Ai Overview
AI practitioners obsess over model architectures, hyperparameters, and training techniques. Yet production AI failures trace back to data pipeline issues 60-80% of the time. Batch ingestion remains simplest and most cost-effective for training data. Versioning strategies must balance completeness against cost.
Key Takeaways
- Data pipeline failures cause 60-80% of production AI issues, not model architecture problems—invest in pipeline reliability first.
- Never mutate raw source data; immutable preservation enables reprocessing when bugs emerge, saving $100K-$500K in recovery costs.
- Schema validation at ingestion prevents 50-60% of quality issues—uncontrolled schema evolution silently corrupts models over weeks.
- Streaming infrastructure costs $3K-$10K/month vs $500-$2K/month for batch—hybrid architectures serve 70% of production systems.
- Version seven artifacts for reproducibility: raw data, cleaning logic, cleaned data, features, training sets, labels, and metadata.
- Labels drift faster than features as annotator understanding evolves—version labeling instructions alongside labels to detect systematic shifts.
- Organizations with 24-hour drift detection maintain 95%+ accuracy; manual monthly checks operate at 70-80% of potential performance.
- Six anti-patterns destroy maintainability: monolithic pipelines, undocumented transforms, manual steps, config sprawl, missing validation, and premature optimization.
- Pipelines outlive models by years—architectural discipline (abstraction layers, versioned interfaces, comprehensive testing) prevents $300K-$1M rewrites every 18-24 months.
- The path to AI maturity runs through data pipeline excellence, not model sophistication—master reliability, quality, and monitoring to build systems that scale.
1. Why Data Pipelines Matter More Than Models in AI Systems
AI practitioners obsess over model architectures, hyperparameters, and training techniques. Yet production AI failures trace back to data pipeline issues 60-80% of the time. The model receives corrupted inputs, training data diverges from production distributions, or labels contain systematic errors. By the time engineers notice degraded performance, the root cause lies weeks upstream in data collection.
Data pipelines determine the ceiling of model performance. A brilliant model trained on biased, incomplete, or stale data delivers unreliable predictions. Conversely, mediocre models trained on high-quality, representative data often outperform sophisticated architectures in production. The economics reinforce this reality—organizations spend 10x more engineering time maintaining data pipelines than tuning models.[1]
Real-World Impact: A retail recommendation system showed a 15% degradation in accuracy over three months. Investigation revealed the issue wasn’t model drift—product catalog updates introduced null values in critical features. The data pipeline lacked validation checks. By the time engineers detected the problem, 12 weeks of training data contained corrupted records. Complete pipeline rebuild required 6 weeks and $200K in engineering costs.
The implication is clear: data pipeline architecture deserves equal—if not greater—investment than model development. Teams that master data foundations build AI systems that scale, adapt, and maintain quality over years. Those that neglect pipelines spend resources firefighting production incidents instead of advancing capabilities.
2. Defining “Data” in AI: Beyond Tables and Files
Traditional software consumes structured data from databases and files. AI systems require far broader input types. The definition of “data” must encompass events, unstructured documents, temporal signals, user feedback, and derived artifacts from other models.
| Data Type | Characteristics | Pipeline Requirements | Storage Format |
|---|---|---|---|
| Structured Records | Fixed schema, tabular, transactional | SQL extraction, CDC streams | Parquet, Delta Lake |
| Event Streams | Temporal, high volume, ordered | Message queues, windowing | Time-series DBs, Kafka |
| Documents | Unstructured text, PDFs, HTML | Parsing, OCR, chunking | Object storage, vector DBs |
| Sensor Signals | Continuous, noisy, multi-modal | Filtering, resampling, compression | Binary formats, HDF5 |
| Human Feedback | Sparse, subjective, evolving | Aggregation, conflict resolution | Relational, labeled datasets |
| Derived Artifacts | Model outputs, embeddings | Version tracking, provenance | NumPy arrays, vector stores |
Each data type demands specialized pipeline architecture. Event streams require real-time processing infrastructure. Documents need parsing and semantic extraction. Sensor data necessitates signal processing before consumption. Architectures that treat all data uniformly introduce brittleness and inefficiency.
