Ai Overview
Most people who talk about building with generative AI tech stack platforms are actually describing just one piece of a much larger system. Budget matters enormously because token costs scale linearly with usage, making an expensive model unaffordable at high volume. GPT-4 training reportedly cost over $100 million. Llama 3 was trained on 24,000 NVIDIA H100 GPUs.
Key Takeaways
10 core insights about the generative AI tech stack for engineering teams
- 01
A generative AI tech stack is not a single tool. It is a layered system spanning data, models, infrastructure, orchestration, and monitoring that must work together seamlessly in production. - 02
Foundation model selection is the most consequential decision in any generative AI tech stack, affecting cost, latency, quality, and compliance for every subsequent component built on top. - 03
Vector databases like Pinecone, Weaviate, and pgvector have become essential generative AI tools and frameworks for building context-aware applications using retrieval augmented generation at enterprise scale. - 04
In India and the UAE, most enterprise teams build their AI tech stack on cloud-native infrastructure using AWS, Azure, or GCP as the base, with managed services for model hosting reducing operational complexity significantly. - 05
Fine-tuning a foundation model on domain-specific data can improve task accuracy by 30 to 60 percent compared to prompt engineering alone, making it essential for specialised enterprise use cases. - 06
Prompt engineering is a practical engineering discipline within the generative AI tech stack, not just writing instructions. Well-designed prompt templates reduce hallucination rates and improve output consistency significantly. - 07
Monitoring and observability in generative AI platforms requires tracking model quality metrics like hallucination rate, latency, and relevance scores, not just infrastructure metrics like CPU and memory utilisation. - 08
Security in the generative AI tech stack includes prompt injection defence, output filtering, PII detection in training data, API rate limiting, and compliance alignment with India’s DPDP Act and UAE’s data governance frameworks. - 09
Orchestration frameworks like LangChain, LlamaIndex, and DSPy have become the connective tissue of modern generative AI infrastructure, linking models, tools, memory, and data sources in complex multi-step workflows. - 10
Scaling a generative AI pipeline requires horizontal scaling of inference endpoints, caching strategies, load balancing, and asynchronous request handling to manage cost and latency at production traffic volumes.
What an End to End Generative AI Pipeline Actually Looks Like
Most people who talk about building with generative AI tech stack platforms are actually describing just one piece of a much larger system. When you see ChatGPT answer a question or see an AI tool generate a contract summary, what you are seeing is the final output of a pipeline that involves dozens of interconnected components working in sequence. Understanding the full pipeline is the starting point for any serious generative AI tech stack conversation.
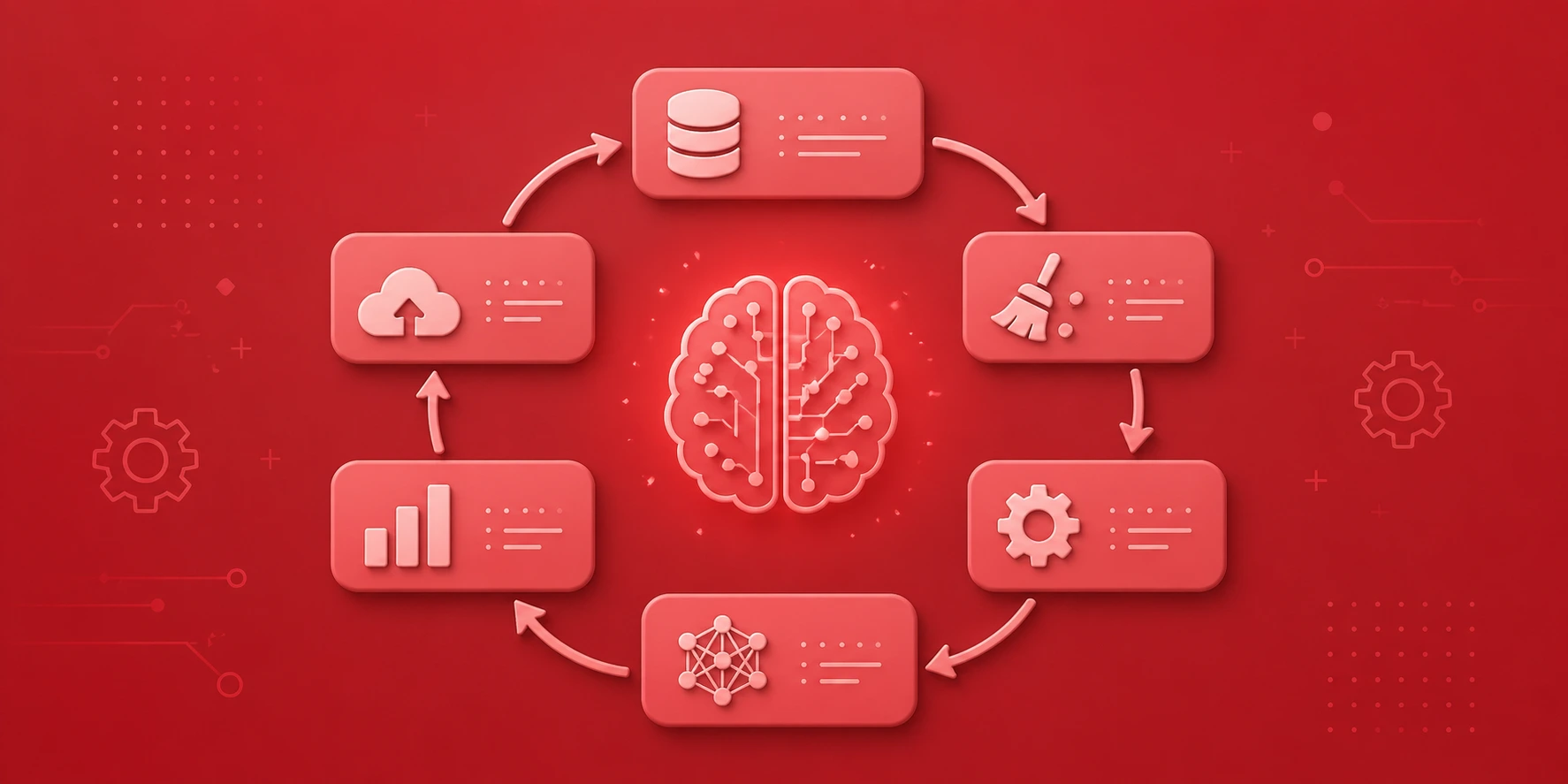
An end-to-end generative AI pipeline starts with raw data, processes and stores it in a form models can use, retrieves relevant context when a user makes a request, passes that context and request through a foundation model, filters and formats the output, and then returns it to the user. Each of those steps involves specific tools, infrastructure decisions, and engineering trade-offs.
