architecture, every component of Hybrid LLM Architecture serves a purpose in making the AI copilot more reliable, more accurate, and more scalable. The design decisions made at each layer compound over time into a system that continues to improve as more data flows through it.
Whether you are building for a US SaaS platform, a UAE financial services firm, or a large-scale Indian enterprise, the principles of Hybrid LLM Architecture remain consistent. The specific implementation details adapt to your industry, compliance requirements, and user base. But the foundational architecture, orchestrated, retrieval-augmented, multi-layer, and fault-tolerant, is the blueprint that makes it all work.
What Hybrid LLM Architecture Delivers for Enterprise AI Copilots?
Higher Accuracy
RAG integration grounds LLM responses in verified enterprise data, reducing hallucination rates and improving factual reliability across all AI copilot queries.
Faster Responses
Semantic caching, streaming output, and parallel processing reduce end-to-end latency, meeting the real-time expectations of enterprise AI copilot users globally.
Regulatory Readiness
Flexible deployment models and data routing controls help AI copilot systems meet compliance requirements in the US, UAE, and India simultaneously.
Operational Resilience
Fault-tolerant patterns including circuit breakers and redundant endpoints ensure the AI copilot remains operational even during component failures or traffic surges.
Cost Efficiency
Intelligent routing sends simple queries to smaller, cheaper models while reserving large models for complex tasks, optimizing LLM inference spend significantly.
Future Flexibility
Modular Hybrid LLM Architecture allows enterprises to swap, upgrade, or add LLM components without rebuilding the entire AI copilot system from scratch.
Ready to Deploy a Production-Grade AI Copilot System?
Our engineering team specializes in Hybrid LLM Architecture design and AI copilot deployment for enterprises in the US, UAE, and India. Let us build it with you.
Frequently Asked Questions
Q1.1. What is Hybrid LLM Architecture and why does it matter for AI copilot systems?
Hybrid LLM Architecture combines large language models with retrieval systems, external APIs, and specialized modules. It matters because it allows AI copilot systems to deliver both deep reasoning and real-time, accurate, domain-specific responses in enterprise environments.
Q2.2. How does Hybrid LLM Architecture make AI copilots more accurate than standalone models?
In a Hybrid LLM Architecture, the language model works alongside retrieval augmented generation (RAG) systems that pull verified, up-to-date information. This prevents hallucinations and ensures the AI copilot provides factually grounded answers instead of relying solely on training data.
Q3.3. What industries in the US and UAE benefit most from Hybrid LLM Architecture in AI copilots?
Finance, legal, healthcare, and logistics sectors across the US and UAE gain the most from Hybrid LLM Architecture. These industries require both contextual reasoning and precision, which this architecture provides through its layered LLM and retrieval pipeline design.
Q4.4. Is Hybrid LLM Architecture expensive to implement for businesses in India?
The cost of Hybrid LLM Architecture for Indian businesses depends on the scale of deployment, the LLMs chosen, and the complexity of the retrieval pipeline. Many mid-size enterprises start with phased Hybrid LLM Architecture adoption to balance performance gains with investment efficiency.
Q5.5. How does the RAG pipeline work inside a Hybrid LLM Architecture for AI copilots?
In a Hybrid LLM Architecture, the RAG pipeline retrieves semantically relevant documents from a vector database in response to a user query. This retrieved context is then passed to the LLM, which synthesizes it into an accurate, contextual response for the AI copilot user.
Q6.6. What is the role of the orchestration layer in Hybrid LLM Architecture?
The orchestration layer in a Hybrid LLM Architecture manages how queries are routed between the LLM and other system components like retrieval layers, APIs, and memory modules. It acts as the decision-making backbone ensuring smooth, efficient AI copilot operation across all tasks.
Q7.7. Can Hybrid LLM Architecture support multiple LLMs at the same time?
Yes, Hybrid LLM Architecture is specifically designed to coordinate multiple LLMs simultaneously. A router within the architecture sends different query types to the most appropriate model, allowing the AI copilot to handle diverse tasks with optimized speed and accuracy.
Q8.8. How does Hybrid LLM Architecture handle latency in real-time AI copilot applications?
Hybrid LLM Architecture reduces latency through techniques like semantic caching, parallel processing, and query pre-fetching. These optimizations allow AI copilot systems to deliver near-instant responses even when processing complex multi-source retrieval and reasoning tasks.
Q9.9. What deployment models are available for Hybrid LLM Architecture in enterprise AI copilots?
Hybrid LLM Architecture can be deployed on public cloud, private cloud, on-premises, or in a hybrid cloud setup. Enterprises in regulated markets like Dubai and India often choose hybrid cloud deployments to meet data residency and compliance requirements.
Q10.10. How does Hybrid LLM Architecture ensure fault tolerance in AI copilot systems?
Fault tolerance in Hybrid LLM Architecture is achieved through redundant model endpoints, automatic failover, health check monitoring, and circuit breaker patterns. If one LLM or retrieval node fails, the architecture reroutes requests to a healthy component without interrupting AI copilot service.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.