3. Data Source Taxonomy for AI Workloads
Production AI systems aggregate data from diverse sources, each introducing unique architectural challenges. Understanding source characteristics informs pipeline design decisions.
Transactional Systems
Operational databases (PostgreSQL, MySQL, Oracle) contain business-critical records. Direct querying risks overloading production systems. Change Data Capture (CDC) streams modifications in near real-time without impacting application performance. Tools like Debezium, Maxwell, and vendor-specific solutions capture database transaction logs and publish changes to message queues.
Application Logs and Events
User interactions, API calls, and system events generate massive log volumes. Structured logging (JSON, protocol buffers) enables automated parsing. Unstructured logs require regex extraction or ML-based parsing, introducing fragility. Log aggregation systems (Fluentd, Logstash) centralize collection before downstream processing.
Third-Party APIs
External data sources (weather services, financial feeds, social media) introduce dependencies and rate limits. Pipeline design must handle API failures gracefully, cache responses appropriately, and respect usage quotas. Costs scale with request volume, making caching essential for economic viability.
4. Architectural Patterns for Data Collection at Scale
| Pattern | Latency Profile | Throughput | Best Use Cases | Infrastructure Cost |
|---|---|---|---|---|
| Batch Ingestion | Hours to days | Very high (TB/hour) | Training data, historical analysis | Low – scheduled jobs |
| Streaming Ingestion | Milliseconds to seconds | Moderate (GB/hour) | Real-time features, monitoring | High – always-on clusters |
| Micro-Batch | 1-15 minutes | High (hundreds GB/hour) | Near real-time without full streaming | Medium – periodic scaling |
| Change Data Capture | Sub-second | Moderate (depends on DB activity) | Database replication, event sourcing | Medium – CDC tooling + queues |
| Hybrid Pipeline | Mixed (minutes to hours) | Very high combined | Production ML with both batch and streaming needs | Medium – optimized allocation |
Pattern selection trades latency against operational complexity. Batch ingestion remains simplest and most cost-effective for training data. Streaming becomes necessary when features require real-time signals or when monitoring needs immediate visibility. Most production systems adopt hybrid approaches—batch for training data collection, streaming for production feature serving.
5. Ingestion Reliability: Preventing Data Loss and Duplication
Data loss and duplication represent the two failure modes that silently corrupt AI systems. Loss removes training examples or production features, introducing bias. Duplication artificially inflates data volume and can cause models to overfit to repeated examples.

Idempotency Guarantees
Idempotent operations produce identical results when executed multiple times. Pipeline components must tolerate retries without creating duplicate records. Achieving idempotency requires unique identifiers for all data items and upsert semantics rather than append-only writes. Content-based hashing generates stable IDs from record contents, enabling deduplication even when source systems lack unique keys.
Ordering and Consistency
Distributed systems provide various consistency guarantees. At-least-once delivery ensures no data loss but permits duplicates. Exactly-once processing eliminates duplicates but requires more complex infrastructure. At-most-once delivery avoids duplicates but risks data loss. For AI workloads, at-least-once delivery combined with application-level deduplication provides the best balance—durability without infrastructure complexity.
Dead Letter Queues
Failed messages require special handling. Dead letter queues (DLQs) isolate problematic records for manual inspection while allowing healthy data to flow unimpeded. Monitoring DLQ growth surfaces systematic issues—malformed inputs, schema changes, or processing bugs. Without DLQs, failures either block entire pipelines or silently drop data.
6. Schema Management at Ingestion Time
Uncontrolled schema evolution is the silent killer of AI pipelines. Sources add fields, rename columns, change types, or alter semantics without warning. Downstream systems continue processing, producing corrupted features that degrade model quality gradually—too slowly to trigger immediate alarms but fast enough to cause measurable harm.
