Ai Overview
The term “serverless” can be misleading at first glance. These databases charge based on read/write throughput and storage consumption, aligning perfectly with serverless cost models. If your application receives 1,000 requests per day, each taking 200ms to process, you pay for 200 seconds of compute time. Serverless eliminates upfront infrastructure investment and scales automatically as user adoption grows.
Key Takeaways: Serverless Computing Essentials
Understanding Serverless Computing
What Does “Serverless” Actually Mean?
The term “serverless” can be misleading at first glance. Servers still exist in serverless computing, but they’re completely abstracted away from your development and operational concerns. When you build applications using serverless architecture, you’re essentially delegating all server management responsibilities to cloud service providers.
The fundamental shift here revolves around execution model and responsibility. In traditional environments, you provision servers, configure operating systems, manage patches, handle scaling, and monitor infrastructure health. Serverless eliminates these tasks entirely. You write code that responds to specific events, and the cloud provider handles everything else including provisioning, scaling, patching, and availability.
The serverless model operates on an event-driven execution pattern. Your functions remain dormant until triggered by specific events such as HTTP requests, database changes, file uploads, or scheduled tasks. Once triggered, the platform automatically allocates resources, executes your code, and deallocates resources when execution completes. This creates a truly elastic infrastructure that scales from zero to thousands of concurrent executions automatically.
Payment structure follows actual usage rather than reserved capacity. You’re billed based on the number of requests processed and the compute time consumed, measured in milliseconds. If your function isn’t running, you’re not paying. This granular billing model fundamentally changes cost economics, especially for applications with variable or unpredictable traffic patterns.
How Serverless Works Behind the Scenes
Understanding the execution lifecycle helps demystify serverless operations. The process begins when an event source generates a trigger. This could be an incoming API request, a new message in a queue, a file uploaded to storage, or a scheduled time arriving.
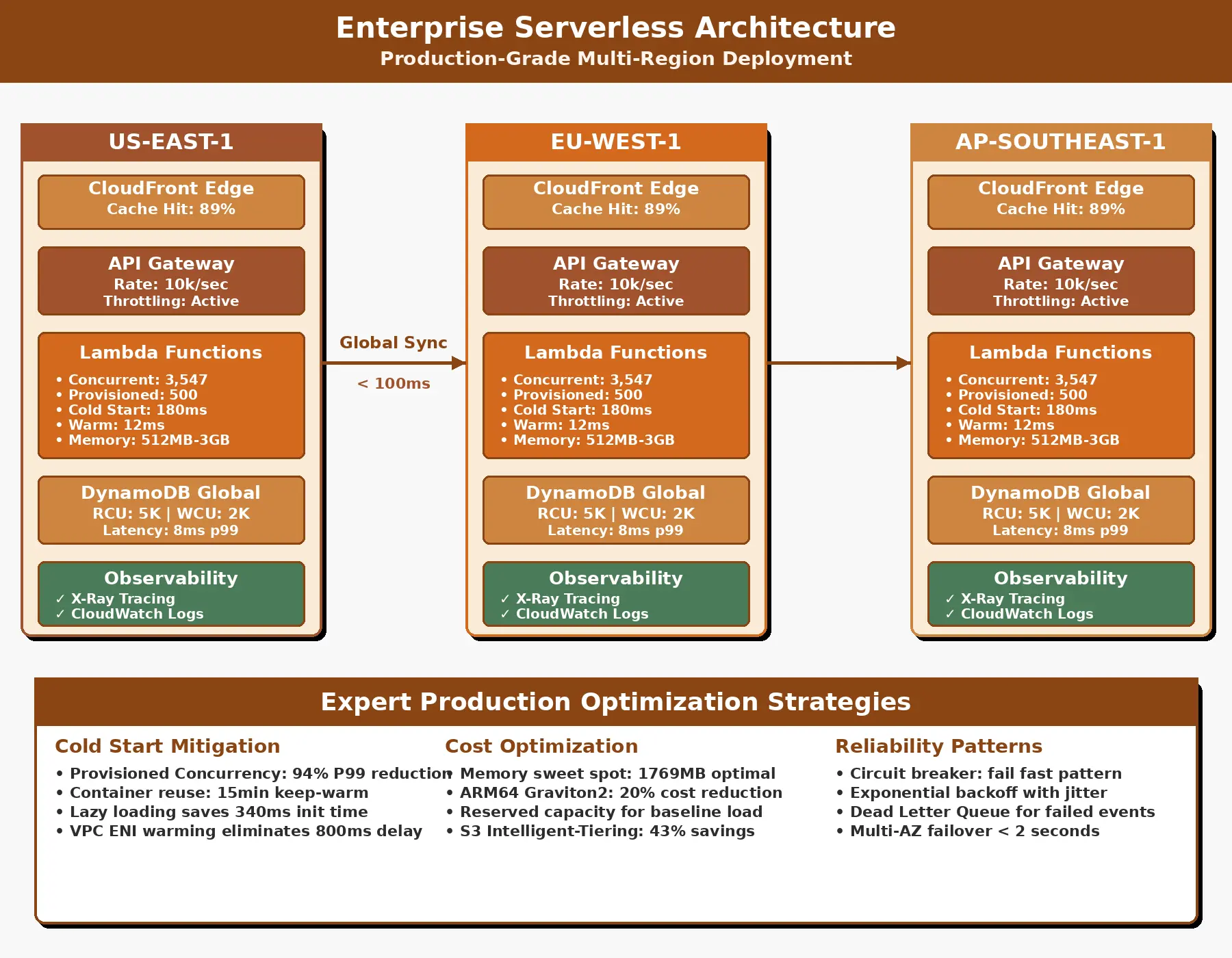
During step two, container initialization can introduce latency known as a cold start. The platform must allocate compute resources, download your code, initialize the runtime environment, and execute any initialization code before processing the actual request. Subsequent requests may reuse warm containers, significantly reducing latency. The platform maintains containers warm for a short period after execution, optimizing for scenarios where requests arrive in quick succession.
