Ai Overview
A Bloom filter is a type of probabilistic data structure that was invented by Burton Howard Bloom in 1970. The purpose of a Bloom filter is simple: it helps you check whether an item is in a set, very quickly and without using much memory. The word probabilistic might sound complicated, but it just means the filter gives you an answer that is highly accurate rather than perfectly exact.
Key Takeaways
- 01
A Bloom filter is a fast and memory-efficient probabilistic data structure that checks whether an item is definitely not in a set or probably in a set, without storing the items themselves. - 02
Bloom filters use multiple hash functions and a bit array to mark item positions, enabling extremely fast lookups that take constant time regardless of how many items are stored in the filter. - 03
Bitcoin uses Bloom filters in SPV lightweight nodes so mobile wallets can filter relevant transactions from full nodes without downloading and processing the entire blockchain history locally. - 04
Ethereum embeds a 2048-bit Bloom filter in every block header so applications can quickly check if a contract address or log event topic appears in that block without scanning all transactions. - 05
Bloom filters can produce false positives, meaning they occasionally say something is present when it is not, but they never produce false negatives, making their definitive absence answers completely reliable. - 06
The three core components of a Bloom filter are the bit array which stores presence flags, the hash functions which map items to array positions, and the size parameters which control accuracy versus memory use. - 07
Unlike hash tables that store the full items, Bloom filters use a tiny fraction of the memory because they store only bit flags, making them ideal for resource-limited blockchain nodes and mobile wallet applications. - 08
Bloom filters cannot tell you exactly which items are in the set and standard implementations do not support deletion, which limits their use in scenarios requiring precise record keeping or frequent updates. - 09
Indian blockchain platforms building supply chain, fintech, and identity systems inherit Bloom filter infrastructure from EVM-compatible chains and can apply the same technique in their custom off-chain data pipelines. - 10
As blockchain networks scale to handle billions of transactions globally, Bloom filters and their successors like Cuckoo filters will remain essential tools for keeping lookups fast without requiring massive memory overhead.
What is a Bloom Filter
A Bloom filter is a type of probabilistic data structure that was invented by Burton Howard Bloom in 1970. The purpose of a Bloom filter is simple: it helps you check whether an item is in a set, very quickly and without using much memory. The word probabilistic might sound complicated, but it just means the filter gives you an answer that is highly accurate rather than perfectly exact. Specifically, it can tell you with absolute certainty that an item is NOT in the set, but it can only tell you that an item is PROBABLY in the set rather than guaranteeing it with one hundred percent certainty.
Think of it like a bouncer at a club who has memorized a guest list but is working from notes rather than a printed copy. If the bouncer says someone is definitely not on the list, you can trust that. If the bouncer says someone is probably on the list, there is a small chance the bouncer made a mix-up. The club still has a proper list inside to double-check if needed, but the bouncer at the door saves time for the vast majority of visitors who are clearly not on the list.
In blockchain, this same idea saves enormous amounts of time and computing power. Blockchains like Bitcoin and Ethereum contain millions of transactions and addresses. Every time a node needs to check whether a specific address or transaction appears somewhere in the chain, doing a full search through all that data would be extremely slow.
A Bloom filter can screen out the vast majority of irrelevant data almost instantly, so the full search only happens when the filter gives a positive signal. This makes the entire network faster, lighter, and more practical to use on everyday devices like mobile phones, which is exactly why Bloom filters became a core part of how Bitcoin’s lightweight wallets and Ethereum’s log system work in practice.
How Does a Bloom Filter Work
Inside a Bloom filter, there are two main things: a bit array and a set of hash functions. A bit array is just a long row of zeros and ones, like a very simple storage space where every slot holds either a 0 or a 1. At the start, every slot in the bit array is set to 0, meaning the filter is empty. Hash functions are mathematical formulas that take an input item and convert it to a number that corresponds to a position in the bit array. Bloom filters use several different hash functions at the same time, not just one.
