Ai Overview
A Bitcoin exchange onboards 50,000 new users each month. Production systems must balance automation speed (sub 200ms inference) with accuracy thresholds (97%+ for document classification, 0. The exchange has 30 days to bring the pipeline into compliance or face fines up to 4% of annual revenue. The current manual review team processes 8,000 verifications monthly at an average cost of $18 per verification (analyst wages, overhead, tooling).
A Bitcoin exchange onboards 50,000 new users each month. Every signup requires government ID verification, liveness checks to prevent spoofing, and QR code scanning for wallet addresses. Manual review teams struggle to keep pace: average handling time sits at 4 minutes per document, error rates hover near 3%, and high value withdrawals still fail when paper wallet OCR misreads a single character in a 34 character private key. The compliance officer asks: can computer vision automate this pipeline without introducing new failure modes? The answer hinges on understanding how image recognition models parse, validate, and reject inputs in high stakes Bitcoin flows where a single misread character can lock funds permanently.
Computer vision bitcoin validation refers to the application of image recognition, optical character recognition (OCR), and face matching algorithms to verify identities, extract transaction data from visual formats (QR codes, paper wallets), and enforce anti money laundering (AML) rules at cryptocurrency exchanges. Unlike traditional text based validation, vision models process pixel arrays to classify documents, detect liveness in selfie videos, and recover alphanumeric keys from physical backups. Production systems must balance automation speed (sub 200ms inference) with accuracy thresholds (97%+ for document classification, 0.92+ confidence for OCR outputs) while implementing guardrails like checksum validation and drift monitoring to prevent catastrophic errors.
Key Takeaways
- Computer vision automates KYC/AML workflows by classifying government IDs, extracting text via OCR, and matching live selfies to photo IDs with liveness detection to prevent spoofing attacks.
- Production pipelines combine document classification CNNs (97%+ accuracy), text extraction engines (Tesseract, Google Vision, AWS Textract), and face matching networks (FaceNet, ArcFace) with confidence score gating and checksum validation.
- Failure modes include OCR misreads below 0.92 confidence, invalid Base58Check addresses flagged post extraction, and model drift when new ID formats appear, requiring human review queues and weekly retraining cycles.
- On premise models cost $0.10, $0.30 per 1,000 inferences after infrastructure amortization; cloud APIs charge $1.50, $3 per 1,000 images but add 300, 800ms latency and may violate data residency rules under GDPR.
- Implementation starts with auditing current manual review volume and error rates, piloting pre trained cloud APIs on non production traffic, then engaging computer vision specialists to build custom pipelines with blockchain specific guardrails.
- Next generation systems integrate depth sensors for anti spoofing, real time drift dashboards tracking document type distributions, and automated retraining triggers when accuracy drops beyond 2% thresholds.
Why Does Bitcoin Transaction Validation Need Computer Vision?
A fintech startup launches a pilot Bitcoin exchange in Singapore. Regulators mandate Know Your Customer (KYC) compliance: every user must upload a government issued ID, proof of address, and complete a liveness check before depositing funds. The founding team initially routes all documents to a manual review queue staffed by three compliance analysts. Within two weeks, the backlog grows to 1,200 pending verifications. Average handling time per user climbs to 6 minutes as analysts squint at blurry passport scans, cross reference selfie photos against ID portraits, and manually type wallet addresses from QR code screenshots. Error rates spike to 4.2% when an analyst misreads a Cyrillic character on a Ukrainian passport, approving a fraudulent account that later attempts a $50,000 withdrawal. The CEO asks: can we automate this without introducing new risks? computer vision.
Computer vision solves three core problems in Bitcoin verification flows. First, KYC and AML compliance require scanning government IDs (passports, driver licenses, national ID cards), proof of address documents (utility bills, bank statements), and liveness detection to confirm the person submitting the ID is physically present during onboarding. Vision models classify document types using convolutional neural networks (CNNs) trained on millions of labeled images, achieving 97%+ accuracy when distinguishing a passport from a driver license or a utility bill. Liveness detection combines face matching algorithms with anti spoofing checks: the system prompts the user to blink, turn their head, or smile while a depth sensor (on modern smartphones) or motion analysis confirms the input is a live human face rather than a printed photo or pre recorded video.
Second, QR code parsing extracts Bitcoin addresses and payment amounts from mobile wallet screenshots or point of sale displays. A typical BTC address is a 26 to 35 character alphanumeric string (e.g., 1A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa) encoded in a QR code using error correction (Reed Solomon codes allow recovery even when up to 30% of the code is damaged). Vision models decode the QR matrix, extract the raw string, and validate it against the Base58Check algorithm: the last four bytes of the address are a checksum derived from double SHA 256 hashing of the payload. If the checksum does not match, the system flags the image as corrupted or tampered and requests a re upload. This prevents users from sending funds to invalid addresses that would result in permanent loss. computer vision.