Scaling happens transparently and instantly. When multiple events arrive simultaneously, the platform spawns parallel execution environments. Each instance processes one request at a time, ensuring isolation and consistent performance. The system can scale from handling a single request to thousands per second without any configuration changes or manual intervention.
Core Components of Serverless Architecture
Functions as a Service (FaaS)
Functions as a Service represents the computational core of serverless architecture. FaaS platforms provide the runtime environment where your code executes in response to events. The three dominant platforms each bring distinct characteristics while sharing fundamental serverless principles.
| Platform | Key Features | Best For |
|---|---|---|
| AWS Lambda | Supports Node.js, Python, Java, Go, Ruby, .NET. Up to 15 min execution, 128MB to 10GB memory. | AWS ecosystem integration, enterprise scale |
| Azure Functions | Supports all Lambda languages plus PowerShell, TypeScript. Durable Functions for stateful workflows. | Microsoft environments, hybrid cloud |
| Google Cloud Functions | Automatic scaling, Cloud Pub/Sub integration, AI/ML service connectivity. | Data pipelines, real-time analytics, ML workflows |
AWS Lambda pioneered the FaaS category and remains the most widely adopted platform. The platform integrates seamlessly with the entire AWS ecosystem, making it the natural choice for applications already running on AWS infrastructure. Azure Functions provides deep integration with Azure services and enterprise environments, excelling in scenarios requiring hybrid cloud deployments. Google Cloud Functions focuses on simplicity and tight integration with Google Cloud Platform services, particularly shining in data processing and machine learning workflows.
Backend Services in Serverless Applications
Serverless applications rely on managed backend services that eliminate infrastructure management while providing enterprise-grade capabilities. These services integrate through APIs and event-driven patterns, creating cohesive application architectures without server management.
Database services like Amazon DynamoDB, Azure Cosmos DB, and Google Firestore provide fully managed NoSQL storage with automatic scaling and high availability. These databases charge based on read/write throughput and storage consumption, aligning perfectly with serverless cost models. For relational workloads, services like Aurora Serverless automatically adjust database capacity based on application demand.
