
Building Reliable and Scalable AI Products Through Evaluation-Driven Development
Humanloop was created to help teams build production-ready AI applications with greater confidence. Instead of relying only on prompt experimentation or manual testing, Humanloop enables organizations to develop, evaluate, monitor, and continuously improve AI systems through a unified platform.
Designed for enterprise AI teams, Humanloop simplifies the process of managing prompts, tracking performance, validating outputs, and collaborating across engineering and business teams to deliver more reliable AI experiences.
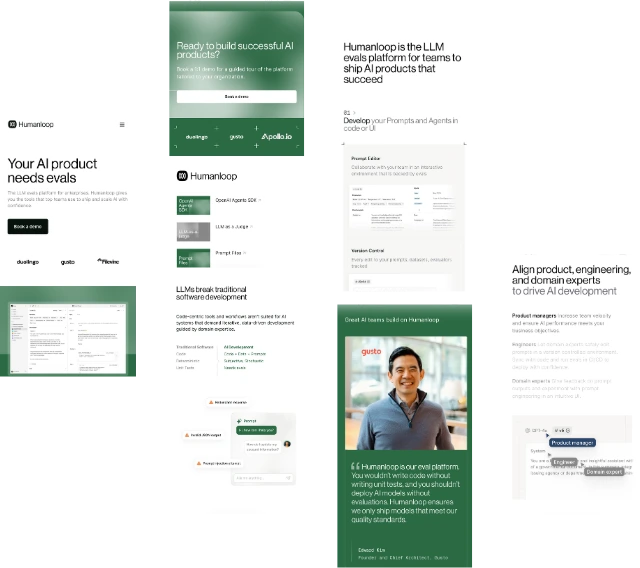
Get Started with Humanloop
Humanloop provides an evaluation-driven framework that helps teams measure AI output quality using automated testing, human review, and custom evaluation methods to improve reliability and production readiness.
The platform offers a collaborative prompt development environment where teams can create, experiment, optimize, and manage prompts while maintaining consistency across multiple AI applications and workflows.
Humanloop tracks every update across prompts, evaluations, datasets, and configurations, helping teams maintain reproducible development cycles and improve collaboration throughout the AI product lifecycle.
The platform continuously monitors application behavior, output performance, and system activity to identify issues quickly and support ongoing optimization for production AI environments.
Humanloop enables domain experts and business teams to participate in evaluation workflows by reviewing outputs and providing feedback that improves model quality and decision accuracy.
Teams can build and test AI applications across multiple language models and providers, reducing dependency on a single ecosystem while improving flexibility and experimentation.
Humanloop automates evaluation processes within development workflows to detect performance changes early, reduce deployment risks, and maintain consistent output quality over time.
The platform delivers real-time visibility into AI application performance through analytics and evaluation insights, helping teams make faster improvements and better operational decisions.
Humanloop aimed to solve one of the biggest challenges in enterprise AI adoption: moving AI applications from experimentation into reliable production systems.
Traditional software testing methods were not sufficient for AI workflows where outputs vary based on prompts, models, and contextual inputs. The platform required a solution that could combine evaluation, observability, prompt management, and collaboration into one ecosystem. Another major objective was enabling both technical and non-technical teams to contribute to AI optimization without increasing operational complexity.
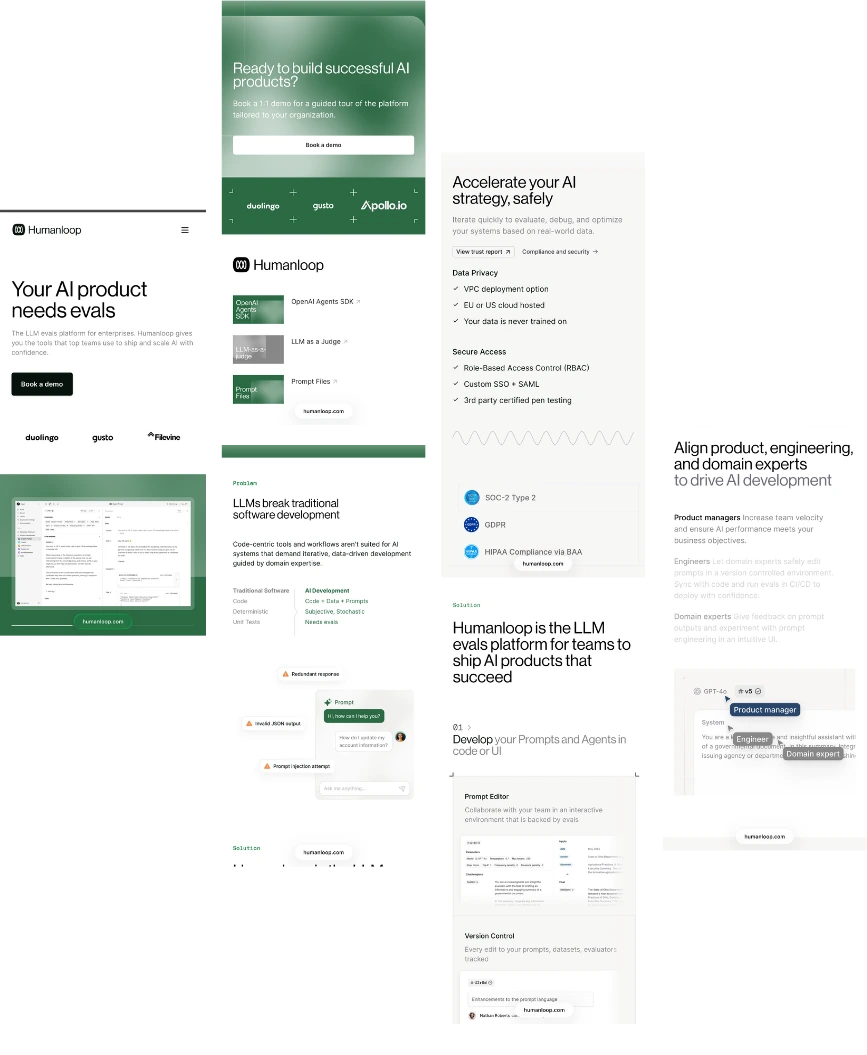
Humanloop uses evaluation-driven workflows to continuously measure output quality, validate AI performance, identify regressions early, and support more reliable deployment decisions across production environments.
