Ai Overview
Artificial Intelligence has transformed from an academic curiosity into a fundamental business capability that powers everything from recommendation engines to autonomous vehicles. The training infrastructure architecture must balance cost efficiency with the need for rapid experimentation cycles. Organizations typically choose between on premises GPU clusters, cloud based compute services, or hybrid approaches depending on their scale and budget constraints.
Key Takeaways
- AI system architecture encompasses the entire journey from raw data collection through model deployment and continuous monitoring in production environments.
- Feature stores have become essential components that bridge the gap between data engineering and machine learning teams, ensuring consistency across training and inference.
- MLOps practices integrate DevOps principles with machine learning workflows to automate training, testing, and deployment pipelines effectively.
- Data quality and preprocessing account for approximately 80% of the effort in successful AI projects, making robust ETL pipelines critical infrastructure.
- Model drift detection and performance monitoring are not optional extras but fundamental requirements for maintaining AI system reliability over time.
- Edge deployment strategies enable AI inference on resource-constrained devices, reducing latency and enabling offline functionality for distributed applications.
- Security and governance frameworks must be embedded from the initial architecture design phase rather than retrofitted after deployment.
- Hybrid storage architectures combining data lakes and data warehouses provide the flexibility needed for both exploratory analysis and production workloads.
- Experiment tracking and model versioning systems are indispensable for reproducibility and regulatory compliance in enterprise AI implementations.
- Continuous improvement cycles powered by feedback loops and A/B testing frameworks ensure AI systems evolve with changing business requirements and data patterns.
Introduction to AI System Architecture
Artificial Intelligence has transformed from an academic curiosity into a fundamental business capability that powers everything from recommendation engines to autonomous vehicles. However, the journey from a promising machine learning model in a Jupyter notebook to a production ready system serving millions of users involves intricate architectural decisions that determine success or failure. Understanding how AI systems are architected from data to deployment is essential for organizations seeking to leverage intelligent automation effectively.
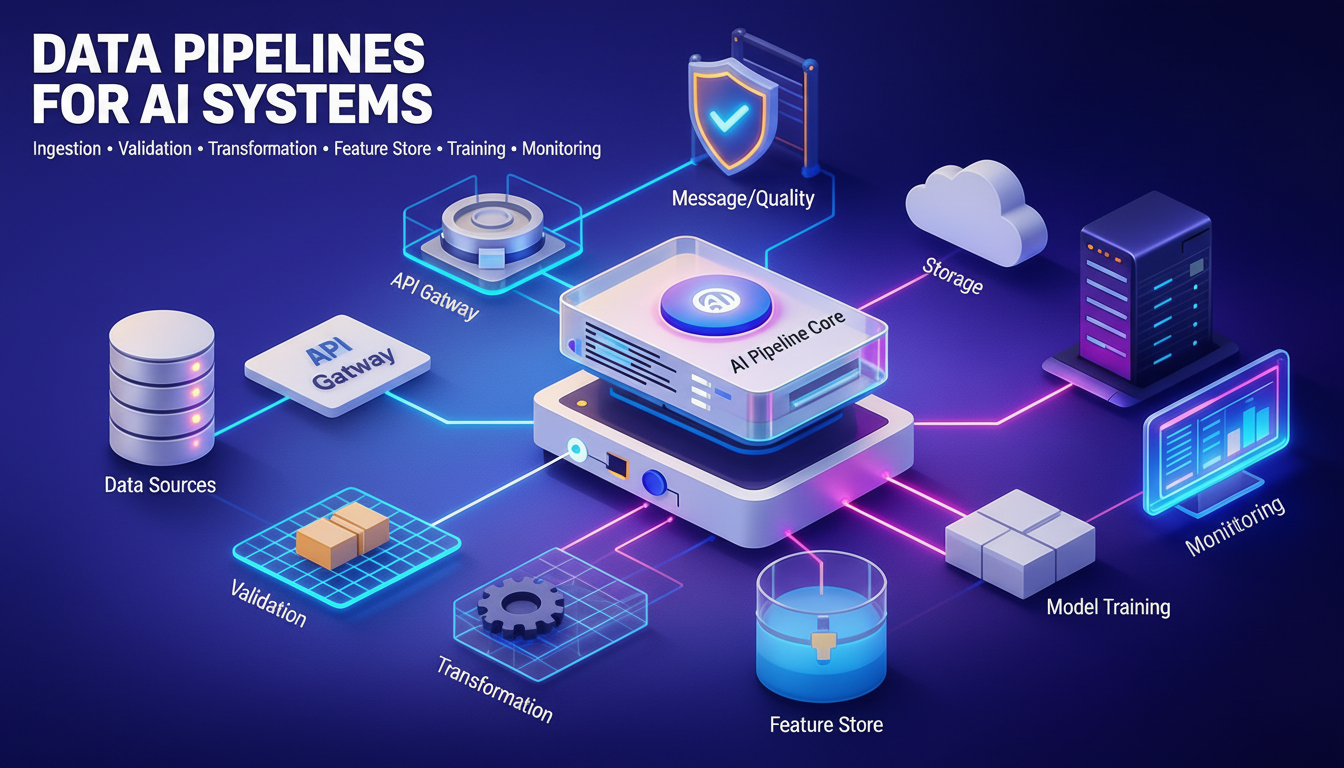
The architecture of an AI system is not merely about selecting the right algorithm or training a model with high accuracy. It encompasses data infrastructure, compute resources, deployment strategies, monitoring systems, and governance frameworks that work in harmony. Much like how DAOs in DeFi Space require robust smart contract architecture and governance mechanisms, AI systems demand a comprehensive blueprint that addresses every stage of the machine learning lifecycle.