Here is exactly how adding an item works. Say you want to add the word “apple” to a Bloom filter that uses three hash functions. You run “apple” through hash function 1, which gives you position 3. You run it through hash function 2, which gives you position 7. You run it through hash function 3, which gives you position 12. You then set the bits at positions 3, 7, and 12 to 1. The word “apple” itself is never stored.
Now when you want to check if “apple” is in the filter, you run the same three hash functions again and check whether positions 3, 7, and 12 are all set to 1. If they are, the item is probably in the set. If even one of those positions is still 0, the item is definitely not in the set.
The false positive happens because a different word might accidentally set the same three bit positions. Imagine “mango” happens to hash to positions 3, 7, and 12 as well. If you check for “mango” and “apple” was already in the filter, the filter will say “mango” is probably present even though it was never added. This is the known and accepted trade-off: an occasional wrong positive in exchange for extraordinary speed and tiny memory usage. For blockchain applications in India and globally where the data set contains millions of addresses and transactions, this trade-off is almost always worth making because the false positive rate can be tuned very low through careful parameter selection.
Why Bloom Filters Are Used in Blockchain
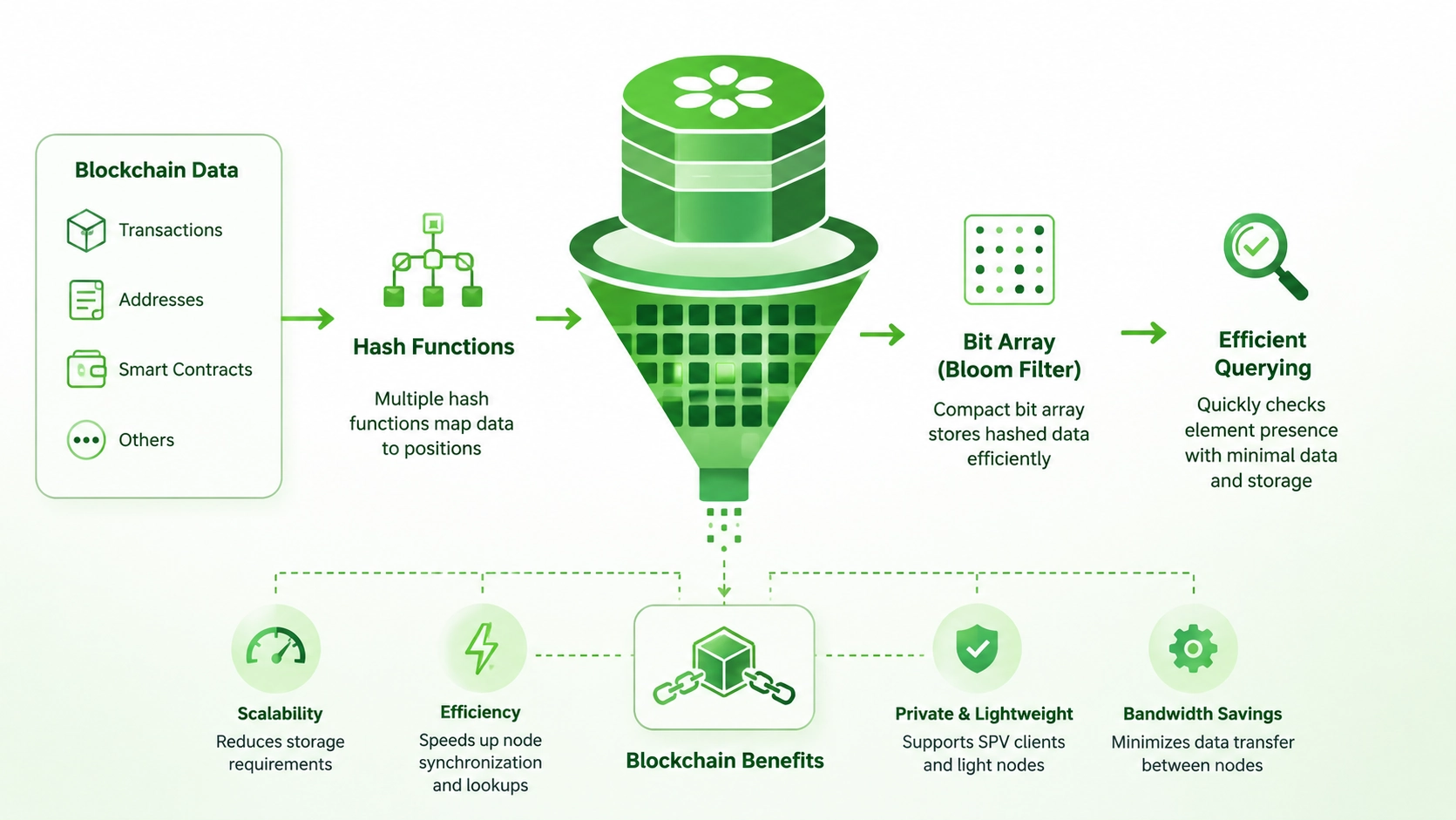
Blockchain networks have a scale problem. Bitcoin’s blockchain is hundreds of gigabytes in size and contains hundreds of millions of transactions. Ethereum’s state is even larger, with billions of events and log entries stored across millions of blocks. Any operation that requires searching through all of this data every time a node wants to answer a simple question, like whether a specific wallet address has ever interacted with a particular contract, would be unacceptably slow. Without efficient filtering tools, nodes would spend all their time doing disk reads and data comparisons rather than participating usefully in the network.