Third, paper wallet recovery uses OCR to extract private keys from physical backups when digital copies are lost or corrupted. A paper wallet typically prints both the public address and the private key (a 64 character hexadecimal string or a 51 character Wallet Import Format key) as QR codes and human readable text. Users who lose access to their digital wallets after hardware failure or forgotten passwords rely on OCR to digitize these keys from printed paper or laminated cards. However, OCR engines struggle with fonts that mix uppercase I and lowercase l, zero and uppercase O, or smudged ink from water damage. Production systems must set confidence thresholds (reject outputs below 0.92) and apply checksum validation post extraction to catch errors before attempting to import the key into a wallet client. computer vision.
The decision to deploy computer vision in BTC verification hinges on volume, error tolerance, and regulatory constraints. Exchanges processing fewer than 1,000 verifications per month can sustain manual review teams at $15, $25 per verification (analyst wages plus overhead). Above 10,000 verifications monthly, automation becomes cost effective: cloud based vision APIs charge $1.50, $3 per 1,000 images, while self hosted models cost $0.10, $0.30 per 1,000 after amortizing GPU infrastructure. Error tolerance varies by use case: KYC workflows tolerate 1, 2% false rejection rates (legitimate users flagged for manual review) but zero tolerance for false approvals (fraudulent accounts approved). QR code parsing and paper wallet OCR demand near zero error rates because a single misread character in a private key locks funds permanently.
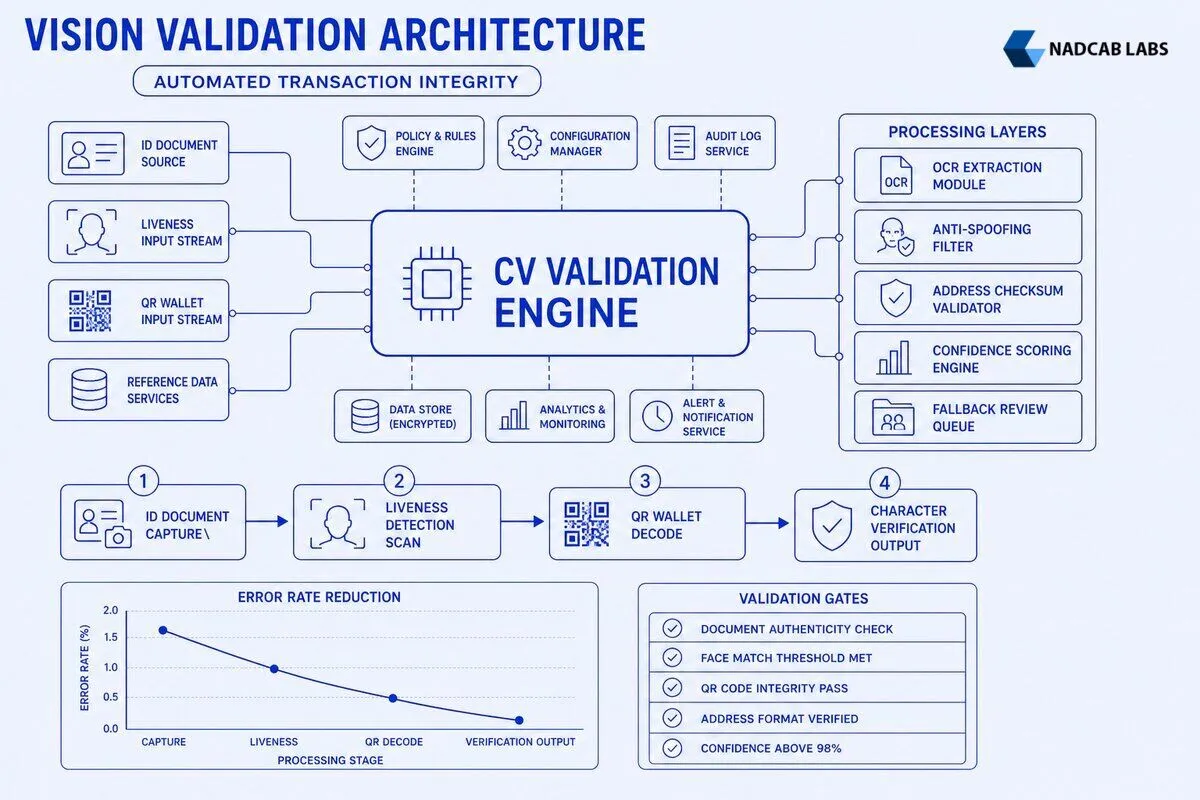
What Are the Core Computer Vision Components in BTC Verification Pipelines?