Object storage through S3, Azure Blob Storage, or Google Cloud Storage handles file storage needs with unlimited scalability. These services trigger serverless functions when files are uploaded, modified, or deleted, enabling powerful data processing workflows. Authentication and authorization integrate through managed services, providing user management without custom infrastructure.
Event Sources and Triggers
Events drive serverless execution. Understanding available event sources helps you design responsive, efficient applications.
Traditional Backend vs Serverless Architecture
Infrastructure Management Comparison
| Aspect | Traditional Backend | Serverless Architecture |
|---|---|---|
| Server Provisioning | Manual selection, sizing, and deployment of virtual machines or containers | Completely automated, invisible to developers |
| Operating System | Requires patching, security updates, and configuration management | Fully managed by platform provider |
| Scaling Strategy | Manual configuration of auto-scaling rules, load balancers, and health checks | Automatic, instantaneous scaling from zero to thousands |
| Capacity Planning | Forecast demand, provision for peak capacity | No planning required, scales with actual demand |
| High Availability | Configure multi-zone deployments, failover mechanisms | Built-in across availability zones by default |
| Maintenance Windows | Scheduled downtime for updates and patches | Zero downtime, continuous updates by provider |
The infrastructure burden disappears entirely in serverless architectures. Teams that previously spent significant time managing servers, configuring networking, implementing monitoring, and handling operational incidents can redirect that effort toward feature development and business value creation. This shift fundamentally changes team composition and skill requirements, reducing the need for dedicated operations staff in many scenarios.
Cost Model Comparison
Traditional infrastructure operates on a reservation model. You provision servers sized for peak capacity and pay for them continuously, regardless of actual utilization. During low traffic periods, you’re paying for idle resources. During unexpected traffic spikes, you either experience performance degradation or maintain expensive over-provisioned capacity.
Serverless computing charges only for actual compute time consumed. If your application receives 1,000 requests per day, each taking 200ms to process, you pay for 200 seconds of compute time. The rest of the day costs nothing.
API serving 5 million requests monthly with 300ms average execution time and 512MB memory allocation:
Traditional Server: $50 to $150 per month for continuously running instance sized for peak load
Serverless: $8 to $12 per month based on actual request count and execution time
Savings: 80% to 90% reduction in compute costs
However, serverless isn’t always cheaper. High traffic applications running continuously can exceed traditional server costs due to per request pricing. The crossover point typically occurs around 70% to 80% constant utilization. Applications with predictable, sustained high traffic might find traditional or container-based infrastructure more economical.
Development & Deployment Speed Comparison
Serverless dramatically accelerates development velocity. Developers write focused functions handling specific tasks rather than building comprehensive application servers. Deployment involves uploading code to the cloud platform, with no server configuration, dependency installation on production systems, or infrastructure provisioning delays.
Real-World Examples of Serverless Applications
Serverless Web Application Example
A complete web application can run entirely on serverless infrastructure. The frontend, built with React, Vue, or Angular, deploys to object storage like S3 with CloudFront distribution for global content delivery. User requests hit API Gateway endpoints that trigger Lambda functions. These functions authenticate users through Cognito, query DynamoDB for data, and return JSON responses.
This architecture eliminates web servers entirely. Static assets serve from CDN edge locations for minimal latency. API logic scales automatically with traffic. Database capacity adjusts to match demand. The entire stack operates without a single server to manage, patch, or monitor at the infrastructure level.
Mobile App Backend Example
Mobile applications benefit enormously from serverless backends. The mobile app communicates with API Gateway endpoints secured by JWT authentication. Functions handle user registration, profile management, content retrieval, and push notification delivery.
When users upload photos or videos, storage events trigger processing functions that resize images, transcode videos, generate thumbnails, and update content databases. Background tasks like daily summary generation, recommendation engine updates, and analytics aggregation run on scheduled triggers. The backend automatically handles traffic spikes during viral events or marketing campaigns without manual intervention.
Event-Driven Data Processing Example
Data pipelines excel in serverless architectures. IoT devices send telemetry data to Kinesis streams. Lambda functions process each data point, performing validation, enrichment, and transformation. Processed data writes to time-series databases or data warehouses.