Bloom filters solve this by acting as a very fast first layer of filtering. When a node receives a query about whether an item exists somewhere in the blockchain, it checks the Bloom filter first. If the filter says the item is definitely not there, the search stops immediately. No disk access. No heavy computation. The answer is given in microseconds. Only when the filter says the item might be there does the system do the more expensive full lookup to confirm. In practice, because blockchains contain enormous numbers of transactions and only a small fraction of them are ever relevant to any given query, the Bloom filter eliminates the vast majority of unnecessary work before it even starts.
For Indian blockchain companies building on top of these protocols, understanding why Bloom filters exist helps explain many of the design decisions in the underlying infrastructure they depend on. When an Indian DeFi application queries Ethereum for all events emitted by a specific smart contract, the Ethereum node uses Bloom filters to skip blocks that definitely do not contain those events, returning results far faster than a full sequential scan would allow. This is why event queries on well-indexed Ethereum nodes remain practical even as the chain grows to hundreds of millions of blocks over time. The Bloom filter is the silent efficiency layer making this possible day after day.[1]
How Bloom Filters Work in Bitcoin SPV Nodes
SPV stands for Simplified Payment Verification. It describes how lightweight Bitcoin clients, such as mobile wallet apps, can participate in the Bitcoin network without downloading the full blockchain. Full Bitcoin nodes store the entire transaction history, which is hundreds of gigabytes and growing. That is not realistic for a phone. SPV nodes instead download only block headers, which are tiny summaries of each block, and then ask full nodes to send them only the transactions that are relevant to their wallet addresses. This is where Bloom filters come in.
The SPV client creates a Bloom filter loaded with its own wallet addresses and transaction IDs that it cares about. It sends this filter to a full node it connects to. The full node then processes new blocks through this filter and only sends transactions that match, rather than sending everything. The mobile wallet receives only the small slice of blockchain activity that relates to its own addresses, checking it quickly and efficiently without ever having to download the full chain. This interaction between lightweight wallets and full nodes using Bloom filters was formalized in Bitcoin Improvement Proposal BIP 37, which became a standard part of how mobile Bitcoin wallets operate at scale.