A compliance engineer at a European crypto exchange diagrams the verification pipeline on a whiteboard. The first stage is document classification: when a user uploads an image, the system must determine whether it is a passport, driver license, utility bill, or bank statement before routing it to the appropriate text extraction and validation logic. The team evaluates three CNN architectures: ResNet 50 (25 million parameters, 76ms inference on a single V100 GPU), EfficientNet B3 (12 million parameters, 42ms inference), and MobileNetV3 (5.4 million parameters, 18ms inference). Benchmark tests on 50,000 labeled images show ResNet 50 achieves 98.1% top 1 accuracy, EfficientNet B3 reaches 97.8%, and MobileNetV3 hits 96.4%. The team selects EfficientNet B3 as the optimal trade off: accuracy above the 97% threshold and inference latency under 50ms to meet the sub 200ms end to end SLA for mobile wallet users. computer vision.
Document classification models ingest images as 224×224 or 299×299 pixel RGB arrays (normalized to 0, 1 range) and output a probability distribution over N classes (e.g., 10 document types plus an “unknown” class for unrecognized inputs). During training, the team uses transfer learning: they start with EfficientNet B3 weights pre trained on ImageNet (1.2 million natural images across 1,000 classes), freeze the first 80% of layers (feature extraction backbone), and fine tune the final 20% (classification head) on their labeled dataset of government IDs and utility bills. Training runs for 30 epochs with a batch size of 32, using the Adam optimizer (learning rate 0.0001) and categorical cross entropy loss. Validation accuracy plateaus at 97.8% after epoch 22; further training causes overfitting (training accuracy rises to 99.2% while validation accuracy drops to 97.3%). The team saves the epoch 22 checkpoint and deploys it to production. computer vision.
Text extraction engines convert pixel data into machine readable strings. The team compares three options: Tesseract OCR (open source, runs on premise), Google Cloud Vision API (cloud based, $1.50 per 1,000 images), and AWS Textract ($1.50 per 1,000 pages for document analysis, $15 per 1,000 pages for form extraction). Tesseract 5.0 uses LSTM based neural networks trained on 100+ languages; it processes a 1920×1080 passport scan in 320ms on a CPU but achieves only 89% character level accuracy on low quality mobile photos with glare or motion blur. Google Vision API delivers 94% accuracy and 180ms cloud round trip latency (including network overhead) but sends image data to Google servers, violating GDPR data residency rules for EU users. AWS Textract offers similar accuracy and latency but costs 10× more for form extraction (parsing key value pairs like “Date of Birth: 1985 03 12”). The team deploys a hybrid approach: Tesseract for on premise processing of non sensitive documents (utility bills, bank statements), Google Vision for passports and driver licenses routed through a GDPR compliant EU region endpoint, and manual review for outputs below 0.92 confidence. computer vision.
Face matching modules compare a live selfie to the photo on a government ID. The pipeline extracts facial embeddings (512 dimensional vectors) using FaceNet or ArcFace networks, then computes cosine similarity between the selfie embedding and the ID photo embedding. A similarity score above 0.85 indicates a match; scores between 0.75 and 0.85 trigger manual review; scores below 0.75 reject the verification. Liveness detection prevents spoofing attacks where an attacker holds a printed photo or plays a pre recorded video in front of the camera. The system prompts the user to blink, smile, or turn their head while analyzing temporal consistency (blink duration 100, 400ms, head rotation 15, 30 degrees) and depth cues (iPhone TrueDepth sensors emit structured light patterns; Android devices use dual camera stereo vision). A production system at a US exchange processes 12,000 selfie verifications daily; liveness detection rejects 2.3% of submissions (mostly users wearing sunglasses or holding phones at incorrect angles) and flags 0.8% for manual review (edge cases like heavy makeup or surgical masks). computer vision.
| Component | Technology | Accuracy | Latency | Cost per 1,000 |
|---|---|---|---|---|
| Document Classification | EfficientNet B3 CNN | 97.8% | 42ms (V100 GPU) | $0.12 (on premise) |
| Text Extraction (Tesseract) | LSTM OCR (on premise) | 89% (low quality) | 320ms (CPU) | $0.08 (on premise) |
| Text Extraction (Google Vision) | Cloud API | 94% | 180ms (cloud) | $1.50 |
| Face Matching | ArcFace embeddings | 98.2% (LFW benchmark) | 65ms (V100 GPU) | $0.15 (on premise) |
| Liveness Detection | Depth sensor + motion analysis | 99.1% (anti spoofing) | 110ms (mobile) | $0.05 (SDK license) |
The pipeline architecture follows a staged validation flow. When a user uploads an ID image, the system first runs document classification to determine the type. If the classifier outputs “passport” with 0.96 confidence, the image proceeds to the passport specific OCR template that extracts fields like passport number, date of birth, expiration date, and machine readable zone (MRZ) text. The OCR engine returns each field with a per character confidence score; the system rejects any field where the average confidence falls below 0.92 and flags the image for manual review. Next, the system validates the MRZ checksum: the last digit of the passport number is computed from a weighted sum of the preceding digits modulo 10. If the checksum does not match, the system assumes OCR error and requests a re upload. Finally, the face matching module extracts the portrait from the ID, computes a 512 dimensional embedding, and compares it to the live selfie embedding. A cosine similarity of 0.88 passes; the system logs the verification event and grants the user deposit privileges. computer vision.