This pattern scales effortlessly from hundreds to millions of events per second. Each function invocation processes a batch of records independently. Failed processing retries automatically. The system maintains exactly once processing semantics through built-in platform features.
Real-Time Application Example
Collaborative editing tools, live chat systems, and multiplayer games use serverless WebSocket APIs for real-time bidirectional communication. When users connect, Lambda functions establish WebSocket connections stored in DynamoDB. Messages from one client trigger functions that broadcast to other connected clients.
Practical Use Cases of Serverless Computing
Startup MVP Development
Startups building minimum viable products face tight budgets and uncertain demand. Serverless eliminates upfront infrastructure investment and scales automatically as user adoption grows.
The pay-per-use model aligns perfectly with startup economics. Early stages with limited users cost almost nothing. Viral growth doesn’t crash the application or require emergency infrastructure scaling. Technical founders can build and deploy complete applications single-handedly, without dedicated operations expertise.
SaaS Product Development
Software as a Service platforms require multi-tenant architectures, usage-based billing, and elastic scaling. Serverless provides the perfect foundation. Each customer’s requests trigger isolated function executions, ensuring tenant isolation without complex infrastructure segmentation.
| Multi-Tenancy | Isolated function executions ensure tenant separation without infrastructure complexity |
| Usage Billing | Function invocation metrics feed directly into customer billing systems |
| Background Jobs | Reports, exports, emails run on-demand rather than consuming permanent resources |
| API Integrations | Webhooks and automation workflows deploy as individual functions |
Fintech & Payment Systems
Financial technology applications demand high availability, security, and compliance. Serverless platforms provide enterprise-grade infrastructure with built-in redundancy, automatic failover, and compliance certifications.
Payment processing functions handle transaction validation, fraud detection, and payment gateway integration with automatic scaling during high volume periods like sales events or month-end processing. Audit trails, transaction logging, and regulatory reporting leverage event-sourcing patterns where every action triggers functions that record details to immutable storage.
eCommerce Platforms
Online retail experiences dramatic traffic variability. Black Friday traffic might be 50 times normal levels. Serverless handles these spikes effortlessly. Product catalog APIs, search functionality, shopping cart management, and checkout processing all run as serverless functions that scale automatically.
Catalog API → Lambda → DynamoDB → Product Data → Frontend Display
Checkout → Lambda → Payment Gateway → Inventory Check → Order Confirmation
Order Event → Lambda → Inventory Update → Shipping Label → Email Notification
Product Upload → S3 → Lambda → Multiple Sizes → Device Optimization
Healthcare & Secure Data Systems
Healthcare applications require HIPAA compliance, data encryption, and audit logging. Serverless platforms offer compliance certifications and built-in security features that simplify meeting regulatory requirements. Patient data APIs enforce strict access controls through IAM policies and encryption at rest and in transit.
Medical image processing leverages GPU-accelerated functions for analysis and diagnosis support. Integration with legacy healthcare systems happens through scheduled functions that sync data, transform formats, and maintain consistency across disparate systems. The stateless architecture ensures no patient data persists in function memory after execution, reducing privacy risks.
Benefits of Using Serverless Computing
Automatic Scaling & High Availability
Serverless platforms handle scaling as a fundamental platform capability. Traffic increases trigger proportional function invocations without configuration, thresholds, or manual intervention. The system distributes load across availability zones automatically, ensuring no single point of failure.