For Indian Bitcoin users using mobile wallets on relatively slower internet connections in tier 2 and tier 3 cities, this architecture makes a meaningful practical difference. Without Bloom filter-based SPV, running a Bitcoin wallet on a smartphone would require syncing gigabytes of data just to check your balance. With it, the wallet syncs in seconds and receives only the transactions that matter to you. It is worth noting that BIP 37 was later supplemented by BIP 157 and BIP 158 which introduced Compact Block Filters as a more privacy-respecting alternative to Bloom filters for SPV, though both serve the same fundamental purpose of allowing lightweight clients to filter relevant blockchain data efficiently.
How Ethereum Uses Bloom Filters in Transaction Logs
Ethereum uses Bloom filters in a slightly different way compared to Bitcoin. In Ethereum, smart contracts emit events when things happen, like a token transfer being completed, a governance vote being cast, or a liquidity pool being updated. These events are recorded in something called transaction logs, and these logs can be searched by applications that need to track what has happened on the network. The problem is that Ethereum processes millions of transactions and log entries. Scanning every log in every block to find the ones relevant to a particular application would be extremely slow.
Ethereum’s solution is to include a Bloom filter in every block header. This Bloom filter is built from all the log entries in that block, specifically from the addresses of the contracts that emitted events and the topic hashes of those events. When an application wants to search for all instances of a specific event, like all Transfer events from a particular ERC-20 token contract, it checks each block’s header Bloom filter first. If the filter says the relevant address and topic are definitely not in a block, that entire block is skipped without opening it. Only blocks where the Bloom filter gives a positive signal are fully opened and scanned in detail.
This is a 2048-bit Bloom filter, meaning the bit array has 2048 positions. Ethereum uses three hash functions to map each log entry topic to three positions in this array. The result is a very compact filter that travels with every block header and enables fast log searching across the entire history of the chain. For Indian DeFi applications running on Ethereum or EVM-compatible chains like Polygon, this Bloom filter system is what makes it practical to build tools that track token movements, governance activity, and protocol events across millions of blocks without building and maintaining a separate indexing database from scratch.
What is a False Positive in a Bloom Filter
A false positive is when a Bloom filter tells you that an item is probably in the set, but when you do the full lookup to confirm, the item is actually not there at all. This happens because different items can accidentally set the same combination of bit positions in the filter. When you check for an item that was never added, all its bit positions might happen to already be set to 1 by other items that were added earlier, making the filter give an incorrect positive signal.
False positives are not a bug in Bloom filters. They are a known and accepted property that comes with the benefit of using far less memory than a perfect exact lookup system would require. The key design choice is controlling how often false positives happen. You can reduce the false positive rate by making the bit array bigger, which gives more room before collisions happen, or by adding more hash functions, which requires more bits per item but spreads the marking more uniquely. The trade-off is always between the false positive rate, the memory used, and the number of items stored.
In blockchain terms, a false positive in a Bloom filter means the node opens a block or searches a full record it did not actually need to, because the filter suggested a match that turned out to be wrong. This is a wasted effort but not a catastrophic one. The correct answer is always found at the full lookup stage. The filter saves enormous work on the true negatives, the many items that are definitely not present, and the occasional false positive is just a minor inefficiency rather than an error in the final result.
For Indian developers building tools that interact with Ethereum logs, understanding this false positive behavior helps explain why Bloom filter-based queries sometimes return extra blocks that need to be filtered again at the application layer.