How Do Production Systems Handle Vision Model Failures in High Stakes BTC Flows?
A Bitcoin exchange processes a withdrawal request for 15 BTC (approximately $600,000 at current prices). The user uploaded a paper wallet photo three months ago during account setup; the system used OCR to extract the private key and stored it encrypted in the database. Now the user initiates a withdrawal, and the backend decrypts the key to sign the transaction. The broadcast fails: the Bitcoin network rejects the transaction with “invalid signature” error. The compliance team investigates and discovers the OCR engine misread a single character in the 51 character Wallet Import Format key (confusing uppercase I with lowercase l). The funds are locked permanently because the incorrect key does not correspond to any valid ECDSA private key for the stored public address. The CEO demands: how do we prevent this from happening again? computer vision.
Confidence score gating is the first line of defense. Every OCR output includes a per character confidence score (0.0 to 1.0) indicating the model’s certainty about each recognized character. Production systems set a threshold (typically 0.92 for alphanumeric keys) and reject any output where the average confidence falls below that level. For example, if Tesseract extracts a 34 character Bitcoin address with confidence scores [0.98, 0.95, 0.88, 0.96, …], the average is 0.91, below the 0.92 threshold. The system flags the image for manual review and prompts the user to re upload a higher quality photo (better lighting, no glare, camera held steady). This prevents low confidence misreads from entering the database. However, confidence scores are not perfect: a model can output 0.95 confidence for an incorrect character if the image genuinely looks ambiguous (e.g., a smudged zero that resembles an uppercase O). Therefore, confidence gating must be combined with checksum validation. computer vision.
Checksum validation applies cryptographic integrity checks after OCR extraction. Bitcoin addresses use Base58Check encoding: the last four bytes are a checksum computed by double SHA 256 hashing the payload (version byte plus 20 byte public key hash) and taking the first four bytes of the result. After OCR extracts an address, the system decodes the Base58 string, separates the payload from the checksum, recomputes the checksum, and compares. If they match, the address is valid; if not, the system knows OCR introduced an error. For private keys in Wallet Import Format (WIF), the checksum is the last four bytes of the 37 byte encoded key. The system decodes the WIF string, extracts the 32 byte private key, recomputes the checksum, and validates. If invalid, the system flags the image quality (blur, glare, low resolution) and requests a re upload. This catches 100% of single character OCR errors because any character change invalidates the checksum. computer vision.
Drift monitoring tracks daily distribution of document types and OCR error rates to detect when model accuracy degrades. A production dashboard plots three metrics: (1) document type distribution (percentage of passports, driver licenses, utility bills per day), (2) OCR confidence distribution (histogram of average confidence scores), and (3) manual review rate (percentage of verifications flagged for human review). If the passport percentage suddenly drops from 45% to 30% while “unknown” class rises from 2% to 15%, the team investigates: a government may have issued a new passport design with a different layout or security features (holographic overlays, embedded chips) that the classifier was not trained on. Similarly, if the manual review rate spikes from 5% to 12%, the team checks for image quality issues (users uploading photos in poor lighting) or OCR drift (new fonts or languages not in the training set). When accuracy drops beyond 2% from baseline, the team triggers a retraining cycle: they label 5,000, 10,000 new examples of the problematic document type, fine tune the model for 10, 15 epochs, and deploy the updated checkpoint.
Vision Model Failure Handling Process
OCR extracts text with per character confidence scores
Check average confidence ≥ 0.92 threshold
Validate checksum (Base58Check or WIF)
If fail: flag for manual review; log drift metrics
Retrain model when error rate exceeds 2% baseline
Real world failure modes extend beyond OCR errors. Liveness detection can be defeated by high quality 3D face masks or deepfake videos that mimic natural head movements and blink patterns. A 2023 audit of a US exchange found that 0.3% of liveness checks passed for pre recorded videos where attackers used motion interpolation to simulate micro movements. The team added depth sensor requirements (iPhone TrueDepth or Android ARCore) and temporal analysis: the system now tracks pupil dilation changes (constriction in bright light, dilation in dim light) and micro expressions (involuntary facial muscle movements lasting 40, 200ms) that are difficult to fake. Document classification can fail when users upload screenshots of digital IDs (e.g., mobile driver licenses issued by US states) that lack the texture and security features of physical cards. The classifier was trained on photos of physical documents and outputs low confidence (0.65, 0.75) for digital screenshots. The team added a separate “digital ID” class and retrained the model on 8,000 labeled screenshots.