For teams in India building enterprise SaaS products and teams in Dubai building client-facing AI services, understanding the full pipeline before writing the first line of code prevents the most common and expensive architectural mistakes that surface six months into a project.
Breaking Down the Core Layers of a Generative AI Tech Stack
A complete generative AI tech stack has six core layers. Each layer depends on the one below it. Choosing well at each layer gives you flexibility and performance. Choosing poorly creates technical debt that multiplies as the system grows in complexity and scale.
How Data Flows Through a Generative AI Pipeline
Data movement through a generative AI tech stack infrastructure guide follows two distinct paths: the indexing path that runs before users ever interact with the system, and the query path that runs in real time when a user makes a request. Understanding both paths is essential for designing a system that is both accurate and fast.
During the indexing path, raw documents are loaded, split into chunks, converted into numerical embeddings, and stored in a vector database alongside their original text. This happens offline or on a schedule, not during a live user request. The quality of this step determines how much relevant context the system can retrieve when it matters.
Indexing Path (Offline)
- Load raw documents and data
- Clean and normalise content
- Split into semantic chunks
- Generate vector embeddings
- Store in vector database
- Index metadata for filtering
Query Path (Real Time)
- Receive user input
- Embed query into vector space
- Retrieve relevant context chunks
- Build structured prompt
- Call foundation model API
- Filter and return response
Feedback and Learning Loop
- Collect user feedback signals
- Log model inputs and outputs
- Evaluate response quality
- Update prompts and configs
- Re-index updated documents
- Trigger fine-tuning if needed
Choosing the Right Foundation Models for Your Use Case
The foundation model is the heart of the generative AI tech stack. It is the component that generates outputs and determines the ceiling of what your application can do. Choosing the wrong foundation model is one of the most expensive mistakes an engineering team can make because it affects every downstream component and is difficult to swap without significant rework later.
For teams in India and Dubai, the decision involves several dimensions that go beyond raw capability benchmarks. Data residency requirements under India’s DPDP Act and UAE federal data laws may require on-premise or region-specific hosting, which rules out some hosted API models. Budget matters enormously because token costs scale linearly with usage, making an expensive model unaffordable at high volume.
Foundation Model Comparison for Enterprise Generative AI Tech Stack
| Model | Best For | Hosting | Cost Tier |
|---|---|---|---|
| GPT-4o | Complex reasoning, code, multimodal | API / Azure | High |
| Claude 3.7 | Long documents, legal, structured output | API / AWS Bedrock | High |
| Gemini 2.0 | Search, Google Workspace integration | API / GCP | Medium-High |
| Llama 3.3 | On-premise, privacy, fine-tuning | Self-hosted | Low (infra cost) |
| Mistral Large | European/India data compliance | API / Self-hosted | Medium |
How Fine Tuning Improves Performance
Fine-tuning is the process of continuing to train a pre-trained foundation model on your own specific dataset so it learns the patterns, terminology, and style of your particular domain. In the context of a generative AI development stack, fine-tuning sits between the base model selection and the inference layer.