What Are the Key Components of a Bloom Filter in Blockchain
A Bloom filter has three main components that work together to make it fast and memory-efficient. Understanding each one helps you grasp why the filter behaves the way it does in different blockchain contexts. The design of these components determines everything about the filter’s performance: how accurate it is, how much memory it uses, and how fast it runs. Getting these parameters right is a practical engineering decision that blockchain protocol designers have made carefully in both Bitcoin and Ethereum, and that any developer building custom blockchain tools in India needs to understand when applying the same pattern.
| Component | What It Does | Effect on Performance | Blockchain Example |
|---|---|---|---|
| Bit Array | Stores 0 or 1 flags at each position. Starts all zeros. Positions set to 1 when items are added. | Larger array means lower false positive rate but more memory used by the filter | Ethereum: 2048 bits per block |
| Hash Functions | Convert items to bit array positions. Multiple independent functions used simultaneously for each item added. | More hash functions reduce false positives but slow insertion and lookup operations slightly | Ethereum: 3 hash functions per log |
| Filter Size Parameter | The total number of bit positions available. Set at creation time based on expected item count and desired accuracy. | Must be sized for expected load. Overfull filter produces too many false positives to be useful | Bitcoin SPV: dynamic per wallet |
| False Positive Rate | Target accuracy setting chosen at design time. Controls how often the filter says yes when the answer should be no. | Lower rate requires bigger array and more memory. Typical targets range from 0.1% to 1% in blockchain use | Bitcoin BIP 37: tunable by client |
How Bloom Filters Make Blockchain Faster and More Efficient
The speed improvement that Bloom filters bring to blockchain operations comes from one simple fact: they let you skip work. In any large data system, the most expensive operations are the ones that do unnecessary searches. When a node needs to find something, the worst case is searching every record in the system. Bloom filters change the average case dramatically by allowing the system to skip the vast majority of records without even looking at them.
On Ethereum, imagine a decentralized exchange application that wants to find all liquidity pool events from a specific contract across the last 10 million blocks. Without Bloom filters, the application’s node would need to open every block, inspect every transaction receipt, and scan every log entry. With the Bloom filter in each block header, the node checks the 2048-bit filter first.
For the vast majority of blocks that do not contain any events from the target contract, the filter returns a definitive no and the block is skipped entirely. Only the much smaller subset of blocks where the filter returns yes are fully opened and searched. The result is a query that might take days without Bloom filters finishing in minutes with them.
The memory efficiency is equally impressive. Storing a list of ten million transaction hashes to check against would require gigabytes of memory. A Bloom filter covering the same ten million items with a 1% false positive rate requires only about 12 megabytes, roughly a 250 times reduction in memory use. For Indian blockchain nodes operating on standard cloud infrastructure or local hardware with limited RAM, this memory efficiency directly reduces the infrastructure cost of running archive nodes, indexers, and custom data analysis tools that need to scan large portions of the blockchain history efficiently on a daily basis.
What Are the Limitations of Bloom Filters in Blockchain
Bloom filters are powerful but not perfect. They have specific limitations that make them unsuitable for certain types of blockchain operations, and understanding these limits helps developers know when to use them and when to choose a different approach. The most important limitation is the false positive issue already discussed: the filter can occasionally say an item is present when it is not, which means a backup confirmation step is always needed after a positive result. This is a manageable trade-off in read-heavy searching scenarios but can be a problem in systems that need to act immediately on the first result without any confirmation step.
The second major limitation is that standard Bloom filters do not support deletion. Once an item is added, its bit positions are marked and those marks cannot be safely removed because other items might share the same positions. If you remove an item’s bits, you might accidentally invalidate the presence of other items that share those bit positions. This makes Bloom filters unsuitable for blockchain use cases where items need to be tracked and then removed from a membership set, such as managing a live list of pending unconfirmed transactions where items are added and later removed after confirmation.
The third limitation is privacy. In Bitcoin’s BIP 37 SPV implementation, the Bloom filter that a mobile wallet sends to a full node reveals information about which addresses the wallet is interested in. Even though the filter is probabilistic and not an exact list, a motivated full node can make educated guesses about which wallet addresses correspond to the filter entries. This is why privacy-focused improvements like BIP 157 and BIP 158 Compact Block Filters were developed, shifting the filtering logic to the client side so the full node never receives a filter describing the wallet’s interests at all. For Indian privacy-conscious users, this is a relevant concern when choosing between different wallet types that use different syncing methods.