This guide explores the complete architecture of AI systems, providing insights into each component from data collection to production deployment. Whether you are building your first machine learning pipeline or optimizing an existing enterprise AI platform, understanding these architectural patterns will help you create systems that are scalable, maintainable, and aligned with business objectives.
Understanding the End to End AI Lifecycle
The AI lifecycle represents a continuous loop of activities that transform raw data into actionable intelligence. Unlike traditional software engineering where code is written once and deployed, AI systems require constant iteration as data patterns evolve and model performance degrades over time. Understanding this lifecycle is fundamental to designing architectures that support long term success.
The Seven Stages of AI System Lifecycle
Stage 1: Problem Definition
Identifying business objectives and translating them into measurable AI use cases with clear success metrics.
Stage 2: Data Acquisition
Collecting, ingesting, and storing data from diverse sources while ensuring quality and compliance.
Stage 3: Data Preparation
Cleaning, transforming, and engineering features that enable machine learning algorithms to learn effectively.
Stage 4: Model Building
Selecting algorithms, training models, and optimizing hyperparameters through systematic experimentation.
Stage 5: Validation
Testing model performance against held out data and evaluating against business requirements.
Stage 6: Deployment
Packaging and deploying models to production environments with appropriate serving infrastructure.
Stage 7: Monitoring
Tracking performance, detecting drift, and triggering retraining cycles when necessary.
Each stage feeds into the next while also creating feedback loops that inform earlier stages. For instance, monitoring insights from production might reveal the need for additional data sources or different feature engineering approaches. This iterative nature means that AI architecture must support flexibility and rapid experimentation alongside stability and reliability in production.
Defining Business Objectives and AI Use Cases
Successful AI implementations begin with clearly defined business objectives rather than technology exploration. Organizations that start with a specific problem to solve and measurable outcomes to achieve are far more likely to realize value from their AI investments. This alignment between business needs and technical capabilities forms the foundation of effective AI architecture.
When defining AI use cases, consider the following parameters that influence architectural decisions:
AI Use Case Classification Matrix
| Use Case Type | Latency Requirement | Data Volume | Architecture Pattern |
|---|---|---|---|
| Fraud Detection | Real time (milliseconds) | High throughput streaming | Event driven microservices |
| Customer Segmentation | Batch (hours) | Large historical datasets | Batch processing pipeline |
| Recommendation Engine | Near real time (seconds) | Mixed batch and streaming | Lambda architecture |
| Predictive Maintenance | Near real time | IoT sensor streams | Edge plus cloud hybrid |
| Document Processing | Asynchronous (minutes) | Variable document loads | Queue based processing |
The choice of architecture pattern directly impacts infrastructure costs, scalability, and maintainability. Just as decentralized autonomous organizations require careful consideration of governance structures, AI systems demand thoughtful alignment between technical architecture and organizational capabilities.
Data Sources and Data Collection Strategies
Data is the lifeblood of any AI system, and the quality and diversity of data sources directly determine the capabilities of the resulting models. Modern AI architectures must accommodate a wide variety of data sources ranging from structured transactional databases to unstructured text, images, and sensor streams. Building robust collection strategies ensures a steady flow of high-quality data that keeps models accurate and relevant.
