Ai Overview
Most AI initiatives fail in production not because the model is “wrong”, but because the surrounding system responsibilities (data, pipelines, deployment, monitoring, governance) are incomplete. Most conversations about AI begin and end with models—accuracy metrics, architectures, parameters, and benchmarks. This narrow focus is a primary reason AI initiatives fail once they leave experimentation and hit real environments.
AI System Components Explained: Core Building Blocks of Modern AI Systems
Most AI initiatives fail in production not because the model is “wrong”, but because the surrounding
system responsibilities (data, pipelines, deployment, monitoring, governance) are incomplete.
Production AI is a distributed system; the model is one replaceable component.
Bad capture and noisy signals silently cap performance.
Latency, reliability, and schema stability are determined before modeling.
Without drift and health monitoring, systems degrade quietly.
1) Why AI Systems Fail When People Think Only About Models
Most conversations about AI begin and end with models—accuracy metrics, architectures, parameters, and benchmarks.
This narrow focus is a primary reason AI initiatives fail once they leave experimentation and hit real environments.
In production, an AI system is not a trained model that outputs predictions. It is a data-driven system that must
ingest signals from the real world, transform them into structured representations, make decisions under uncertainty,
adapt as conditions change, and remain stable despite failures.
Failures rarely originate from weak algorithms. They originate from missing pipelines, brittle infrastructure,
uncontrolled data drift, absent monitoring, and the inability to respond when reality diverges from assumptions.
or roll back safely, it isn’t production AI it’s a proto type.[1]
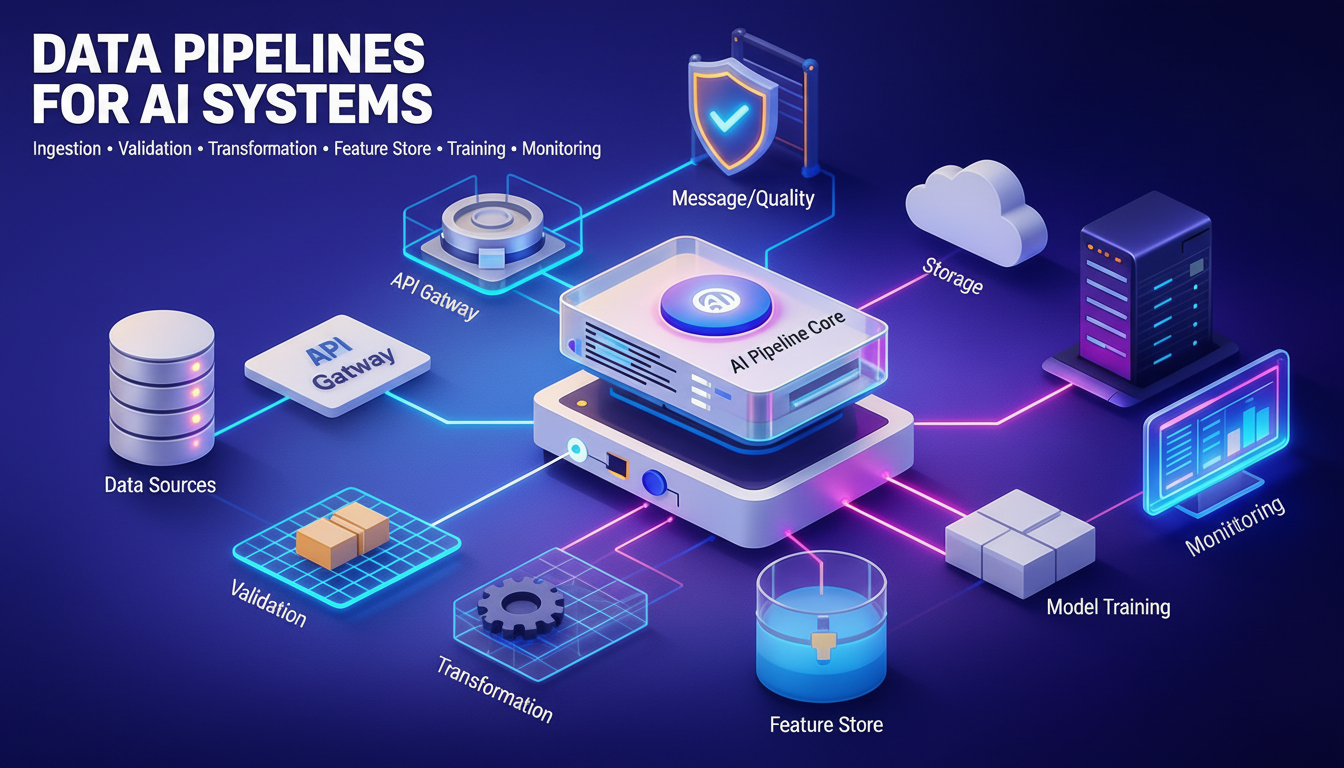
2) The High-Level Anatomy of an AI System
Every functioning AI system—across industries and scales—converges on a common structural anatomy. Implementations differ,
but the core building blocks remain consistent because they represent system responsibilities, not design preferences.