How Bloom Filters Are Different From Hash Tables in Blockchain
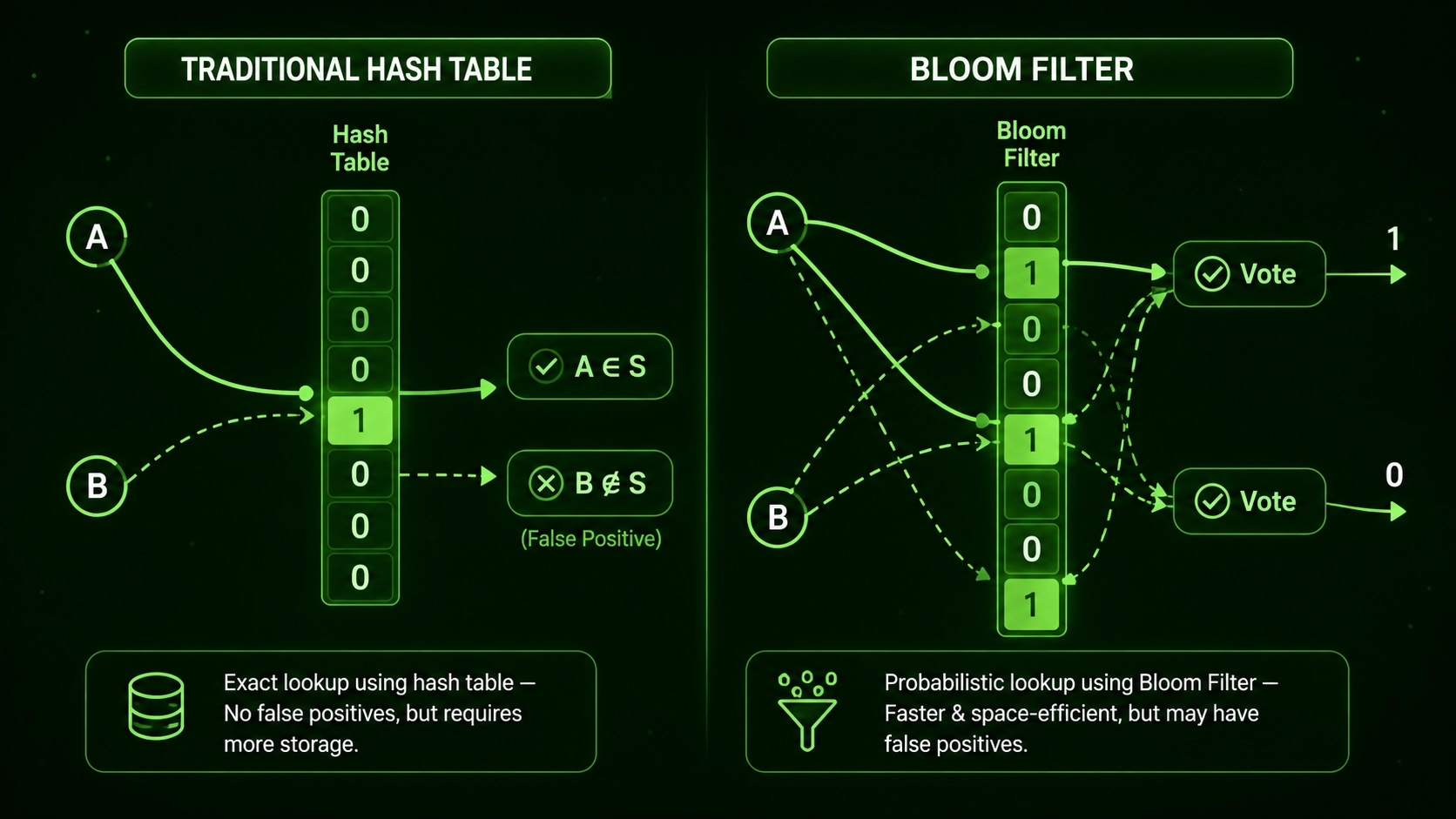
Developers new to Bloom filters often wonder how they compare to hash tables, which are the most familiar fast lookup data structure in most programming contexts. Both use hash functions, but they work in completely different ways and are suited to very different tasks in blockchain engineering. Understanding the comparison helps you know which to reach for when designing a specific component of your blockchain application stack.