Schema Management Strategy:
1. Schema Registry: Central repository defining expected structures for all data sources
2. Validation at Ingestion: Reject or quarantine records that violate schemas before they contaminate pipelines
3. Versioning: Track schema versions alongside data, enabling retroactive analysis
4. Compatibility Checks: Automated tests verify new schemas maintain backward compatibility
5. Evolution Procedures: Formal processes for approving and deploying schema changes
Technologies like Apache Avro, Protocol Buffers, and Parquet embed schemas within data files, making validation straightforward. JSON and CSV require external schema definitions. Schema registries (Confluent Schema Registry, AWS Glue Data Catalog) provide centralized management and compatibility enforcement.
7. Raw Data Preservation: The Non-Negotiable Design Principle
The cardinal rule of data pipeline architecture: never mutate source data. Raw data must be preserved immutably, forever. Cleaning, normalization, and transformation create derived datasets—they never overwrite originals.
The rationale is simple. Cleaning logic contains bugs. Understanding of data evolves. Regulations change. Models require different preprocessing. When these inevitabilities occur, organizations that preserved raw data reprocess from source. Those that mutated originals face irrecoverable data corruption.
| Scenario | With Raw Preservation | Without Raw Preservation |
|---|---|---|
| Bug in Cleaning | Reprocess from raw, fix applied retroactively | Data permanently corrupted, models trained on bad data |
| New Requirements | Extract additional signals from historical raw data | Lost information, cannot recreate historical features |
| Compliance Audit | Demonstrate complete lineage from source to model | Cannot prove data provenance, regulatory risk |
| A/B Test Preprocessing | Generate multiple cleaned versions for comparison | Locked into single preprocessing approach |
Object storage (S3, GCS, Azure Blob) provides economical raw data preservation. Costs run $0.02-$0.05 per GB-month, making long-term retention viable. Lifecycle policies automatically archive aging data to cheaper storage tiers. The investment pays dividends when inevitable reprocessing becomes necessary.
8. Data Cleaning as a System, Not a Script
Ad-hoc cleaning scripts proliferate in early-stage AI projects. Each engineer writes custom logic. Notebooks contain undocumented transformations. Production systems inherit this technical debt, creating maintenance nightmares and reproducibility failures.
Mature organizations architect cleaning as a systematic, versioned, tested, and monitored component. Cleaning pipelines follow software engineering discipline:
- Modular transformations: Each cleaning operation implemented as a reusable function with clear input/output contracts
- Declarative configuration: Cleaning rules defined in YAML/JSON rather than hardcoded in Python/Scala
- Unit testing: Every transformation includes tests verifying correct handling of edge cases
- Validation gates: Cleaned data passes quality checks before downstream consumption
- Observability: Metrics track record volumes, rejection rates, and processing latency
Normalization and Enrichment
Normalization standardizes representations—dates to ISO 8601, currencies to base units, strings to lowercase. Enrichment adds derived attributes—geocoding addresses, categorizing text, computing aggregates. Both operations expand information content while maintaining traceability to raw sources.
9. Separating Cleaning Logic from Business Logic
A common architectural mistake: intermingling data cleaning with feature engineering or business logic. Cleaning normalizes formats and handles syntactic errors. Feature engineering extracts signals for models. Business logic encodes domain knowledge. Conflating these concerns creates fragile, unmaintainable pipelines.
Clean separation enables independent evolution. Cleaning logic changes when source formats shift. Feature engineering evolves as models improve. Business rules update with domain understanding. When coupled together, any change risks cascading failures across the entire pipeline.
Architectural Layers:
Layer 1 – Raw Ingestion: Collect data exactly as produced, zero transformations
Layer 2 – Cleaning: Fix syntactic issues, normalize formats, handle nulls
Layer 3 – Feature Engineering: Extract signals, compute aggregates, apply domain knowledge
Layer 4 – Model Preparation: Final formatting specific to model requirements
This layered architecture surfaces in large ML platforms. Each layer maintains separate code repositories, deployment schedules, and ownership. Changes in one layer rarely cascade to others. The discipline prevents the monolithic pipeline anti-pattern that plagues many AI systems.