Primary data sources for enterprise AI systems typically include internal transactional databases that capture business operations, customer interaction logs from web and mobile applications, third-party data providers offering enrichment datasets, IoT devices generating real time sensor readings, and public datasets that provide benchmark training data. Each source presents unique challenges in terms of access patterns, data formats, and update frequencies.
Statement on Data Collection Best Practices
“The most sophisticated machine learning algorithm cannot compensate for poor data quality or incomplete data coverage. Organizations should invest disproportionately in data infrastructure relative to model complexity, as data improvements yield more reliable and sustainable performance gains than algorithmic optimizations alone.”
Effective data collection strategies also address compliance requirements such as GDPR, CCPA, and industry-specific regulations. Data lineage tracking, consent management, and anonymization pipelines must be built into the collection architecture from the beginning rather than added as afterthoughts.
Also Read: AI Application Complete Guide to Use Cases, Benefits, Process, and Hiring Professionals in 2026
Data Ingestion Pipelines and ETL Architecture
Data ingestion pipelines form the nervous system of AI architecture, responsible for moving data from source systems into centralized storage where it can be processed and analyzed, often built with the support of specialized data engineering consulting services. The traditional Extract, Transform, Load (ETL) pattern has evolved into more flexible approaches including ELT (Extract, Load, Transform) and real time streaming architectures that better accommodate the diverse needs of machine learning workloads.
Modern ingestion architectures typically employ a combination of batch and streaming patterns. Batch ingestion handles large historical data loads and periodic synchronization with source systems, while streaming ingestion captures real time events for immediate processing. Tools like Apache Kafka, Apache Spark, and cloud native services such as AWS Kinesis or Google Cloud Dataflow provide the building blocks for these pipelines.
ETL vs ELT Architecture Comparison
| Parameter | ETL Approach | ELT Approach |
|---|---|---|
| Transformation Location | Dedicated processing layer | Within the data warehouse |
| Scalability | Limited by processing capacity | Leverages warehouse scale |
| Raw Data Retention | Often discarded after transform | Preserved in data lake |
| Flexibility | Schema defined upfront | Schema on read flexibility |
| Best For | Structured, predictable data | Exploratory, diverse data |
The choice between ETL and ELT depends on factors including data volume, transformation complexity, and the analytical flexibility required by data science teams. Many organizations adopt hybrid approaches that use ETL for well-understood, structured data flows while leveraging ELT for exploratory machine learning workloads.
Data Cleaning, Labeling, and Preprocessing Layers
Raw data rarely arrives in a form suitable for machine learning. Data cleaning and preprocessing pipelines address issues such as missing values, inconsistent formats, outliers, and noise that would otherwise compromise model quality. This stage often consumes the majority of effort in AI projects, with industry estimates suggesting that data preparation accounts for 60 to 80 percent of total project time.
Key preprocessing activities include handling missing data through imputation or removal strategies, normalizing numerical features to consistent scales, encoding categorical variables into numerical representations, detecting and treating outliers that could skew model training, and validating data against quality constraints. These operations must be codified into reproducible pipelines that can be applied consistently to both training and inference data.
Example: Data Quality Pipeline for Financial Services
Consider a credit scoring application where data quality directly impacts risk assessment accuracy. The preprocessing pipeline might include:
1. Deduplication: Identifying and merging duplicate customer records using fuzzy matching algorithms.
2. Standardization: Converting addresses, phone numbers, and dates to consistent formats.
3. Enrichment: Augmenting internal data with external credit bureau information.
4. Validation: Checking for logical consistency such as age ranges and income levels.
5. Anonymization: Masking personally identifiable information for model training datasets.
For supervised learning applications, data labeling represents another critical preprocessing activity. Whether performed manually by human annotators or through semi-automated approaches, labeling quality directly impacts model performance. Modern labeling platforms incorporate quality assurance mechanisms, inter-annotator agreement metrics, and active learning strategies that prioritize the most informative examples for annotation.
Data Storage Architecture: Data Lakes vs Data Warehouses
The choice of data storage architecture significantly influences what kinds of analysis and machine learning are possible. Data lakes and data warehouses represent two complementary approaches, each with distinct strengths that make them suitable for different aspects of AI workloads. Modern architectures increasingly adopt hybrid patterns that leverage both paradigms.