| Component | Primary role | Key risk / failure mode |
|---|---|---|
| Data sources | Generate real-world signals (users, logs, sensors, transactions) that define what the system can learn. | Noise, bias, missingness, and non-stationary data cap model performance. |
| Ingestion & pipelines | Collect, validate, transform, and route data reliably (batch + streaming), handling failures automatically. | Schema drift, silent drops, and retry storms corrupt training and inference inputs. |
| Storage & management | Preserve raw + processed data, labels, metadata, and artifacts with versioning, access control, and retention. | No versioning breaks reproducibility; weak controls leak sensitive data; poor retention inflates cost. |
| Model layer | Learn patterns and generate outputs (predictive, generative, classification, anomaly detection). | Models don’t validate inputs, manage drift, enforce safety, or understand business consequences. |
| Training & evaluation | Run repeatable experiments with tracking, stable evaluation sets, and well-defined metrics. | Proxy metrics, leakage, and weak evaluation create “improvements” that fail in production. |
| Deployment & inference | Serve predictions at required speed and scale via APIs, batch jobs, or event-driven inference. | Unbounded inference costs, latency spikes, and brittle serving cause downtime and poor UX. |
| Monitoring & feedback | Track drift, bias signals, accuracy changes, latency, error rates; enable correction and retraining. | Without monitoring, systems degrade silently (“rot”) until trust and KPIs collapse. |
| Governance & control | Approvals, permissions, rollbacks, kill switches, and audit trails to bound risk. | Without controls, failures are hard to reverse and decisions are hard to explain. |
3) Data Sources: The True Foundation of Intelligence
AI systems learn from data generated by real users, machines, and environments. These sources may include user interactions,
transactional records, sensors, logs, multimedia content, and external datasets.
Real-world data is typically noisy, incomplete, biased, and non-stationary so AI model performance is capped by input quality.