A hash table stores the actual items. When you look something up in a hash table, you get a definitive yes or no answer, and you can also retrieve the stored item itself. Hash tables are exact and reliable. The cost of this reliability is memory: a hash table must store every item, meaning its memory usage grows proportionally with the number of items stored. For a blockchain that tracks hundreds of millions of transactions, a hash table covering all of them would consume enormous amounts of RAM on every node. Hash tables also support deletion straightforwardly, which is an advantage over Bloom filters in dynamic use cases.
| Feature | Bloom Filter | Hash Table |
|---|---|---|
| Stores Actual Items | No | Yes |
| Memory Usage | Very Low | Grows With Items |
| Answer Accuracy | Probabilistic | Exact |
| Supports Deletion | No (Standard) | Yes |
| Lookup Speed | Very Fast | Fast |
| Best Blockchain Use | Filtering large data sets quickly with low memory | Exact lookup where confirmed presence needed |
Real World Examples of Bloom Filters Being Used in Blockchain
Bloom filters are not just a textbook concept. They show up in the actual code of the blockchain protocols and tools that millions of people use every day. Looking at specific real-world examples makes their role concrete and helps developers understand where and how to apply the same pattern in their own work. Here are the most important and interesting live deployments of Bloom filters in blockchain systems that are relevant to anyone building in the Indian blockchain space in 2026.
Bitcoin mobile wallets using BIP 37 are the most widely deployed example. Applications like older versions of Bitcoin Wallet for Android used Bloom filters to tell connected full nodes which addresses to watch. This allowed users to sync their transaction history in seconds rather than hours. While BIP 37 has privacy limitations that led to BIP 158 Compact Block Filters being developed as a more private alternative, BIP 37 demonstrated how powerful the Bloom filter concept is for enabling lightweight blockchain clients at massive scale across different network conditions including those common in India.
Ethereum’s logsBloom field in every block header is another live example that affects billions of daily operations. Every time a web3 application calls eth_getLogs to search for contract events, the underlying client uses the block header Bloom filters to skip irrelevant blocks. The Graph Protocol, which is a popular indexing layer used by most major DeFi applications globally including those with Indian user bases, also uses Bloom filter logic internally when scanning Ethereum blocks to index events into queryable subgraphs. Without this filtering layer, indexing the entire Ethereum history to power application queries would be prohibitively slow even with powerful hardware. Bloom filters keep the whole system practical at the scale the ecosystem now operates.
What is the Future of Bloom Filters in Blockchain Technology
Bloom filters have been part of blockchain infrastructure for over a decade and they are not going away. As blockchain networks grow in scale and complexity, the need for fast, memory-efficient set membership checking only increases. However, the field of probabilistic data structures has also advanced, producing improved alternatives that address some of the classic limitations of standard Bloom filters, and these newer structures are beginning to appear in blockchain tooling aimed at the next generation of network scale.
Cuckoo filters are one of the most practical successors gaining adoption. Unlike standard Bloom filters, Cuckoo filters support deletion, making them suitable for dynamic blockchain use cases where items need to be added and removed from the tracked set.
They also achieve similar or slightly better false positive rates with comparable memory usage, and they are faster for lookups when the filter is moderately full. Bitcoin’s BIP 158 Compact Block Filters represent a different direction: instead of a filter sent by the client to the server, the server computes and serves a filter that the client downloads and queries locally, preserving privacy while still enabling fast filtering.