Data Lake vs Data Warehouse Comparison
| Characteristic | Data Lake | Data Warehouse |
|---|---|---|
| Data Types | Structured, semi-structured, unstructured | Primarily structured |
| Schema | Schema on read | Schema on write |
| Processing | Batch and streaming | Batch oriented |
| Cost Model | Low-cost storage, compute on demand | Higher cost, optimized performance |
| Primary Users | Data scientists, ML engineers | Business analysts, reporting |
| AI Suitability | Excellent for training data | Good for feature engineering |
The lakehouse architecture has emerged as a modern pattern that combines data lake flexibility with data warehouse performance. Technologies like Delta Lake, Apache Iceberg, and Apache Hudi add ACID transactions, schema enforcement, and time travel capabilities to data lake storage, enabling both exploratory machine learning and production analytics on the same platform.
Organizations building AI systems should design storage architecture with versioning and reproducibility in mind. The ability to recreate the exact dataset used to train a specific model version is essential for debugging, compliance, and continuous improvement processes.
Feature Engineering and Feature Store Design
Feature engineering transforms raw data into meaningful inputs that machine learning algorithms can effectively learn from. This process requires both domain expertise and technical skill, as the quality of features often matters more than the choice of algorithm. Well engineered features capture the underlying patterns in data that drive predictions, while poorly designed features can introduce noise, bias, or data leakage.
Feature stores have emerged as a critical architectural component that addresses common challenges in feature engineering at scale. A feature store provides a centralized repository for storing, discovering, and serving features across the organization. This infrastructure enables feature reuse across multiple models, ensures consistency between training and serving environments, and accelerates the path from experimentation to production.
Core Components of a Feature Store
Feature Registry
Metadata catalog documenting feature definitions, ownership, and lineage
Online Store
Low-latency storage for real-time feature serving during inference
Offline Store
Bulk storage for historical features used in model training
Transformation Engine
Pipeline for computing and materializing features at scale
Leading feature store implementations include Feast (open source), Tecton, Databricks Feature Store, and cloud native offerings from major providers. The choice depends on factors such as existing infrastructure, latency requirements, and team expertise. Similar to how DAOs in DeFi Space rely on shared infrastructure for governance, feature stores create shared data assets that democratize access to high-quality features across data science teams.
Model Selection and Algorithm Architecture
Selecting the appropriate model architecture is a critical decision that balances predictive performance against operational constraints such as latency, interpretability, and resource consumption. The choice depends on the nature of the problem, available data, and deployment requirements. Modern AI architectures often employ multiple models working together, with different algorithms handling different aspects of a complex problem.
Traditional machine learning algorithms like gradient boosting, random forests, and logistic regression remain highly effective for structured tabular data and offer advantages in interpretability and training efficiency. Deep learning architectures excel at unstructured data, including images, text, and audio, with transformer models currently dominating natural language processing and increasingly influencing computer vision applications.
Model Architecture Selection Guide
| Data Type | Recommended Architectures | Key Considerations |
|---|---|---|
| Structured Tabular | XGBoost, LightGBM, CatBoost, Neural Networks | Interpretability, feature importance |
| Natural Language | Transformers (BERT, GPT), LLMs | Compute cost, fine tuning needs |
| Images | CNNs, Vision Transformers, ResNet | Transfer learning, augmentation |
| Time Series | LSTM, Temporal CNNs, Prophet | Seasonality, stationarity |
| Graph Data | GNNs, GraphSAGE, GAT | Scalability, neighborhood sampling |
Ensemble approaches that combine multiple models often achieve the best performance in production systems. Techniques such as model stacking, boosting, and bagging can improve both accuracy and robustness while potentially reducing variance in predictions.
Training Infrastructure and Compute Architecture
Training machine learning models requires substantial computational resources, particularly for deep learning applications that process large datasets. The training infrastructure architecture must balance cost efficiency with the need for rapid experimentation cycles. Organizations typically choose between on premises GPU clusters, cloud based compute services, or hybrid approaches depending on their scale and budget constraints.
Cloud platforms offer significant advantages for training infrastructure including elastic scaling, access to specialized hardware like TPUs and high end GPUs, and managed services that reduce operational burden. AWS SageMaker, Google Vertex AI, and Azure Machine Learning provide integrated environments that handle provisioning, monitoring, and optimization of training jobs.