Faster Time to Market
Development velocity increases dramatically when infrastructure concerns disappear. Teams ship features faster because they’re not waiting for server provisioning, configuring deployment pipelines, or troubleshooting infrastructure issues.
| Development Phase | Traditional Approach | Serverless Approach |
|---|---|---|
| Initial Setup | Days to configure infrastructure, servers, databases | Minutes to create function and configure triggers |
| Feature Development | Include infrastructure code alongside business logic | Focus exclusively on business logic |
| Testing | Setup test environments, manage test databases | Use managed test environments and mocking |
| Deployment | Hours for coordinated infrastructure and app deployment | Seconds to upload code and update function |
| Scaling Preparation | Configure auto-scaling, load balancers, monitoring | Automatic, no configuration needed |
Cost Optimization
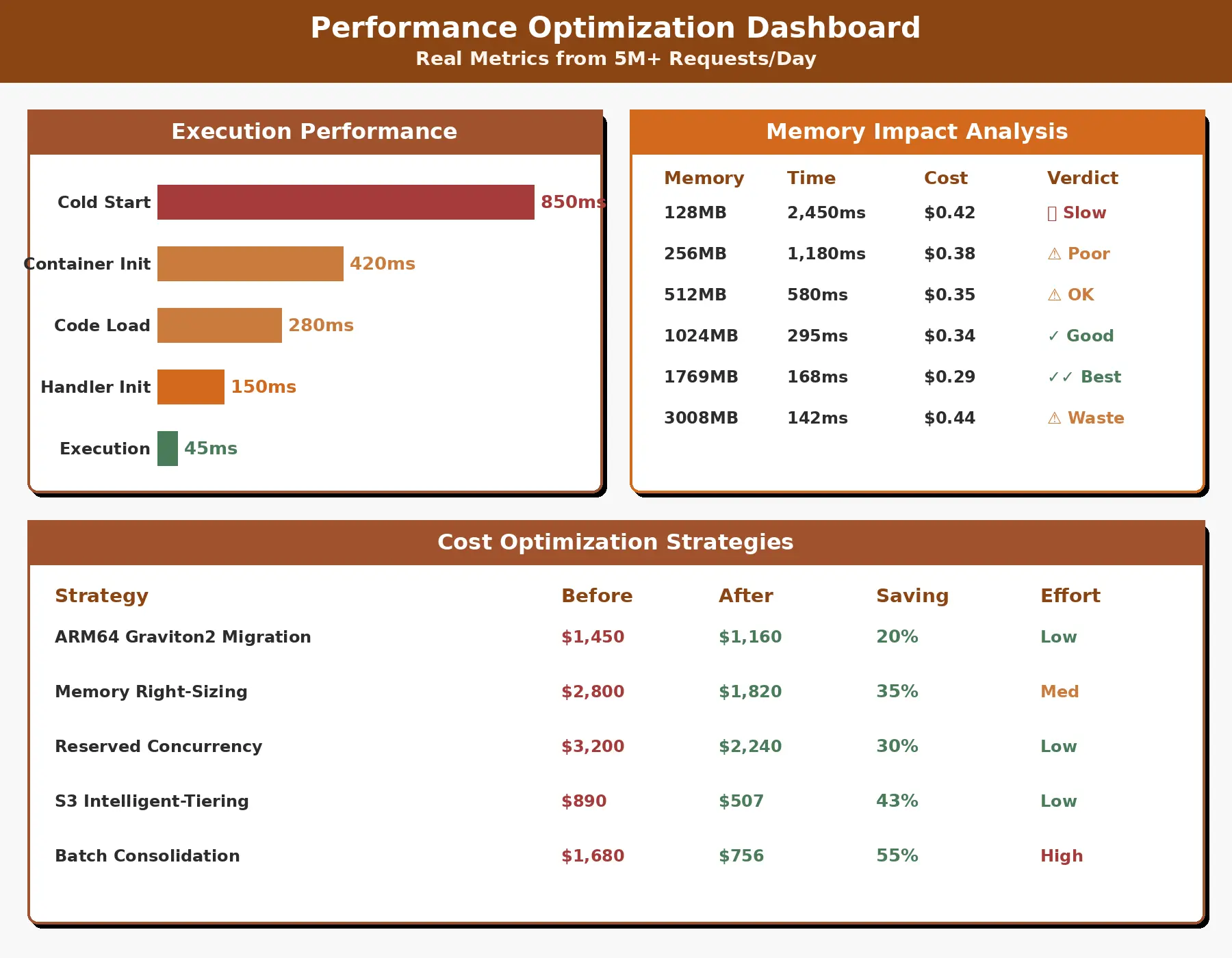
The granular billing model eliminates waste from idle resources. Traditional servers consume money 24/7 regardless of utilization. Serverless functions cost nothing when not executing. This creates exceptional efficiency for applications with variable or unpredictable workloads.