An Indian legal tech startup that fine-tunes Llama 3 on Indian case law and legal documents will produce dramatically better outputs for legal research queries than using the base model with prompt engineering alone. A Dubai-based financial services firm that fine-tunes on their internal product documents will see better accuracy on product-specific customer queries. The accuracy gains of 30 to 60 percent justify the compute cost in most enterprise use cases.
When Fine Tuning Makes Sense
Use fine-tuning when prompt engineering has reached its ceiling, when your domain has specialised vocabulary, or when you need consistent output formatting that prompts alone cannot reliably produce.
Why Vector Databases Power Modern AI Apps
Embeddings are the numerical representations of text that allow AI systems to find semantically similar content even when the exact words do not match. If a user asks about “invoice payment delays” and your documents discuss “accounts receivable latency,” a vector database finds the relevant content because the meanings are similar in the embedding space, even though the words are different.
Popular vector databases in the generative AI tech stack include Pinecone for managed cloud deployment, Weaviate for hybrid search capabilities, Qdrant for on-premise requirements, and pgvector for teams already using PostgreSQL. Indian enterprises with data localisation requirements often prefer pgvector because it sits inside their existing database infrastructure.
Retrieval Augmented Generation (RAG)
RAG combines vector retrieval with generation to give models access to your private knowledge base without training. It is the most commonly used pattern in enterprise generative AI platforms today.
How Prompt Engineering Fits Into the Tech Stack
Prompt engineering has evolved from a curiosity to a serious engineering discipline within the generative AI tech stack infrastructure guide. It sits at the interface between your application logic and the foundation model, determining how queries and context are structured before being sent to the model. The quality of this layer directly determines output quality, consistency, and cost.
Well-engineered prompt templates specify output format, persona, constraints, and context injection points. They reduce hallucination by instructing the model to use only provided context. They control output length to manage cost. They handle multilingual requirements by specifying language at the prompt level, which is particularly important for Indian language applications serving Hindi, Tamil, or Telugu users alongside English.
Prompt Engineering Impact on Output Quality
Infrastructure Needed to Train Generative Models
Training foundation models from scratch requires infrastructure that only the largest companies in the world can afford. Llama 3 was trained on 24,000 NVIDIA H100 GPUs. GPT-4 training reportedly cost over $100 million. For the vast majority of teams building generative AI platforms, training from scratch is not in scope and not necessary.
Fine-tuning, however, is accessible. Fine-tuning Llama 3 on a custom dataset requires 2 to 8 A100 GPUs for a few hours, available through AWS, Azure, or GCP at manageable costs. Indian enterprises use platforms like AWS SageMaker, and Dubai-based teams commonly use Azure AI services for managed fine-tuning without managing GPU infrastructure directly.
How Generative AI Models Are Deployed in Production
Model serving in production is a distinct engineering challenge from training or fine-tuning. A model that performs well in testing can fail in production due to latency under concurrent load, memory limitations at scale, and cold start delays when containers need to be spun up on demand. The generative AI tech stack needs proper serving infrastructure to handle real traffic.
Common serving approaches include managed endpoints on AWS SageMaker, Azure ML, or GCP Vertex AI for hosted models; vLLM for high-throughput self-hosted open source model serving; Ollama for lightweight local deployment; and TensorRT-LLM for GPU-optimised inference at scale. The choice depends on latency requirements, cost sensitivity, and data sovereignty constraints.
How to Measure and Monitor Generative AI Systems Effectively
Monitoring a generative AI tech stack is fundamentally different from monitoring traditional software. Standard infrastructure metrics like CPU usage, memory, and request latency are still important, but they tell you nothing about whether the AI is actually doing what it should be doing. You need a separate layer of AI-specific observability that measures output quality at runtime.
Key metrics for generative AI tech stack observability include hallucination rate, measured by checking whether outputs cite content that exists in the retrieved context. Relevance score measures whether retrieved chunks actually relate to the query. Faithfulness measures whether the generated answer is supported by the provided context. These metrics require LLM-as-a-judge evaluation frameworks like Ragas, TruLens, or custom evaluation pipelines.
What Security and Compliance Mean for Generative AI Systems
Security in the generative AI tech stack is not optional and cannot be bolted on after the fact. For teams in India operating under the DPDP Act and teams in Dubai operating under UAE federal data protection laws, compliance requirements shape architectural decisions from the first day of building. Here are the six standards every enterprise AI system must meet.