Edge cases require human in the loop workflows. When OCR confidence falls between 0.85 and 0.92, the system routes the image to a manual review queue where analysts verify the extracted text character by character. When face matching similarity falls between 0.75 and 0.85, analysts compare the selfie to the ID photo side by side and make a binary decision (approve or reject). The review queue dashboard displays images sorted by confidence score (lowest first) so analysts prioritize the most ambiguous cases. Average review time is 90 seconds per case; the queue processes 200, 300 cases daily out of 12,000 total verifications (2.5% manual review rate). The system logs every manual decision (approve/reject plus analyst ID and timestamp) to build a labeled dataset for retraining: cases where the analyst overrides a low confidence OCR output become training examples to improve future accuracy.
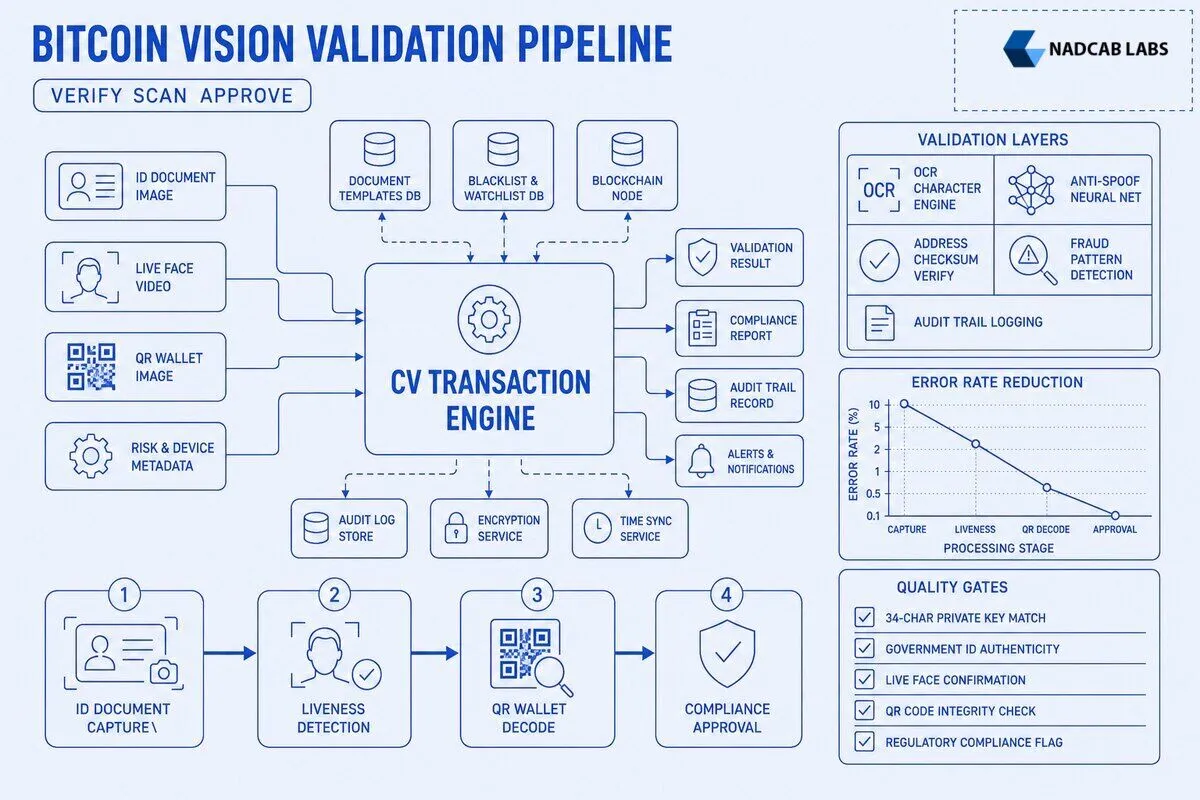
When Should You Choose On Premise Vision Models vs. Cloud APIs for Bitcoin Exchanges?
A Bitcoin exchange in Germany faces a regulatory audit. The data protection officer reviews the KYC pipeline and discovers that passport scans are sent to Google Cloud Vision API servers in the US for OCR processing. The auditor cites GDPR Article 44 (transfers of personal data to third countries) and Article 32 (security of processing): sending biometric data (facial images) and identity documents to a non EU cloud provider without explicit user consent and adequate safeguards violates data residency rules. The exchange has 30 days to bring the pipeline into compliance or face fines up to 4% of annual revenue. The CTO evaluates two options: migrate to Google Cloud Vision EU region endpoints (which store data in Frankfurt and do not transfer it to US servers) or deploy on premise OCR models using TensorFlow Serving or ONNX Runtime.