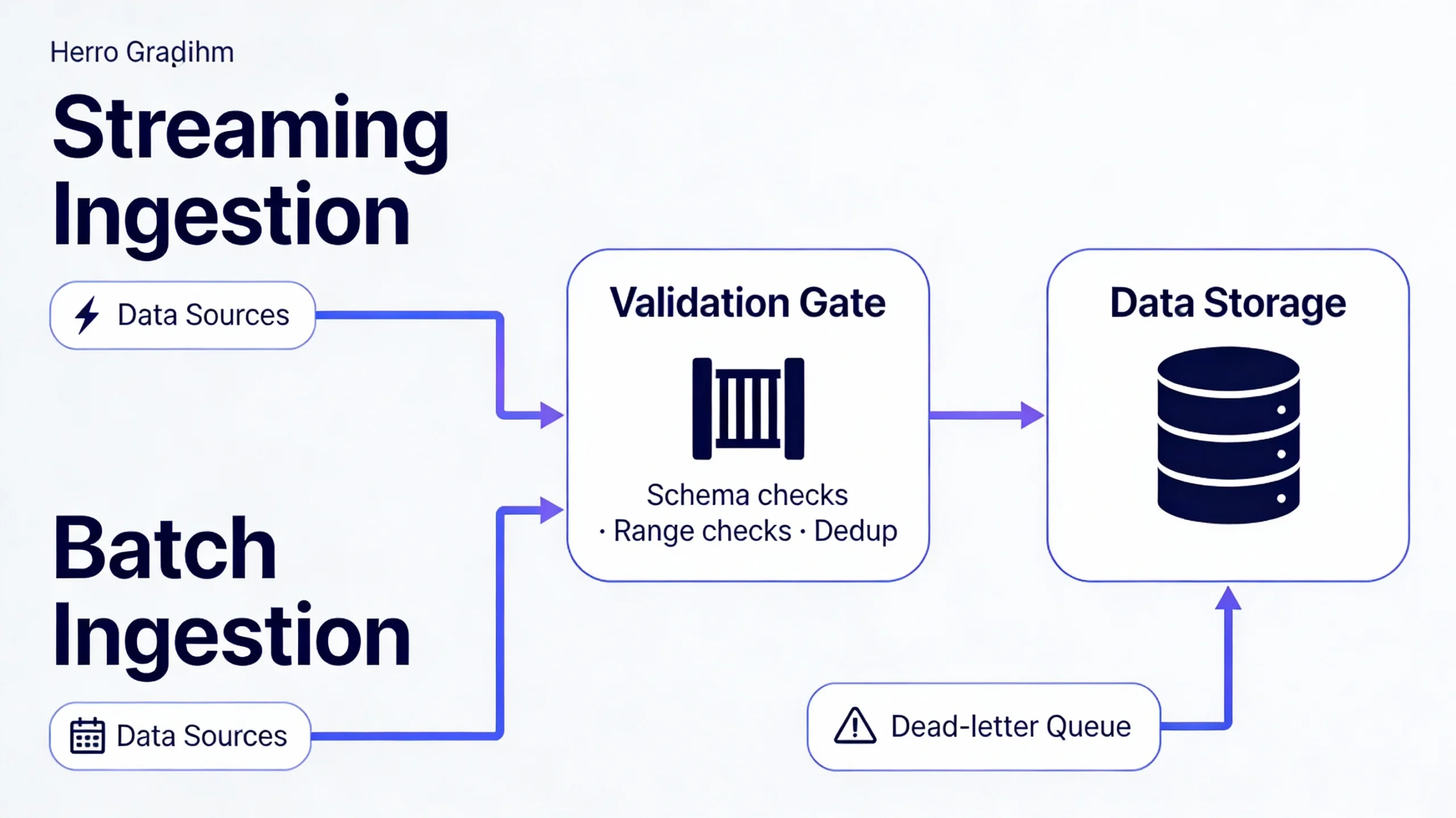
4) Data Ingestion & Pipelines: Moving Reality Into the System
Raw data has no value until it is reliably moved into the system in a usable form. The ingestion layer is responsible for
collecting signals, validating structure, transforming formats, routing events, and handling failure without constant human intervention.
5) Data Storage & Management: Where Intelligence Accumulates
AI systems accumulate intelligence across multiple forms of storage: raw data, processed features, historical datasets,
metadata/labels, and model artifacts. This layer must support versioning, access control, retention policies, and auditability.
6) Model Layer: The Decision Engine (Not the System)
The model layer learns patterns and generates outputs, but it does not own data, validate inputs, manage drift,
monitor performance, enforce safety, or understand business context. Treating the model as the system is the most common AI architectural error.
7) Training & Evaluation Infrastructure: Where Learning Happens
Training is not a one-time event. It is a controlled experiment conducted repeatedly under varying conditions.
Training infrastructure exists to make learning reproducible, comparable, and safe—using experiment tracking, evaluation datasets,
and well-defined performance metrics.