Implement prompt injection defences that detect and block attempts by malicious user inputs to override system instructions or extract sensitive information from the model’s context window.
Apply output filtering on all model responses to detect and remove personally identifiable information, harmful content, and confidential data before returning outputs to users or external systems.
Store API keys and model credentials in secret management services like AWS Secrets Manager or Azure Key Vault. Never hardcode credentials in application code or include them in environment variable files committed to repositories.
For Indian enterprises, verify that training data and user query logs comply with the DPDP Act requirements for data localisation and consent. Do not send Indian citizen personal data to foreign-hosted model APIs without appropriate safeguards.
Implement rate limiting and access controls at the API gateway level to prevent abuse, reduce cost from runaway automation, and protect against denial-of-service attempts targeting inference endpoints.
Maintain comprehensive audit logs of all model inputs and outputs with timestamps and user identifiers. Logs enable debugging, quality improvement, regulatory compliance demonstration, and incident investigation when AI outputs cause issues.
How to Scale Generative AI Pipelines Without Breaking Systems
Scaling a generative AI tech stack infrastructure from dozens of daily requests to millions is not just a matter of provisioning more servers. Each layer of the stack has different scaling characteristics and failure modes that must be addressed before traffic grows to the point where problems become critical for real users.
The most common scaling bottleneck in production generative AI systems is the inference layer. Foundation model API calls are expensive, slow compared to traditional API calls, and subject to rate limits. Teams that do not design for caching, async processing, and request queuing early find themselves rewriting significant parts of their architecture when traffic spikes. This is especially relevant for Indian SaaS products that experience sudden growth after product launches or media coverage.
Ready to Build Your Generative AI Architecture from Models to Deployment?
Turn your AI ideas into scalable, production-ready systems. From selecting the right models to seamless deployment, we help you build efficient generative AI architectures tailored to your business needs.
People Also Ask
Q1.What is a generative AI tech stack and why does it matter for my business?
A generative AI tech stack is the full combination of models, tools, data pipelines, APIs, and infrastructure that work together to build and run AI-powered applications. It matters because choosing the right stack directly impacts your product speed, cost, and scalability.
Q2.What are the key components of a generative AI tech stack?
The core components include foundation models (like LLMs), embedding layers, vector databases, orchestration frameworks, prompt management systems, inference servers, monitoring tools, and cloud or on-premise infrastructure. Each layer has a specific role in making your AI application work reliably.
Q3.Which tools and frameworks are most commonly used in a generative AI tech stack?
Popular generative AI tech stack tools and frameworks include LangChain, LlamaIndex, Hugging Face Transformers, OpenAI APIs, Pinecone, Weaviate, and Ray Serve. The right combination depends on your use case, team size, and budget constraints.
Q4.How is the generative AI tech stack different from traditional machine learning infrastructure?
Traditional ML stacks focus on structured data, tabular models, and batch predictions. Generative AI infrastructure guide principles, on the other hand, handle unstructured inputs like text, images, and audio in real time, requiring entirely different tooling for embeddings, retrieval, and generation.
Q5.What does a generative AI development stack look like for a startup in India or UAE?
For startups in India or Dubai, a practical generative AI development stack typically starts with cloud APIs from OpenAI or Anthropic, vector stores like Chroma or Pinecone, and lightweight orchestration via LangChain, keeping initial costs low while allowing future scaling.
Q6.How do I choose the right foundation model for my generative AI tech stack?
You should evaluate models based on your task type (text, code, image, multimodal), latency requirements, cost per token, fine-tuning support, and data privacy needs. Open-source models like Mistral or LLaMA may suit privacy-sensitive deployments in regulated markets.
Q7.What is prompt engineering and how does it fit into the AI tech stack?
Prompt engineering is the practice of designing, testing, and optimizing the instructions sent to generative AI tech stack models. It sits between your application logic and the foundation model layer, and plays a huge role in output quality without requiring any model retraining.
Q8.How do vector databases power generative AI platforms?
Vector databases store numerical representations (embeddings) of your content, allowing generative AI tech stack systems to retrieve the most relevant information at query time. This is the foundation of Retrieval-Augmented Generation (RAG), which dramatically improves generative AI tech stack accuracy on domain-specific questions.
Q9.How can companies in Dubai or India ensure security and compliance in their generative AI stack?
Organizations in regulated environments should enforce data residency policies, use private model deployments, implement role-based access controls, audit model inputs and outputs, and follow guidelines from bodies like DPDP (India) and UAE’s TDRA for AI governance.
Q10.How do generative AI pipelines scale as usage grows?
Scaling requires load balancing across inference nodes, caching repeated queries, autoscaling cloud instances, optimizing model serving with quantization, and implementing rate limiting. A well-designed generative AI tech stack infrastructure guide from day one saves significant cost and engineering effort later.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.