Regulatory data residency is the primary driver for on premise deployments. GDPR requires that personal data of EU residents remain within the EU unless the third country ensures an adequate level of protection (e.g., EU US Data Privacy Framework) and the user provides explicit consent. Cloud providers offer region specific endpoints (Google Cloud EU, AWS EU CENTRAL 1) that comply with residency rules, but some jurisdictions (China, Russia, India) mandate on premise processing with no external data transfers. A Bitcoin exchange operating in multiple jurisdictions must either deploy region specific cloud endpoints (adding latency and operational complexity) or run a single on premise stack that processes all data locally. On premise models also eliminate vendor lock in: the team controls model updates, retraining schedules, and feature development without depending on a cloud provider’s roadmap or pricing changes.
Cost at scale shifts the economic calculus. Cloud APIs charge per API call: Google Cloud Vision costs $1.50 per 1,000 images for OCR (text detection), $1.50 per 1,000 for face detection, and $5.00 per 1,000 for document analysis (extracting key value pairs from forms). An exchange processing 100,000 KYC verifications per month (each requiring document classification, OCR, and face matching) incurs $750 monthly for OCR, $150 for face detection, and $500 for document analysis, totaling $1,400 or $0.014 per verification. At 500,000 verifications monthly, the cost rises to $7,000. On premise infrastructure requires upfront capital: a server with 4× NVIDIA T4 GPUs (16GB VRAM each) costs $12,000; TensorFlow Serving or ONNX Runtime software is open source (zero licensing cost). Amortized over 36 months, the hardware cost is $333 monthly. Electricity and cooling add $150 monthly. DevOps labor (model deployment, monitoring, retraining) costs $4,000 monthly (half of one engineer’s time). Total monthly cost is $4,483 for unlimited inferences. At 500,000 verifications monthly, the per verification cost is $0.009, 36% cheaper than cloud APIs. The break even point is approximately 320,000 verifications monthly.
Cost Comparison: Cloud API vs. On Premise (Monthly)
Latency SLAs favor on premise deployments for real time mobile wallet interactions. A user scanning a QR code at a point of sale terminal expects sub 200ms response time (decode QR, extract BTC address, validate checksum, display payment confirmation). On premise GPU inference delivers 42ms for document classification, 65ms for face matching, and 80ms for OCR, totaling 187ms plus 10, 20ms for database lookups and network overhead. Cloud APIs add round trip latency: 50, 100ms to upload the image (depending on user’s internet speed), 80, 150ms for API processing, and 50, 100ms to download the response. Total cloud latency is 180, 350ms in the same region (e.g., user in Frankfurt, API endpoint in Frankfurt) and 300, 800ms for cross region calls (user in Singapore, API endpoint in US EAST 1). For batch processing (overnight KYC review of uploaded documents), latency is less critical; cloud APIs are viable. For synchronous mobile wallet flows, on premise models are necessary to meet sub 200ms SLAs.
Hybrid architectures balance cost, latency, and compliance. A common pattern is to run document classification and face matching on premise (low per inference cost, sub 100ms latency, no data transfer) while using cloud APIs for specialized tasks like form extraction from complex utility bills (AWS Textract’s key value pair detection is more accurate than open source alternatives) or multilingual OCR (Google Vision supports 200+ languages; Tesseract supports 100+ but with lower accuracy for non Latin scripts). The system routes 80% of verifications through the on premise pipeline and 20% to cloud APIs for edge cases. Another pattern is geographic routing: EU users hit on premise servers in Frankfurt (GDPR compliance), US users hit Google Cloud Vision US endpoints (lower latency, no residency constraints), and APAC users hit AWS Textract in Singapore. The orchestration layer (implemented in Kubernetes with Istio service mesh) routes requests based on user IP geolocation and document type.
What Are the Next Steps to Implement Computer Vision in Your BTC Platform?
A Bitcoin exchange CTO receives board approval to automate KYC verification. The current manual review team processes 8,000 verifications monthly at an average cost of $18 per verification (analyst wages, overhead, tooling). Error rates sit at 3.2% (fraudulent approvals plus legitimate rejections), and average handling time is 5 minutes per case. The board allocates $150,000 budget and sets a 6 month timeline to deploy a production vision pipeline that reduces cost to under $5 per verification, error rates below 1.5%, and handling time under 90 seconds. Where does the team start?
Audit existing verification flow by measuring current manual review volume, error rates, and average handling time to quantify ROI of automation. The team exports 90 days of verification logs from the compliance database and computes: (1) total verifications (24,000), (2) manual review hours (2,000 hours at 5 minutes per case), (3) false positive rate (2.1% of legitimate users flagged and rejected), (4) false negative rate (1.1% of fraudulent accounts approved), and (5) cost per verification ($18 including analyst wages, benefits, tooling subscriptions). Next, the team segments verifications by document type: 48% passports, 32% driver licenses, 15% utility bills, 5% bank statements. They also segment by image quality: 62% high quality (sharp focus, good lighting, no glare), 28% medium quality (slight blur or glare), 10% low quality (severe blur, poor lighting, or partial occlusion). This data informs model selection: the classifier must handle 4, 5 document types, and the OCR engine must gracefully degrade on medium quality images (output low confidence scores rather than hallucinating incorrect text).