Reduced Operational Overhead
Operations teams shrink or disappear entirely as infrastructure management responsibilities transfer to cloud providers. No more patching operating systems, updating runtime environments, configuring monitoring, or responding to infrastructure alerts at 3 AM. Security updates apply automatically without service disruption.
This enables small teams to build and operate sophisticated applications. A team of five developers can support millions of users without dedicated operations staff. Focus shifts from keeping systems running to building features that delight users.
Challenges & Limitations of Serverless
Cold Starts Explained
Cold starts represent the most visible serverless limitation. When a function hasn’t executed recently, the platform must initialize a new execution environment. This involves allocating compute resources, loading your code, initializing the runtime, and executing initialization code before processing the actual request.
| Phase | Duration | Impact |
| Container Allocation | 50ms to 200ms | Platform provisions compute resources |
| Code Download | 100ms to 500ms | Depends on package size |
| Runtime Initialization | 200ms to 2s | Language runtime and dependencies load |
| Application Init | Variable | Database connections, configuration loading |
Vendor Lock-In Considerations
Serverless platforms introduce tight coupling to provider-specific services. Code written for AWS Lambda using DynamoDB, SQS, and API Gateway doesn’t port easily to Azure Functions or Google Cloud Functions. Migration requires rewriting integration code, adapting to different service APIs, and potentially restructuring application architecture.
Debugging & Monitoring Complexity
Distributed serverless applications create debugging challenges. A single user request might trigger dozens of function invocations across multiple services. Tracing execution flow, correlating logs, and identifying root causes requires sophisticated observability tools.
Traditional debugging approaches like setting breakpoints or stepping through code don’t work for ephemeral function executions. Cloud providers offer monitoring services, but these require careful instrumentation and can become expensive at scale. Structured logging, distributed tracing, and correlation IDs become essential practices.
Security & Compliance Challenges
Serverless security requires different thinking than traditional infrastructure. Each function needs appropriate IAM permissions, following the principle of least privilege. Overly permissive policies create security vulnerabilities. Managing hundreds of function-specific policies becomes complex.
When Should You Use Serverless?
Best-Fit Scenarios
Serverless excels in specific scenarios where its characteristics align with application requirements. Applications with variable or unpredictable traffic patterns benefit enormously from automatic scaling and pay-per-use pricing. Event-driven workloads processing asynchronous tasks, responding to data changes, or handling webhooks map naturally to serverless function invocations.
Startups and small teams gain disproportionate benefits. Limited resources make serverless operational simplicity invaluable. The ability to build and scale applications without infrastructure expertise or dedicated operations teams levels the playing field against larger competitors.
When Serverless Is Not the Right Choice
Certain application characteristics make serverless inappropriate. Long-running processes exceeding function timeout limits require traditional compute. Applications with consistent high traffic running 24/7 might cost more in serverless than dedicated infrastructure.
| Scenario | Why Not Serverless | Better Alternative |
|---|---|---|
| Long Running Processes | Function timeout limits (typically 15 minutes max) | Container services, batch processing systems |
| Consistent High Traffic | Per-request pricing exceeds reserved instance costs | Traditional VMs or containers |
| Ultra-Low Latency | Cold start delays unacceptable | Always-on services with warm instances |
| Heavy Compute Workloads | Resource limits or cost prohibitive | GPU instances, HPC clusters |
| Stateful Applications | Complex state management across invocations | Stateful containers or traditional servers |
| Legacy Monoliths | Refactoring costs outweigh benefits | Lift and shift to cloud VMs |
Serverless Computing in Modern Software Development
Role of Serverless in Cloud-Native Systems
Serverless computing represents the logical evolution of cloud-native development. It embodies core cloud-native principles including elastic scaling, resilience, and managed services. Applications built serverless-first leverage cloud platforms fully, consuming capabilities as services rather than managing infrastructure.