Distributed training becomes necessary when datasets or models exceed the capacity of a single machine. Data parallelism distributes training data across multiple workers while model parallelism splits large models across multiple devices. Frameworks like PyTorch Distributed, Horovod, and DeepSpeed provide the tools needed to implement these strategies effectively.
Cost Optimization Thesis
“Training costs can quickly spiral out of control without proper governance. Organizations should implement automated instance right sizing, spot instance utilization for fault tolerant workloads, and checkpoint strategies that enable training resumption. The goal is maximizing model quality per dollar spent rather than minimizing absolute training time.”
Model Validation, Testing, and Evaluation Frameworks
Rigorous validation ensures that models perform as expected before deployment to production. Unlike traditional software testing, machine learning validation must address unique challenges including data distribution shifts, overfitting to training data, and the probabilistic nature of predictions. A comprehensive evaluation framework examines model behavior across multiple dimensions beyond simple accuracy metrics.
Cross validation techniques help estimate how models will generalize to unseen data. K fold cross validation partitions training data into k subsets, training k models each validated on a different held out fold. Stratified sampling preserves class distributions across folds, while time series data requires temporal splits that respect chronological ordering to prevent information leakage.
Evaluation metrics should align with business objectives rather than defaulting to standard choices like accuracy. For imbalanced classification problems, metrics like precision, recall, F1 score, and area under the ROC curve provide more meaningful insights. Regression tasks might emphasize mean absolute error for interpretability or root mean squared error to penalize large deviations more heavily.
Validation Checklist for Production Readiness
Performance Validation:Model meets accuracy thresholds on holdout test set
Fairness Testing: Performance is consistent across demographic subgroups
Robustness Testing: Model handles edge cases and adversarial inputs gracefully
Latency Testing: Inference time meets real-time serving requirements
Integration Testing: Model integrates correctly with upstream and downstream systems
Shadow Testing: Model predictions compared against the current production system
Model Versioning and Experiment Tracking
Machine learning experimentation generates numerous model variants as data scientists iterate on features, algorithms, and hyperparameters. Without systematic tracking, this experimentation becomes chaotic and irreproducible. Model versioning and experiment tracking systems provide the infrastructure to manage this complexity, enabling teams to understand what worked, reproduce successful experiments, and roll back to previous versions when needed.
Effective experiment tracking captures the complete context of each training run, including code version, data snapshot, hyperparameter values, hardware configuration, and resulting metrics. This provenance information is essential for debugging production issues, satisfying audit requirements, and enabling reproducibility. Tools like MLflow, Weights and Biases, and Neptune.ai have become standard components in modern ML infrastructure.
Model registries complement experiment tracking by providing a curated catalog of production ready models. Unlike experiment databases that contain every training run, registries maintain only approved model versions along with metadata about their intended use, performance characteristics, and deployment status. This separation helps manage the transition from experimentation to production deployment.
Version control for machine learning extends beyond traditional code versioning to include data versioning and model artifact management. Tools like DVC (Data Version Control) enable git like workflows for large datasets and model files, integrating with existing development practices while handling the unique requirements of ML assets.
MLOps Pipelines and CI/CD for Machine Learning
MLOps applies DevOps principles to machine learning, creating automated pipelines that handle the complete lifecycle from code commit to production deployment. These pipelines reduce manual effort, enforce quality gates, and enable rapid iteration while maintaining reliability. The goal is to make model updates as routine and low risk as traditional software deployments.
Continuous Integration for machine learning validates not only code changes but also data quality and model performance. Automated tests verify that data pipelines produce expected outputs, that training completes successfully, and that model metrics meet defined thresholds. These checks run automatically on every code commit, catching issues before they reach production.
Continuous Deployment extends automation through staging and production environments with appropriate safeguards. Canary deployments route a small percentage of traffic to new model versions, monitoring for regressions before full rollout. Blue green deployments maintain two production environments, enabling instant rollback if issues emerge. These patterns reduce the risk of model updates while enabling frequent releases.
MLOps Maturity Model
Level 0: Manual
Ad hoc processes, notebook-driven experimentation, and manual deployment
Level 1: Automated Training
Automated training pipelines, basic versioning, and scheduled retraining
Level 2: CI/CD
Automated testing, continuous deployment, feature store integration
Level 3: Full MLOps
Automated retraining triggers, A/B testing, self-healing systems
Model Deployment Strategies: Batch, Real Time, Edge
Deployment strategy selection depends on use case requirements, including latency tolerance, prediction volume, and infrastructure constraints. The three primary patterns of batch, real time, and edge deployment each offer distinct advantages and impose different architectural requirements. Many production systems employ multiple strategies for different aspects of their AI functionality.