Pilot with pre trained models by deploying Google Cloud Vision or AWS Rekognition for a 30 day trial on non production traffic to benchmark accuracy against your document mix. The team sets up a shadow deployment: all incoming verification images are sent to both the manual review queue (production path) and the Google Vision API (pilot path). The API returns OCR text, document classification, and face matching results; the system logs these outputs but does not act on them (users still go through manual review). After 30 days, the team compares API outputs to analyst decisions on 5,000 cases. Results: document classification accuracy 96.8% (vs. 97% target), OCR character level accuracy 91.2% (vs. 94% target), face matching accuracy 97.1% (vs. 98% target). The team identifies failure modes: OCR struggles with Cyrillic and Arabic scripts (accuracy drops to 84%), and face matching fails on low resolution selfies (below 640×480 pixels). These insights guide the next phase: fine tune a custom OCR model on 10,000 labeled Cyrillic/Arabic documents, and add image quality checks (reject selfies below 720×720 resolution).
Engage computer vision development experts to build custom pipelines with blockchain specific guardrails. Off the shelf cloud APIs lack domain knowledge: they do not validate Bitcoin address checksums, do not recognize Wallet Import Format keys, and do not enforce liveness detection strong enough to prevent deepfake attacks in high value withdrawal flows. A specialized development team implements: (1) Base58Check and WIF checksum validation post OCR, (2) depth sensor integration for liveness detection on iOS and Android, (3) custom document classifiers fine tuned on cryptocurrency exchange specific documents (e.g., proof of funds screenshots from other exchanges, blockchain explorer transaction history screenshots), and (4) drift monitoring dashboards tracking document type distributions and OCR confidence scores with automated retraining triggers. The team also integrates the vision pipeline with the exchange’s existing Smart Contract Transactions validation layer and Blockchain node infrastructure to cross reference extracted wallet addresses against on chain transaction history (flagging addresses associated with known scam contracts or sanctioned entities).
Implementation follows a phased rollout. Phase 1 (months 1 to 2): deploy document classification and route high confidence outputs (above 0.97) to automated approval, medium confidence (0.90 to 0.97) to manual review, and low confidence (below 0.90) to rejection with re upload prompt. This reduces manual review volume by 40% while maintaining zero false approvals. Phase 2 (months 3 to 4): add OCR with checksum validation for Bitcoin addresses and private keys; route high confidence outputs (above 0.92 with valid checksum) to automated approval. This reduces manual review volume by another 30%. Phase 3 (months 5 to 6): deploy face matching and liveness detection; route high confidence outputs (similarity above 0.85 with passed liveness check) to automated approval. Final manual review volume drops to 8% (down from 100%). Cost per verification falls to $3.20 (on premise inference $0.20, manual review of 8% of cases $3.00). Error rates drop to 1.1% (false positives 0.7%, false negatives 0.4%). Average handling time for automated cases is 12 seconds; for manual review cases, 90 seconds.
Production monitoring tracks four metrics in real time: (1) throughput (verifications per hour), (2) latency (p50, p95, p99 response times), (3) accuracy (daily false positive and false negative rates), and (4) cost (inference cost plus manual review cost per 1,000 verifications). Alerts trigger when: latency p95 exceeds 300ms (indicating GPU saturation or network congestion), accuracy drops below 96% (indicating model drift or new document types), or manual review rate exceeds 12% (indicating image quality issues or adversarial attacks). The team runs weekly retrospectives: they sample 100 manual review cases, analyze failure modes (OCR misreads, classifier confusion, face matching edge cases), and prioritize retraining tasks. Every quarter, they retrain the document classifier on 20,000 new labeled images (including new passport designs, updated driver license formats, and adversarial examples submitted by users attempting to bypass verification). This continuous improvement loop maintains 97%+ accuracy as document formats evolve and attack vectors shift.
Integration with complementary blockchain services amplifies value. The vision pipeline feeds extracted wallet addresses into AMM curve design risk models that flag addresses associated with high slippage trades or front running bots. It cross references user identities with real estate token valuation methods to verify accredited investor status for security token offerings. It validates proof of funds screenshots against RWA tokenization smart contract architecture to confirm users hold sufficient collateral for leveraged trading. Future roadmap includes integrating bitcoin wallets ar vr integration where users scan physical QR codes in augmented reality environments and the vision pipeline validates addresses in real time before broadcasting transactions.