10. Handling Imperfect Data: Noise, Bias, and Missing Signals
Perfect data is fiction. Real-world inputs contain noise, systematic biases, and missing values. Pipeline architecture must address imperfection through principled strategies rather than ad-hoc hacks.
| Issue Type | Detection Method | Handling Strategy | Trade-offs |
|---|---|---|---|
| Random Noise | Statistical outlier tests, IQR | Filtering, smoothing, robust statistics | May discard valid rare events |
| Systematic Bias | Group comparisons, demographic analysis | Resampling, reweighting, debiasing | Cannot remove bias from source |
| Missing Values | Null rate tracking, missingness patterns | Imputation, deletion, missingness indicators | Imputation introduces artificial signal |
| Label Errors | Cross-validation, confident learning | Cleaning, correction, noise-robust training | Risk discarding correct difficult examples |
Handling strategies involve trade-offs. Aggressive filtering removes noise but risks discarding informative outliers. Conservative approaches retain signal but permit noise to corrupt training. The optimal balance depends on downstream model robustness and business tolerance for errors.
11. Feature-Ready Data vs Model-Ready Data
“Clean” data is not automatically “usable” data for ML systems. Feature-ready data has passed validation and normalization. Model-ready data additionally satisfies modeling constraints: encoded categoricals, scaled numerics, handled imbalance, split into train/validation/test, and formatted for specific frameworks.
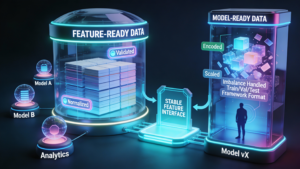
The distinction matters architecturally. Feature-ready data serves multiple consumers—different models, different teams, different use cases. Model-ready data targets a specific model version. Pipelines should produce feature-ready data as a stable interface, letting model training jobs handle final preparation. This separation enables model iteration without upstream pipeline changes.
12. Data Versioning: What Actually Needs to Be Versioned
Reproducibility requires versioning everything that influences model behavior. Partial versioning creates reproducibility theater—the illusion of control without actual ability to recreate results.
- Raw data snapshots: Immutable copies of source data as ingested
- Cleaning logic versions: Code, configurations, and dependencies that transform raw to clean
- Cleaned data snapshots: Output of cleaning pipeline, timestamped and content-hashed
- Feature definitions: Versioned feature engineering code and configurations
- Training datasets: Exact train/val/test splits with random seeds
- Labels and metadata: Ground truth values, labeling instructions, annotator IDs
Versioning strategies must balance completeness against cost. Content-addressable storage (CAS) using cryptographic hashes enables space-efficient versioning—unchanged data blocks aren’t duplicated. Delta encoding stores only differences between versions. Time-travel queries (Delta Lake, Iceberg) provide logical versioning without physical duplication.
13. Dataset Lineage and Reproducibility in AI
Lineage traces every model outcome back to its exact data state. Complete lineage answers: which raw data sources contributed to this prediction? What cleaning operations were applied? Which feature engineering version was used? What were the exact training examples?
Lineage requires systematic metadata capture at every pipeline stage. Modern data catalogs (DataHub, Marquez, OpenLineage) automatically track transformations, dependencies, and provenance. Without automated tracking, manual documentation drifts from reality.
Reproducibility benefits from lineage extend beyond debugging. Compliance audits require provenance proofs. A/B tests need to confirm equivalent data quality across variants. Incident investigations must isolate root causes. In every scenario, lineage transforms forensic investigations from speculation to deterministic analysis.
14. Version Control Strategies for Large-Scale Data
Git works brilliantly for code but fails catastrophically for multi-terabyte datasets. Specialized tools address large-scale data versioning: DVC (Data Version Control), LakeFS, and format-native versioning (Delta Lake, Iceberg).
These systems implement copy-on-write semantics. Creating new versions copies only changed data blocks, not entire datasets. Storage costs grow linearly with actual changes rather than dataset size. Branching enables experimentation without affecting production data. Merging reconciles divergent changes.