Deployment Strategy Comparison
| Strategy | Latency | Use Cases | Infrastructure |
|---|---|---|---|
| Batch Inference | Hours to days | Reports, bulk scoring, ETL | Spark, scheduled jobs |
| Real Time Serving | Milliseconds | API endpoints, user requests | Kubernetes, serverless |
| Edge Deployment | Sub millisecond | IoT, mobile, offline capable | TensorFlow Lite, ONNX |
| Streaming Inference | Seconds | Event processing, alerts | Kafka, Flink, Storm |
Batch inference remains the simplest deployment pattern, running models against large datasets on a scheduled basis. This approach suits use cases like nightly recommendation generation or monthly churn prediction where real time results are not required. Batch deployments leverage existing data processing infrastructure and avoid the complexity of maintaining always on serving systems.
Real time serving exposes models through APIs that return predictions within milliseconds. This pattern powers interactive applications including search ranking, fraud detection, and personalization. Real time serving requires careful attention to latency optimization, scaling strategies, and failure handling to maintain reliable service under varying loads.
Edge deployment pushes model inference to devices at the network edge including smartphones, IoT sensors, and embedded systems. This approach reduces latency, enables offline operation, and keeps sensitive data local. Model compression techniques like quantization and pruning reduce model size and compute requirements to fit constrained edge environments.
Serving Architecture and Inference Optimization
Serving architecture determines how models receive requests and return predictions in production. Well-designed serving infrastructure handles variable loads, maintains low latency, and supports multiple model versions simultaneously. The architecture must balance throughput, latency, cost, and operational complexity based on application requirements.
Containerized deployments using Docker and Kubernetes have become the standard approach for real-time serving. Containers package models with their dependencies, ensuring consistent behavior across environments. Kubernetes orchestration handles scaling, load balancing, and failure recovery automatically. Specialized model serving frameworks like TensorFlow Serving, TorchServe, and Triton Inference Server optimize inference performance and simplify deployment.
Inference optimization techniques reduce latency and compute costs in production. Model quantization reduces numerical precision from 32-bit floats to 8-bit integers, dramatically shrinking model size and accelerating inference with minimal accuracy loss. Knowledge distillation trains smaller student models to mimic larger teacher models, trading training compute for serving efficiency. Hardware acceleration using GPUs, TPUs, or specialized inference chips provides additional performance gains for compute-intensive models.
Caching strategies can significantly reduce serving costs for models with repetitive inputs. Request deduplication eliminates redundant inference calls, while prediction caching stores results for common inputs. These techniques work particularly well for recommendation systems and search applications where input patterns repeat frequently.
Monitoring, Drift Detection, and Performance Tracking
Production ML systems require continuous monitoring to detect degradation before it impacts business outcomes. Unlike traditional software, where bugs produce immediate errors, ML models can silently degrade as data distributions shift over time. Comprehensive monitoring tracks operational metrics like latency and throughput alongside ML-specific metrics, including prediction distributions and model accuracy.
Data drift occurs when production input distributions diverge from training data distributions. Concept drift happens when the relationship between inputs and outcomes changes, even if input distributions remain stable. Both forms of drift can degrade model performance and require different remediation strategies. Statistical tests and distribution comparison metrics help detect drift before it significantly impacts predictions.
Example: E-Commerce Recommendation Monitoring
A recommendation system serving product suggestions monitors multiple signal types:
Input Distribution: Product category distributions, user segment proportions, session lengths
Prediction Distribution: Recommendation diversity, confidence score distributions, null result rates
Business Metrics: Click-through rates, conversion rates, average order value
Operational Metrics: P99 latency, error rates, throughput per instance
Feedback Signals: Explicit ratings, implicit engagement, return rates
Automated alerting triggers notifications when metrics exceed defined thresholds. More sophisticated systems implement automated remediation including traffic rerouting to backup models or triggering retraining pipelines. The goal is to minimize the time between drift occurrence and response, reducing the window where degraded models impact users.
Security, Compliance, and Governance in AI Systems
AI systems introduce unique security and compliance challenges beyond traditional software applications. Models can leak sensitive training data through inference attacks, amplify biases present in historical data, and make decisions that require explanation for regulatory compliance. Governance frameworks must address these risks throughout the AI lifecycle from data collection through production operations. Centralized data warehousing services simplify governance, audit logging, and compliance by enforcing access controls, lineage tracking, and standardized schemas across AI data pipelines.