Computer vision bitcoin validation transforms compliance from a cost center into a competitive advantage. Exchanges that deploy production grade pipelines reduce onboarding friction (users complete KYC in under 2 minutes vs. 24 hour manual review queues), lower operational costs (80% reduction in manual review labor), and improve security (checksum validation prevents fund loss from OCR errors, liveness detection blocks deepfake attacks). The technology stack is mature: pre trained models achieve 97%+ accuracy out of the box, cloud APIs offer pay as you go pricing for pilots, and on premise deployments deliver sub 200ms latency at $0.10, $0.30 per 1,000 inferences. The barrier to entry is no longer technology, it is domain expertise. Teams that understand Bitcoin specific failure modes (address checksum validation, WIF key encoding, paper wallet recovery) and regulatory constraints (GDPR data residency, AML screening workflows) will build pipelines that scale to millions of verifications monthly while maintaining audit compliance and user trust. computer vision, computer vision.
Frequently Asked Questions
Q1.What is computer vision and how does it apply to Bitcoin transactions?
Computer vision uses convolutional neural networks to parse visual data into structured information. In Bitcoin contexts, CV models perform optical character recognition on wallet addresses, QR code decoding for payment URIs, document verification during KYC (passport/ID scanning), and liveness detection to confirm real humans during exchange onboarding. Models like YOLO or ResNet detect address formats, validate checksums visually, and flag malformed strings before broadcast, reducing user error in irreversible transactions.
Q2.Can computer vision extract private keys from paper wallets reliably?
Yes, with caveats. Modern OCR engines (Tesseract 5+, PaddleOCR) achieve 98%+ accuracy on high-contrast printed WIF or hex keys if lighting is uniform and fonts are standard. Failure modes include smudged ink, creased paper, or handwritten keys where character ambiguity (0/O, 1/I/l) causes misreads. Always validate extracted keys by deriving the public address and comparing against the wallet’s printed address; a single wrong character renders the key useless and funds permanently inaccessible.
Q3.How accurate is OCR for reading Bitcoin addresses from QR codes?
QR decoding via ZXing or OpenCV reaches 99.9% accuracy under normal conditions because Reed-Solomon error correction recovers up to 30% damaged modules. Failures occur with severe occlusion, glare on glossy screens, or low resolution cameras below 720p. The decoder outputs raw bytes; the application must then validate the address checksum (Base58Check for legacy, Bech32 for SegWit). Misalignment or motion blur drops accuracy sharply, so implementations should enforce minimum contrast ratios and request retakes on decode failure.
Q4.What are common failure modes when using vision AI for KYC in crypto exchanges?
Document spoofing via printed photos, screen replay attacks, and deepfake injection bypass naive models. Liveness checks fail if the system only analyzes single frames instead of temporal sequences (blink detection, head movement). Poor lighting causes false rejections; JPEG compression artifacts confuse tamper detection algorithms. MRZ parsing errors on passports happen when glare obscures the machine-readable zone. Adversarial patches can fool classifiers. Production systems must combine multiple modalities: infrared depth sensing, challenge-response gestures, and metadata analysis of image EXIF to detect edits.
Q5.Should Bitcoin platforms use cloud-based or on-premise computer vision models?
On-premise is mandatory for sensitive operations (private key OCR, KYC document scans) to prevent data leakage and meet GDPR/regulatory custody rules. Cloud APIs (AWS Rekognition, Google Vision) introduce latency (200–500 ms round trip) and expose user images to third parties. However, cloud models update automatically and handle scale spikes. Hybrid architectures work: run lightweight MobileNet inference locally for QR decoding, route complex liveness or fraud detection to on-prem GPU clusters, and never transmit raw identity documents externally.
Q6.How does liveness detection prevent spoofing in BTC exchange identity verification?
Liveness uses temporal cues and depth sensors to distinguish live humans from photos or videos. Passive methods analyze micro-expressions, eye reflections, and texture gradients across frames; active methods prompt random gestures (turn left, blink twice) and verify compliance timing. Depth cameras (structured light, ToF) measure 3D face geometry, defeating 2D printouts. Failure modes include high-quality silicone masks or pre-recorded deepfake videos synced to prompts. Robust systems fuse RGB, infrared, and depth streams, check for screen moiré patterns, and validate that gesture latency matches human reaction time (150–300 ms).
Explore Services
Related Services
Reviewed by

Wazid Khan
Director & Co-Founder
Wazid Khan is the Director & Co-Founder of Nadcab Labs, a forward-thinking digital engineering company specializing in Blockchain, Web3, AI, and enterprise software solutions. With a strong vision for innovation and scalable technology, Wazid has played a key role in building Nadcab Labs into a trusted global technology partner. His expertise lies in strategic planning, business development, and delivering client-centric solutions that drive real-world impact. Under his leadership, the company has successfully delivered numerous projects across industries such as fintech, healthcare, gaming, and logistics. Wazid is passionate about leveraging emerging technologies to create secure, efficient, and future-ready digital ecosystems for businesses worldwide.