8) Deployment & Inference Layer: AI in the Real World
A trained model has no practical value until it is deployed into an environment where it can produce decisions at the required
speed, scale, and reliability. The deployment layer handles serving, APIs, latency constraints, scalability, access control, and cost management.
9) Monitoring & Feedback Loop: Where AI Becomes a System
Monitoring and feedback transform isolated predictions into a living system by observing real-world behaviour and enabling corrective action.
Monitoring includes drift, data distribution changes, latency/error rates, bias emergence, and unexpected behaviours.
| Stage | What happens | What to watch |
|---|---|---|
| Signal generation | Users/systems produce events, logs, transactions, and feedback. | Coverage gaps, bias, missing fields, shifting behaviour. |
| Ingestion | Events arrive via stream/batch, validated and routed into storage. | Schema changes, lag, duplicates, silent drops. |
| Storage | Raw + curated datasets are preserved and versioned for training and audits. | Lineage, access control, retention cost, reproducibility. |
| Training & eval | Models are trained repeatedly and compared with stable evaluation discipline. | Leakage, metric misalignment, regressions. |
| Deployment | Models are served to applications under latency and reliability constraints. | Latency, errors, scalability, cost per prediction. |
| Monitoring | Production behaviour is observed; drift and failures are detected. | Data drift, accuracy drift, bias, anomalies. |
| Feedback loop | Labels/feedback drive retraining, data fixes, and process improvements. | Label quality, retrain cadence, safe rollout/rollback. |
10) Control & Governance Layer (Often Invisible, Always Necessary)
AI systems operate under uncertainty and risk. Governance mechanisms (approvals, permissions, rollbacks, kill switches, and audit trails)
manage that risk deliberately rather than reactively.
- Model approval workflow
- Access permissions
- Rollback strategy
- Kill switch / feature flag
- Audit trails
- Risky changes reach users silently
- Incidents become hard to reverse
- Decisions become hard to explain
- Trust erodes after failures
11) Risks Tied to Each AI System Component
| Component | Risk | Typical symptom | Mitigation |
|---|---|---|---|
| Data sources | Bias, incompleteness | Unfair outcomes, blind spots, weak generalization | Improve instrumentation, audit capture, validate distributions |
| Ingestion | Loss & latency | Stale decisions, missing records, broken training sets | Schema contracts, validation, idempotent retries, backpressure |
| Storage | Inconsistency & leakage | Can’t reproduce results; sensitive data exposure | Versioning, access control, encryption, audit trails |
| Model layer | Brittleness | Performance drops on new regimes / edge cases | Robust evaluation, calibration, fallbacks |
| Training | Misleading metrics | Offline gains but production harm | Metric discipline, regression checks, online validation |
| Deployment | Cost spikes & downtime | Latency regressions, outages, runaway inference bills | Autoscaling, quotas, caching, safe rollouts/rollbacks |
| Monitoring | Silent degradation | KPIs decline slowly; trust erodes before alarms | Drift detectors, dashboards, alerts, human-in-loop review |
12) Decision Checklist: Are You Designing a Real AI System?
Before shipping:
- Data sources are understood and controlled.
- Pipelines are resilient and observable (no silent drops).
- Storage is versioned and auditable.
- Training is reproducible with evaluation discipline.
- Inference cost is predictable and bounded.
- Monitoring detects drift, bias, and latency regressions.
- The system can be rolled back or shut down safely.
Frequently Asked Questions
Q1.Are models the most important part of AI systems?
No. Data quality and monitoring matter more over time.
Q2.Can AI systems work without feedback loops?
They can, but they degrade quickly.
Q3.Is AI infrastructure expensive?
Poorly designed infrastructure is expensive; disciplined systems are controllable.
Q4.Do small teams need full AI systems?
Yes, scaled appropriately to scope and risk.
Q5.Can AI systems be fully automated?
Not safely. Human oversight remains essential.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.