Data security encompasses both protecting training data from unauthorized access and ensuring that models do not memorize and reveal sensitive information. Techniques like differential privacy add noise during training to prevent individual record extraction, while federated learning enables model training on distributed data without centralizing sensitive information. Access controls and audit logging track who interacts with data and models throughout the lifecycle.
Explainability requirements vary by industry and application but are increasingly mandated by regulations like GDPR’s right to explanation. Interpretable models provide inherent transparency, while post hoc explanation techniques like SHAP and LIME can explain individual predictions from complex models. Model cards and datasheets document model behavior, limitations, and appropriate use cases for downstream consumers.
Bias detection and mitigation are essential for AI systems that impact human decisions around hiring, lending, healthcare, and other consequential domains. Statistical fairness metrics measure whether model outcomes differ across protected groups. Mitigation techniques include resampling training data, adjusting model predictions, or modifying optimization objectives to incorporate fairness constraints.
Building Reliable AI Systems Through Structured Data Annotation
Structured data annotation plays a critical role in building reliable AI systems by converting raw and unorganized datasets into labeled information that machine learning models can understand. Techniques such as image labeling, text tagging, and entity recognition provide the context needed for algorithms to learn patterns accurately. This structured approach improves model accuracy, consistency, and overall performance during real-world deployment.
For organizations developing AI solutions, working with a Top data annotation company ensures high-quality datasets and scalable annotation workflows. These companies follow strict quality control processes and standardized labeling practices, helping businesses train AI models that deliver dependable and efficient results.
Ultimately, structured data annotation acts as the bridge between data collection and AI deployment. By ensuring that training data is precise and well organized, it supports the development of AI systems that are reliable, scalable, and ready for production environments.
Scaling, Maintenance, and Continuous Improvement
Successful AI systems must scale to meet growing demand while maintaining performance and reliability. Scaling challenges differ between training and serving workloads. Training scaling focuses on reducing time to results through parallelization and efficient resource utilization. Serving scaling ensures consistent latency and availability as request volumes increase.
Horizontal scaling adds more serving instances behind load balancers to handle increased traffic. Auto scaling policies adjust instance counts based on CPU utilization, request queue depth, or custom metrics. Vertical scaling uses more powerful instances to handle larger models or reduce latency. The optimal scaling strategy depends on model characteristics and cost constraints.
Maintenance activities keep AI systems healthy over time. Regular retraining refreshes models with recent data, preventing staleness and drift. Dependency updates address security vulnerabilities in frameworks and libraries. Infrastructure updates take advantage of new hardware capabilities and platform improvements. Scheduled maintenance windows enable these updates with minimal service disruption.
Continuous improvement cycles systematically enhance model performance through experimentation. A/B testing compares new model versions against production baselines using real traffic. Online learning techniques update models incrementally as new data arrives. Feedback loops capture user responses to predictions, creating labeled data for future training iterations.
Ready to Build Enterprise Grade AI Systems?
Partner with experts who understand the complete AI architecture journey from data to deployment.
Conclusion: AI System Architecture
Building production AI systems requires far more than training accurate models. The architecture must support the complete lifecycle from data collection through deployment and continuous monitoring. Each component from ETL pipelines to feature stores to serving infrastructure must work together seamlessly while remaining flexible enough to accommodate rapid experimentation and evolving requirements.
Success depends on treating AI as an engineering discipline with rigorous practices around testing, versioning, monitoring, and governance. Organizations that invest in robust infrastructure and mature MLOps practices achieve faster iteration cycles, more reliable production systems, and better alignment between AI capabilities and business outcomes. The patterns and architectures described in this guide provide a roadmap for building AI systems that deliver lasting value.
Nadcab Labs brings over 8 years of deep expertise in architecting and implementing enterprise AI systems across diverse industries. Our team has successfully delivered hundreds of AI projects ranging from real time recommendation engines to large scale predictive analytics platforms. We understand the nuances of DAOs in DeFi Space, blockchain integration with AI systems, and the critical infrastructure decisions that determine project success or failure.