15. Managing Label Evolution and Human Feedback Loops
Labels drift faster than features. Annotator understanding evolves. Guidelines get refined. Edge cases emerge. Systematic label drift corrupts models trained on heterogeneous annotations—early examples labeled one way, later examples differently.
Versioning labeling instructions alongside labels enables drift detection. Cohort analysis comparing model performance across labeling periods surfaces systematic shifts. When drift is detected, options include relabeling historical data (expensive but thorough) or training on only recent consistent labels (cheaper but smaller dataset).
16. Data Quality Metrics That Actually Matter for AI
Generic data quality metrics (record counts, null rates) provide limited insight into ML-specific issues. AI-relevant metrics assess whether data enables effective learning:
| Quality Dimension | Metric | Acceptable Threshold | Impact if Violated |
|---|---|---|---|
| Class Balance | Minority class percentage | 5-20% for binary tasks | Model ignores minority class |
| Feature Completeness | Non-null rate per feature | >80% populated | Weak signal, biased predictions |
| Distribution Stability | KL divergence vs baseline | <0.1 for stable features | Training-serving mismatch |
| Temporal Coverage | Days of data represented | 90+ days typical | Seasonal biases, poor generalization |
| Label Consistency | Inter-annotator agreement | >0.7 Cohen’s kappa | Noisy labels, low model ceiling |
Monitoring these metrics throughout pipeline execution surfaces issues before they corrupt models. Automated quality gates reject datasets failing thresholds, preventing downstream propagation of quality issues.
17. Operational Monitoring of Data Pipelines
Data pipelines fail silently. Source APIs return partial data. Cleaning logic encounters unexpected formats. Downstream consumers process corrupted inputs. Without monitoring, these failures accumulate undetected until model degradation becomes severe enough to trigger complaints.
Comprehensive monitoring tracks:
- Volume metrics: Record counts, byte sizes, growth rates compared to baselines
- Freshness metrics: Data age, ingestion lag, staleness indicators
- Quality metrics: Null rates, schema violations, distribution shifts
- Processing metrics: Success rates, error rates, retry counts, DLQ sizes
- Latency metrics: End-to-end processing time, P50/P95/P99 percentiles
Alerting on these metrics requires tuning sensitivity. Too aggressive generates alert fatigue. Too lenient misses real issues. Effective strategies use anomaly detection rather than static thresholds—comparing current metrics against historical patterns adapts to natural variations while catching genuine deviations.
18. Security, Access Control, and Compliance in Data Pipelines
Data pipelines aggregate sensitive information from multiple sources, creating concentrated security and compliance risks. Architectural controls must address data protection throughout collection, storage, and transformation.
Access control follows least-privilege principles. Pipeline components receive permissions only for required operations. Service accounts separate from human users enable auditing and revocation. Encryption protects data at rest and in transit. Field-level encryption secures PII within larger datasets.
Compliance requirements (GDPR, HIPAA, CCPA) impose retention limits, consent tracking, and deletion obligations. Pipelines must tag data with compliance metadata, enforce retention policies automatically, and support right-to-erasure requests. The architecture complexity increases significantly but regulatory compliance is non-negotiable for production systems.
19. Common Anti-Patterns in AI Data Pipelines
The Monolithic Pipeline: All processing in single massive job. Changes ripple across entire system. Debugging requires understanding thousands of lines. One component failure blocks everything.
The Undocumented Transform: Critical cleaning logic exists only in someone’s notebook. No version control. No tests. Engineer leaves, knowledge vanishes. Pipeline breaks mysteriously months later.
The Manual Step: Pipeline includes “manually run this script” instructions. Automated scheduling impossible. Engineers become bottlenecks. Process documentation drifts from reality.
The Configuration Sprawl: Hardcoded parameters scattered across hundreds of files. Changing a threshold requires grep-and-replace. Testing variations becomes nightmare. Production-dev divergence guaranteed.