The platform manages prompts, datasets, agents, and workflow updates through structured lifecycle processes that improve traceability, collaboration, experimentation speed, and operational consistency.
Humanloop incorporates expert review and human feedback directly into evaluation cycles to refine outputs, improve contextual understanding, and strengthen overall AI application reliability.
The platform continuously tracks AI behavior, response quality, and operational metrics to identify performance issues, support debugging processes, and improve production stability.
Primary font family and usage
Brand colors
#000000
#2a6a43
#a3bead
Instead of building another AI orchestration layer, Humanloop focused on creating infrastructure that makes AI development measurable and repeatable.
The architecture centered around integrating prompt management, evaluation pipelines, monitoring, and collaboration into a unified development lifecycle.
By introducing evaluation-first workflows and enabling teams to iterate using real performance signals, Humanloop reduced the uncertainty traditionally associated with AI deployments.
The platform also emphasized compatibility with existing engineering environments to improve adoption across enterprise teams.
Humanloop established itself as an evaluation-focused AI development platform helping organizations improve AI reliability and deployment confidence.
The platform enabled teams to adopt structured experimentation processes, reduce regression risks, and accelerate delivery of AI-powered products.
Through evaluation automation, observability tooling, and collaborative workflows, Humanloop strengthened how enterprises manage production AI systems.
As adoption expanded, Humanloop positioned itself as AI infrastructure for building trustworthy and scalable LLM applications.
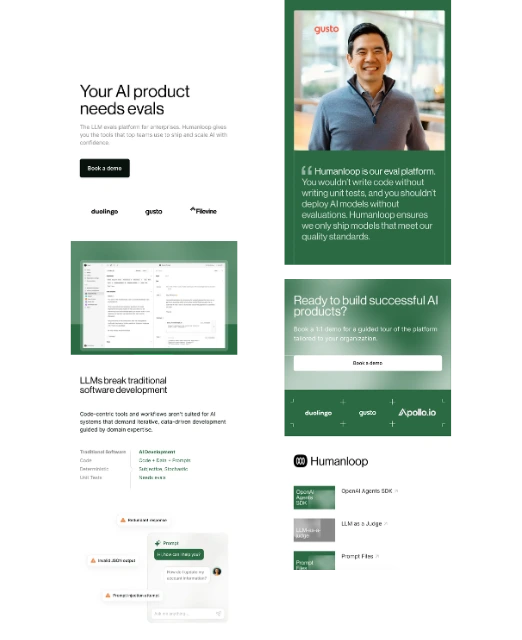
AI models do not always generate the same quality of responses because outputs can change based on prompts, model versions, input context, and data conditions. This makes it difficult for teams to maintain consistent results, requiring continuous testing, evaluation, and optimization before releasing updates into production.
As teams create and update prompts regularly, maintaining performance becomes more challenging over time. Small prompt changes can impact response quality, making structured version control, organized testing, and reproducible workflows necessary for managing AI applications effectively.
Human feedback plays an important role in improving AI quality, but reviewing every output manually becomes difficult as applications grow. Teams need balanced processes that combine automated evaluations with expert reviews to maintain quality without slowing development.
Monitoring AI systems in production requires more than tracking uptime or technical metrics. Teams must observe output quality, user interactions, performance changes, and unexpected behaviors continuously to detect issues early and improve long-term application reliability.
Humanloop is built to make AI development easier and more reliable for businesses. Instead of teams manually checking prompts and testing outputs again and again, the platform provides tools that help manage, evaluate, and improve AI applications in a more structured way.
The platform brings together prompt creation, evaluation workflows, monitoring systems, and performance tracking in one place. This allows teams to understand how their AI applications are performing, identify issues early, and make improvements before launching updates.