With proven methodologies refined through years of production deployments, Nadcab Labs provides end-to-end AI architecture services that transform raw data into business intelligence. Our expertise spans data engineering, feature store design, MLOps implementation, and enterprise-scale deployment strategies. When organizations need authoritative guidance on building AI systems that perform reliably at scale, they trust the experience and technical depth that only comes from years of focused practice in this specialized field.
Frequently Asked Questions
Q1.How much does it typically cost to build an enterprise AI system from scratch?
Enterprise AI system costs vary significantly based on complexity, scale, and infrastructure choices. Initial setup typically ranges from $100,000 to $500,000 for mid sized implementations, with ongoing operational costs of $20,000 to $100,000 monthly depending on compute requirements. Cloud-based approaches reduce upfront investment but may have higher long term costs at scale. Organizations should budget for data infrastructure, compute resources, specialized talent, and tooling licenses.
Q2.How long does it take to deploy an AI model into production for the first time?
First production deployment timelines typically range from 3 to 12 months, depending on organizational readiness and use case complexity. Organizations with mature data infrastructure can achieve faster deployments, while those building foundational capabilities may require longer. The bulk of time often goes into data preparation and infrastructure setup rather than model training. Subsequent model deployments become significantly faster once MLOps pipelines are established.
Q3.What team size and roles are needed to maintain an AI system in production?
A minimum viable AI team typically includes 2 to 3 data engineers for pipeline maintenance, 1 to 2 ML engineers for model optimization, and 1 platform engineer for infrastructure. Larger organizations add dedicated roles for data science research, MLOps, security, and product management. Many organizations start with smaller teams wearing multiple hats and expand as systems mature. Cross-functional collaboration between data, engineering, and business teams is essential regardless of team size.
Q4.Can existing legacy systems integrate with modern AI architecture?
Legacy system integration is common and achievable through various patterns. API gateways can expose AI predictions to legacy applications without major changes. Batch processing allows AI outputs to flow into existing databases and reports. Event streaming architectures enable gradual modernization alongside legacy systems. The key is designing clear interfaces that allow AI components to evolve independently while maintaining compatibility with existing business processes.
Q5.How often should production AI models be retrained?
Retraining frequency depends on how quickly data patterns change in your domain. Financial fraud models might require weekly updates due to evolving attack patterns, while customer segmentation models might remain stable for months. The best approach is monitoring for drift and triggering retraining when performance degrades rather than following fixed schedules. Many organizations implement automated retraining pipelines that respond to drift detection alerts.
Q6.What happens when an AI model fails in production?
Production failures require graceful degradation strategies defined during architecture design. Common approaches include falling back to simpler rule-based systems, returning cached predictions for known inputs, or serving predictions from a previous stable model version. Circuit breakers prevent cascade failures by isolating problematic components. Incident response procedures should include rollback capabilities, root cause analysis processes, and communication protocols for affected stakeholders.
Q7.Is cloud or on premises deployment better for AI systems?
The choice depends on regulatory requirements, cost structure, and technical capabilities. Cloud deployment offers faster time to market, elastic scaling, and access to managed services. On premises deployment provides greater control, potentially lower costs at scale, and compliance with data residency requirements. Many organizations adopt hybrid approaches where training happens in the cloud for flexibility while serving occurs on premises for latency or compliance reasons.
Q8.How do you handle sensitive data in AI training without privacy violations?
Privacy-preserving techniques include data anonymization that removes personally identifiable information, synthetic data generation that creates realistic but non-sensitive training data, differential privacy that adds mathematical guarantees against individual identification, and federated learning that trains models on distributed data without centralization. The appropriate technique depends on regulatory requirements, data sensitivity, and model performance requirements.
Q9.What is the difference between MLOps and traditional DevOps?
MLOps extends DevOps practices to handle the unique challenges of machine learning systems. Key differences include versioning data and models alongside code, testing for statistical properties beyond functional correctness, monitoring for model drift rather than just system health, and managing experimentation workflows that produce many model variants. MLOps also addresses reproducibility challenges arising from stochastic training processes and handles the continuous retraining cycles that ML systems require.
Q10.How do you measure the ROI of an AI system implementation?
AI ROI measurement should connect model metrics to business outcomes. Start by establishing baseline performance for the process being automated or augmented. Track direct impacts like revenue increases, cost reductions, and efficiency gains. Include indirect benefits such as faster decision-making, improved customer experience, and reduced risk exposure. Compare the total cost of ownership, including infrastructure, talent, and maintenance, against measured benefits. Many organizations find that AI value accrues over time as systems improve and adoption expands.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.