The Missing Validation: Data flows from ingestion to model without quality checks. Corrupted inputs train models for weeks before detection. Root cause analysis impossible without historical quality metrics.
The Over-Optimized Pipeline: Premature optimization creates baroque complexity. Custom formats, complex caching, tightly coupled components. Minimal performance gains, massive maintenance burden.
These anti-patterns emerge from optimization for short-term velocity over long-term maintainability. The technical debt compounds. Organizations eventually face complete pipeline rewrites costing months of engineering time and hundreds of thousands in costs.
20. Designing Data Pipelines for Long-Term AI System Evolution
Data pipelines outlive the models they serve. Organizations replace models quarterly but maintain core data infrastructure for years. Longevity demands architectural principles that accommodate change without rewrites.
Abstraction layers: Isolate consumers from source implementation details. Changing from batch to streaming ingestion shouldn’t require model retraining.
Versioned interfaces: When pipeline outputs change, version bumps signal breaking changes. Consumers opt into new versions rather than forced upgrades.
Pluggable components: Standard interfaces enable swapping implementations. Replace SQL-based cleaning with Spark without affecting upstream/downstream systems.
Comprehensive testing: Integration tests validate end-to-end behavior. Contract tests verify interface stability. Property-based tests catch edge cases.
Observability built-in: Monitoring, logging, and tracing embedded from day one. Retrofitting observability into legacy pipelines proves far more expensive.
The investment in principled architecture pays compounding returns. Systems designed for evolution adapt to new models, new data sources, new regulations, and new scale without fundamental rewrites. Those built for immediate needs face expensive rearchitecture every 18-24 months. The pattern holds across organizations: architectural discipline early determines operational burden long-term.
Data pipelines represent the foundation upon which AI systems build capabilities. Organizations that master pipeline architecture—reliability, quality, versioning, monitoring, security—position themselves to extract sustained value from AI investments. Those that treat pipelines as afterthoughts face perpetual firefighting, degraded model quality, and escalating technical debt. The path to AI maturity runs through data pipeline excellence.
Frequently Asked Questions
Q1.How much does it cost to build and maintain data pipelines for AI systems?
Infrastructure costs vary dramatically by architecture pattern and scale:
| Pipeline Type | Monthly Infrastructure | Annual Engineering | Total First Year |
|---|---|---|---|
| Simple Batch Pipeline | $500-$2,000 | $150K-$300K (1-2 engineers) | $156K-$324K |
| Streaming Pipeline | $3,000-$10,000 | $300K-$600K (2-4 engineers) | $336K-$720K |
| Hybrid Production System | $5,000-$15,000 | $500K-$1.2M (4-8 engineers) | $560K-$1.38M |
| Enterprise-Scale Platform | $20,000-$50,000 | $1M-$3M (8-20 engineers) | $1.24M-$3.6M |
Hidden costs often exceed initial estimates:
- Data storage: $500-$5,000/month for raw data preservation (grows 20-40% annually)
- Monitoring tools: $500-$3,000/month for observability platforms (Datadog, Grafana, custom)
- Third-party data: $5,000-$50,000/month for API access, feeds, and licensed datasets
- Incident response: $50,000-$200,000 per major pipeline failure in emergency fixes
- Technical debt paydown: $100,000-$500,000 annually for refactoring and optimization
Cost optimization insight: Organizations that invest $200K-$500K in proper architecture upfront reduce ongoing maintenance by 60-70% compared to those building quick prototypes that require complete rewrites every 18-24 months at $300K-$1M per rewrite.
Q2.Should I use batch ingestion or streaming ingestion for my data pipeline?