This architectural shift shows how the core Bloom filter insight, fast set membership checking with low memory, continues to inspire new designs even as the specific implementation evolves. For Indian blockchain engineers and platform builders in 2026, the practical takeaway is that Bloom filter thinking, using probabilistic first-pass filtering before committing to expensive full lookups, is a pattern that belongs in any high-throughput blockchain data pipeline.
Whether you are building a custom transaction indexer for an Indian DeFi protocol, a smart contract event monitoring service for a supply chain application, or a lightweight client for a mobile-first blockchain payment product, the Bloom filter remains one of the most effective tools available for keeping your system fast and memory-efficient as the data it processes grows. The fundamentals Bloom established in 1970 remain as relevant to blockchain engineering in 2026 as they were to database engineering in the decades that followed their original invention.
Frequently Asked Questions
Q1.1. What is a Bloom filter in simple words?
A Bloom filter is a fast memory-saving tool that tells you whether something is definitely not in a list or probably is in a list. It works by using hash functions and a bit array to check for membership without storing the actual items themselves in the data structure.
Q2.2. How does a Bloom filter work in blockchain?
A Bloom filter uses multiple hash functions to mark positions in a bit array when an item is added. When checking if an item exists, it hashes the item and checks those positions. If all positions are set to one, the item is probably present. If any position is zero, it is definitely absent.
Q3.3. Why do Bitcoin and Ethereum both use Bloom filters?
Bitcoin uses Bloom filters in SPV lightweight nodes so mobile wallets can filter relevant transactions without downloading the full chain. Ethereum uses Bloom filters in block headers so applications can quickly check whether a transaction log event or contract address appears in a block without scanning every record.
Q4.4. What is a false positive in a Bloom filter?
A false positive happens when a Bloom filter says an item is probably in the set but it is actually not there. This occurs because different items can map to the same bit positions by coincidence. False positives are a known and managed trade-off in exchange for the speed and memory savings the filter provides.
Q5.5. Can a Bloom filter give a false negative?
No. A Bloom filter never gives a false negative. If the filter says an item is definitely not present, you can trust that result with complete certainty. This is the core guarantee that makes Bloom filters so useful in blockchain systems where avoiding unnecessary heavy lookups matters the most.
Q6.6. How big should a Bloom filter be for blockchain use?
The ideal size of a Bloom filter depends on how many items you plan to store and what false positive rate you can accept. A larger bit array reduces false positives. Ethereum’s block header Bloom filter is fixed at 2048 bits. Bitcoin’s SPV Bloom filters are sized dynamically based on the wallet’s transaction count and desired accuracy.
Q7.7. Are Bloom filters used in any Indian blockchain projects?
Yes, Indian blockchain platforms building supply chain traceability, fintech identity verification, and enterprise data pipelines use Bloom filters internally to speed up set membership checks. Any Indian DeFi or tokenization platform built on Ethereum or EVM-compatible chains inherits Bloom filter functionality directly from the base protocol’s log filtering architecture.
Q8.8. How is a Bloom filter different from a regular database lookup?
A regular database lookup checks exact records and tells you definitively whether something exists. It uses more memory and is slower for large data sets. A Bloom filter uses a fraction of the memory and checks millions of items per second but may occasionally say something is present when it is not, requiring a backup exact check in those rare cases.
Q9.9. Can items be removed from a Bloom filter once added?
Standard Bloom filters do not support deletion because removing an item could accidentally clear bits shared by other items. A variant called a Counting Bloom filter replaces each bit with a small counter that can be incremented and decremented, allowing deletions while maintaining the filter’s probabilistic properties for blockchain use cases that require updates.
Q10.10. What happens if a Bloom filter gets too full in blockchain?
As more items are added to a Bloom filter, the bit array fills up and the false positive rate increases. When too many bits are set to one, almost every lookup returns a false positive, making the filter useless. Blockchain systems handle this by sizing filters appropriately at design time or rebuilding them periodically to maintain an acceptable accuracy level.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.