The serverless model complements containerized applications within cloud-native ecosystems. Functions handle event processing, API endpoints, and background tasks while containers run long-running services, databases, and complex workflows. This hybrid approach captures benefits of both paradigms, using the right tool for each component based on its characteristics and requirements.
Serverless & Microservices Relationship
Serverless and microservices share architectural philosophies but differ in implementation. Both favor small, focused components with clear boundaries. Microservices typically run as long-lived processes in containers, while serverless functions execute on-demand in response to events.
| Characteristic | Microservices | Serverless Functions |
| Execution Model | Long-running processes | Event-triggered, ephemeral |
| Deployment Unit | Container image | Function code package |
| Scaling | Container orchestration | Platform automatic scaling |
| Operations | Container management required | Fully managed by platform |
Future Trends of Serverless Technology
Serverless computing continues rapid evolution. Edge computing extends serverless to CDN edge locations, executing functions close to users for ultra-low latency. This enables real-time applications, personalization, and content transformation at the edge.
WebAssembly runtimes provide language-agnostic execution environments with better cold start performance and portability across platforms. Container-based serverless platforms offer function-like deployment and scaling while supporting container packaging and longer execution times. Machine learning inference increasingly leverages serverless for model serving, providing elastic scaling for unpredictable ML workload patterns.
Summary: Is Serverless Right for Your Application?
Serverless computing transforms how we build and operate applications by eliminating infrastructure management and enabling true pay-per-use economics. The model excels for event-driven workloads, variable traffic patterns, and rapid development scenarios. It empowers small teams to build and scale sophisticated applications without operational overhead or significant upfront investment.
However, serverless isn’t a universal solution. Cold starts, vendor lock-in, debugging complexity, and cost characteristics at high scale require careful consideration. Applications with constant high traffic, strict latency requirements, or specialized infrastructure needs may benefit from alternative approaches.
Variable or unpredictable traffic favors serverless. Consistent high traffic may favor traditional infrastructure.
If sub-100ms response times are critical, consider cold start mitigation strategies or alternatives.
Small teams benefit enormously from reduced operational complexity. Large teams may have existing expertise.
Time to market, cost optimization, and scalability priorities influence the serverless decision.
The most successful serverless adoption combines pragmatism with enthusiasm. Start with clear use cases where serverless benefits are obvious, such as APIs, background processing, or data transformation. Gain experience with platform capabilities and limitations. Gradually expand serverless usage as you develop expertise and patterns.
How Companies Are Successfully Adopting Serverless
Real-world serverless adoption reveals patterns of success and common pitfalls. Companies that excel with serverless typically start small, learn from experience, and expand gradually. They invest in observability early, establishing logging, monitoring, and tracing before problems emerge.

Successful teams establish clear architectural principles early. They define standards for function size, dependency management, error handling, and logging. They implement CI/CD pipelines optimized for serverless deployment patterns. They create reusable patterns and libraries that accelerate development while maintaining consistency.
The most valuable lesson from successful serverless adoption is patience. Teams moving from traditional infrastructure need time to internalize serverless thinking. Initial productivity may actually decrease as developers learn new patterns and tools. However, teams that persist through the learning curve report dramatically improved velocity, reduced operational burden, and better alignment between infrastructure costs and business value.
FAQ
Q1.
Explore Services
Related Services
Reviewed by

Aman Vaths
Founder of Nadcab Labs
Aman Vaths is the Founder & CTO of Nadcab Labs, a global digital engineering company delivering enterprise-grade solutions across AI, Web3, Blockchain, Big Data, Cloud, Cybersecurity, and Modern Application Development. With deep technical leadership and product innovation experience, Aman has positioned Nadcab Labs as one of the most advanced engineering companies driving the next era of intelligent, secure, and scalable software systems. Under his leadership, Nadcab Labs has built 2,000+ global projects across sectors including fintech, banking, healthcare, real estate, logistics, gaming, manufacturing, and next-generation DePIN networks. Aman’s strength lies in architecting high-performance systems, end-to-end platform engineering, and designing enterprise solutions that operate at global scale.