Decision framework based on latency requirements and complexity tolerance:
| Factor | Choose Batch When… | Choose Streaming When… |
|---|---|---|
| Latency Requirements | Hours-to-days acceptable (training data, reports, analytics) | Seconds-to-minutes required (fraud detection, real-time features) |
| Data Volume | Large periodic loads (TB+ daily) | Continuous moderate flow (GB/hour) |
| Team Expertise | SQL/Python skills, limited distributed systems experience | Kafka/Flink expertise, comfortable with distributed state |
| Cost Sensitivity | Budget-constrained ($500-$2K/month target) | Willing to pay 5-10x for low latency |
| Use Case | Model training, segmentation, forecasting | Monitoring, alerting, live personalization |
| Operational Complexity | Prefer simple scheduled jobs, easy debugging | Accept stateful processing, backpressure management |
Hybrid approach recommendation: 70% of production AI systems use hybrid architectures. Batch pipelines collect training data nightly ($500-$2K/month), while streaming pipelines serve real-time features during inference ($3K-$10K/month). This combination achieves 90% of pure streaming benefits at 30-40% of the cost.
Migration path: Start with batch for faster time-to-production (2-4 months vs 4-8 months for streaming). Add streaming components only when latency requirements justify the added complexity and cost. Organizations that prematurely optimize for streaming waste $100K-$300K building infrastructure they don’t yet need.
Q3.How long does it take to build production-ready data pipelines from scratch?
Realistic timeline for enterprise-grade pipelines:
| Phase | Duration | Team Size | Key Deliverables |
|---|---|---|---|
| Design & Planning | 2-4 weeks | 2-3 engineers | Architecture diagrams, data source inventory, technology choices |
| Ingestion Setup | 4-8 weeks | 2-4 engineers | Raw data collection, schema validation, storage infrastructure |
| Cleaning & Transformation | 4-6 weeks | 2-3 engineers | Validation rules, normalization, quality checks |
| Versioning & Lineage | 2-4 weeks | 1-2 engineers | Version control, metadata tracking, reproducibility |
| Monitoring & Observability | 3-6 weeks | 1-2 engineers | Quality metrics, drift detection, alerting, dashboards |
| Security & Compliance | 2-4 weeks | 1-2 engineers | Access controls, encryption, audit logging, PII handling |
| Testing & Stabilization | 2-4 weeks | 2-3 engineers | Integration tests, load testing, failure scenarios |
Total timeline: 4-7 months for production-ready pipelines with proper architecture. Organizations cutting corners reach “working” state in 6-10 weeks but accumulate technical debt requiring complete rebuilds within 12-18 months at $300K-$1M cost.
Acceleration strategies: Managed platforms (AWS Glue, Azure Data Factory, Fivetran) reduce timeline to 2-3 months by eliminating infrastructure building. Trade-off is vendor lock-in and 30-50% higher ongoing costs ($3K-$8K/month vs $1K-$4K/month for custom).
Critical insight: Timeline assumes parallel workstreams. Serial development (one engineer doing everything) extends timeline 2-3x. Team experience matters—seasoned data engineers reduce each phase by 30-40% vs teams learning as they build.
Q4.What causes data pipeline failures in production, and how can they be prevented?
Top failure modes accounting for 80% of production incidents:
| Failure Type | Frequency | Detection Time | Prevention Strategy | Implementation Cost |
|---|---|---|---|---|
| Schema Changes | 35% of failures | 2-6 weeks average | Schema registry + validation at ingestion | $20K-$60K setup |
| Data Quality Issues | 30% of failures | 3-8 weeks average | Automated quality checks + monitoring | $30K-$100K setup |
| Infrastructure Failures | 20% of failures | Minutes to hours | Redundancy + circuit breakers + retries | $40K-$150K setup |
| Upstream API Changes | 15% of failures | 1-4 weeks average | Contract testing + API versioning | $15K-$50K setup |
| Processing Bugs | 10% of failures | Days to weeks | Comprehensive testing + staging environments | $25K-$80K setup |
Prevention ROI: Organizations investing $150K-$400K in comprehensive prevention (validation, monitoring, testing, redundancy) reduce incident frequency by 70-85% and detection time from weeks to hours. Average incident costs $50K-$200K in emergency fixes plus downstream model degradation. ROI positive within 2-4 incidents.
Monitoring prevents silent failures: Without monitoring, 60% of pipeline issues go undetected for 2+ weeks, causing 20-40% model accuracy degradation. With proper monitoring, 90% of issues are detected within 24 hours, limiting degradation to 5-10% before remediation.
Q5.What tools and technologies should I use for AI data pipelines?
Technology stack by pipeline component:
| Component | Open Source Options | Managed/Commercial Options | When to Use Each |
|---|---|---|---|
| Batch Ingestion | Apache Airflow, Prefect, Luigi | AWS Glue, Azure Data Factory, Fivetran | Open source: custom logic needs. Managed: standard connectors |
| Stream Processing | Apache Kafka, Flink, Spark Streaming | Confluent Cloud, Amazon Kinesis, Azure Stream | Open source: cost-sensitive. Managed: expertise-limited |
| Data Storage | Delta Lake, Apache Iceberg, Parquet | Snowflake, BigQuery, Databricks | Open source: storage on S3/GCS. Managed: integrated analytics |
| Data Quality | Great Expectations, deequ, soda-core | Monte Carlo, Databand, Bigeye | Open source: budget constraints. Managed: comprehensive coverage |
| Data Versioning | DVC, Delta Lake time-travel, LakeFS | Pachyderm, Databricks versioning | Open source: control + flexibility. Managed: ease-of-use |
| Monitoring | Prometheus, Grafana, custom metrics | Datadog, New Relic, Splunk | Open source: infrastructure monitoring. Managed: full observability |
Decision framework:
- Start with managed services when team has <3 engineers or limited distributed systems expertise. Time-to-production 2-3x faster.
- Move to open source when monthly costs exceed $10K-$15K or custom requirements emerge. Break-even typically 12-18 months.
- Hybrid approach works best: managed ingestion (Fivetran) + open source processing (Airflow) + managed storage (Snowflake).
- Avoid premature optimization: Starting with Kafka when batch would suffice wastes $100K-$300K in unnecessary complexity.
Technology selection anti-pattern: Choosing tools based on resume-building rather than requirements. The “let’s use Kafka because it’s popular” decision costs organizations $200K-$500K annually when simpler batch solutions would suffice. Technology should serve architecture, not ego.
Q6.How do I ensure data quality in my AI pipelines, and what metrics should I monitor?
Comprehensive data quality framework:
| Quality Dimension | Key Metrics | Acceptable Thresholds | Monitoring Frequency | Remediation Priority |
|---|---|---|---|---|
| Completeness | Non-null rate, record count | >80% populated per feature | Every pipeline run | High – blocks training |
| Freshness | Data age, lag from source | <24 hours for training data | Hourly | Medium – degrades gradually |
| Consistency | Schema compliance, type matching | 100% schema adherence | Every pipeline run | Critical – immediate failure |
| Accuracy | Duplicate rate, outlier rate | <1% duplicates, <5% outliers | Daily | High – introduces bias |
| Distribution Stability | KL divergence, Chi-squared | <0.1 KL divergence vs baseline | Weekly | Medium – indicates drift |
| Class Balance | Minority class percentage | 5-20% for binary classification | Per training dataset | High – causes poor learning |
Implementation approach:
- Layer 1 – Ingestion validation: Schema checks, null rate checks, basic range validation (catches 40-50% of issues)
- Layer 2 – Processing validation: Distribution checks, outlier detection, duplicate detection (catches additional 30-40%)
- Layer 3 – Output validation: Final quality gates before model consumption (catches remaining 10-20%)
- Layer 4 – Continuous monitoring: Track metrics over time, detect gradual degradation (prevents silent failures)
Cost-benefit analysis: Quality monitoring infrastructure costs $30K-$100K to implement but prevents $50K-$200K incidents occurring 2-4x annually. ROI positive within 3-6 months. Organizations without quality monitoring spend 3-5x more on incident response than those with comprehensive coverage.
Monitoring reality: Generic metrics (record counts) catch obvious failures. ML-specific metrics (distribution stability, class balance) catch subtle degradation causing 15-30% accuracy loss. The latter justify their implementation cost within the first prevented incident.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.